自然語言處理的神經(jīng)網(wǎng)絡(luò)模型初探
深度學(xué)習(xí)(Deep Learning)技術(shù)對(duì)自然語言處理(NLP,Natural Language Processing)領(lǐng)域有著巨大的影響。
但作為初學(xué)者,您要從何處開始學(xué)習(xí)呢?
深度學(xué)習(xí)和自然語言處理都是較為廣闊的領(lǐng)域,但每個(gè)領(lǐng)域重點(diǎn)研究些什么?在自然語言處理領(lǐng)域中,又是哪一方面最受深度學(xué)習(xí)的影響呢?
通過閱讀本文,您會(huì)對(duì)自然語言處理中的深度學(xué)習(xí)有一個(gè)初步的認(rèn)識(shí)。
閱讀這篇文章后,您可以知道:
- 對(duì)自然語言處理領(lǐng)域影響最為深遠(yuǎn)的神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)。
- 綜觀那些可以通過深度學(xué)習(xí)成功解決的自然語言處理任務(wù)。
- 密集詞表示(Dense word representations)的重要性以及可以用于學(xué)習(xí)它們的方法。
現(xiàn)在,讓我們開始本次學(xué)習(xí)之旅。
自然語言處理的神經(jīng)網(wǎng)絡(luò)模型入門
圖片作者 faungg ,部分版權(quán)保留。
概覽
本文將遵循相關(guān)論文的結(jié)構(gòu)而分為 12 個(gè)部分,分別是:
- 關(guān)于論文(簡介)
- 神經(jīng)網(wǎng)絡(luò)架構(gòu)
- 特征表示
- 前饋神經(jīng)網(wǎng)絡(luò)
- 詞嵌入
- 訓(xùn)練神經(jīng)網(wǎng)絡(luò)
- 級(jí)聯(lián)和多任務(wù)學(xué)習(xí)
- 結(jié)構(gòu)化輸出預(yù)測
- 卷積層
- 循環(huán)神經(jīng)網(wǎng)絡(luò)
- 循環(huán)神經(jīng)網(wǎng)絡(luò)的具體架構(gòu)
- 樹型建模
我想給大家介紹一下本文的主要部分和風(fēng)格,以及高層次的話題介紹。
如果你想繼續(xù)深入研究,我強(qiáng)烈推薦閱讀全文或者一些最近出版的的書。
1.關(guān)于論文
論文的題目是:“A Primer on Neural Network Models for Natural Language Processing ” (自然語言處理的神經(jīng)網(wǎng)絡(luò)模型入門)。
這篇論文可以免費(fèi)在 ArXiv 上獲取,最新一次提交則是在 2015 年。它不只是一篇論文,更像是一篇技術(shù)報(bào)告或教程,并且文中還提供了針對(duì)學(xué)生與研究人員的,關(guān)于自然語言處理(NLP)中的深度學(xué)習(xí)方法的比較全面的介紹。
本教程從自然語言處理研究的角度對(duì)神經(jīng)網(wǎng)絡(luò)模型進(jìn)行了相關(guān)研究,力圖令自然語言領(lǐng)域的研究人員能跟上神經(jīng)網(wǎng)絡(luò)技術(shù)的發(fā)展速度。
這篇入門論文是由 NLP 領(lǐng)域研究員 Yoav Goldberg 撰寫的,他曾在 Google Research 擔(dān)任研究科學(xué)家。雖然 Yoav 最近引起了一些爭議,但我不會(huì)因此反對(duì)他。
這是一份技術(shù)報(bào)告,大概共有 62 頁,其中約有 13 頁是參考文獻(xiàn)列表。
這篇文章非常適合初學(xué)者,其原因有二:
- 它對(duì)于讀者的要求并不高,只需要您對(duì)這一主題有一定的興趣,并且了解少數(shù)關(guān)于機(jī)器學(xué)習(xí)與(或者)自然語言處理相關(guān)的知識(shí)即可。
- 它涵蓋了廣泛的深度學(xué)習(xí)方法和自然語言問題。
在本教程中,我嘗試給 NLP 從業(yè)人員(以及新人)提供基本的背景知識(shí),術(shù)語,工具和方法,使他們能夠理解神經(jīng)網(wǎng)絡(luò)模型背后的原理,并將其應(yīng)用到自己的工作中。 ... 本文的受眾,是那些有興趣使用現(xiàn)存的有用技術(shù),并以實(shí)用且富有創(chuàng)造性的方式將其應(yīng)用到他們最喜歡的 NLP 問題中的讀者。
通常,關(guān)鍵的深度學(xué)習(xí)方法通過語言學(xué)或自然語言處理的術(shù)語或命名法重新建立,這(在深度學(xué)習(xí)與自然語言處理之間)提供了一個(gè)有用的橋梁。
最后值得一提的是,這篇 2015 年的入門教程已在 2017 年出版,名為 “Neural Network Methods for Natural Language Processing” (自然語言處理中的神經(jīng)網(wǎng)絡(luò)方法)。

如果你喜歡這篇入門教程并且想深入研究,我強(qiáng)烈推薦您繼續(xù)閱讀 Yoav 的這本書。
2.神經(jīng)網(wǎng)絡(luò)架構(gòu)
本小節(jié)簡要介紹了各種不同類型的神經(jīng)網(wǎng)絡(luò)架構(gòu),在后面的章節(jié)中對(duì)它們進(jìn)行了一些交叉引用。
全連接(Fully connected)前饋神經(jīng)網(wǎng)絡(luò)是非線性學(xué)習(xí)器,在大多數(shù)情況下,它可以替換到使用了線性學(xué)習(xí)器的任何地方。
小節(jié)內(nèi)容涵蓋了四種神經(jīng)網(wǎng)絡(luò)架構(gòu),并重點(diǎn)介紹了各種應(yīng)用和引用的例子:
- 全連接前饋神經(jīng)網(wǎng)絡(luò),如多層感知器網(wǎng)絡(luò)(Multilayer Perceptron Networks)。
- 具有卷積和池化層(Pooling Layers)的網(wǎng)絡(luò),如卷積神經(jīng)網(wǎng)絡(luò)(Convolutional Neural Network)。
- 遞歸神經(jīng)網(wǎng)絡(luò)(Recurrent Neural Networks),如長短期記憶(LSTM,Long Short Term Memory)網(wǎng)絡(luò)。
- 循環(huán)神經(jīng)網(wǎng)絡(luò)(Recursive Neural Networks)。
如果您只對(duì)其中一種特定網(wǎng)絡(luò)類型的應(yīng)用感興趣,并想直接閱讀相關(guān)文獻(xiàn),本節(jié)則提供了一些很好的來源。
3.特征表示
本節(jié)重點(diǎn)介紹了如何將稀疏表示過渡轉(zhuǎn)化為密集表示,然后再運(yùn)用到深度學(xué)習(xí)模型訓(xùn)練中。
當(dāng)把輸入的稀疏線性模型轉(zhuǎn)變?yōu)榛谏窠?jīng)網(wǎng)絡(luò)的模型時(shí),最大的變化大概就是不再將每個(gè)特征表示為一個(gè)唯一的維度(所謂的單一表示 [One-hot Representation]),而是將它們表示為密集向量(Dense Vector)。
本節(jié)中介紹了 NLP 分類系統(tǒng)的一般結(jié)構(gòu),可總結(jié)如下:
- 提取一組核心語言特征。
- 為每個(gè)向量檢索對(duì)應(yīng)的向量。
- 組合成為特征向量。
- 將組合的矢量饋送到一個(gè)非線性分類器中。
這個(gè)公式的關(guān)鍵在于使用了密集特征向量而不是稀疏特征向量,并且用的是核心特征而非特征組合。
請(qǐng)注意,在神經(jīng)網(wǎng)絡(luò)設(shè)置中的特征提取階段,僅僅處理核心特征的提取。這與傳統(tǒng)的基于線性模型的 NLP 系統(tǒng)大相徑庭,因?yàn)樵谠撓到y(tǒng)中,特征設(shè)計(jì)者不僅必須手動(dòng)地指定感興趣的核心特征,而且還需要手動(dòng)指定它們之間的相互作用。
4.前饋神經(jīng)網(wǎng)絡(luò)
本節(jié)是前饋人工神經(jīng)網(wǎng)絡(luò)的速成課。
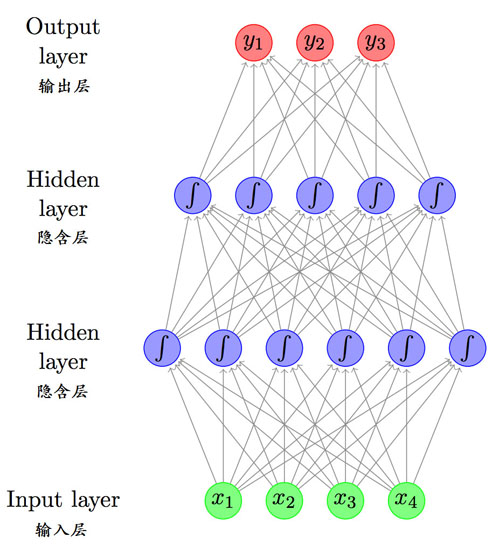
帶有兩個(gè)隱藏層的前饋神經(jīng)網(wǎng)絡(luò),摘自 “A Primer on Neural Network Models for Natural Language Processing”。
網(wǎng)絡(luò)是通過大腦啟發(fā)的隱喻與數(shù)學(xué)符號(hào)來呈現(xiàn)的。常見的神經(jīng)網(wǎng)絡(luò)主題包括如下幾種:
- 表示能力(例如通用逼近性 [Universal approximation])。
- 常見的非線性關(guān)系(例如傳遞函數(shù))。
- 輸出變換(例如 softmax)。
- 詞嵌入(例如內(nèi)置的學(xué)習(xí)密集表示)。
- 損失函數(shù)(如 Hinge-loss 和對(duì)數(shù)損失)。
5.詞嵌入
在自然語言處理中,詞嵌入表示(Word Embedding Representations)是神經(jīng)網(wǎng)絡(luò)方法的關(guān)鍵部分。本節(jié)則擴(kuò)展了這個(gè)主題,并列舉了一些關(guān)鍵的方法。
神經(jīng)網(wǎng)絡(luò)方法中的一個(gè)主要組成部分是使用嵌入 - 將每個(gè)特征表示為低維空間中的向量
本節(jié)中介紹了關(guān)于詞嵌入的以下幾個(gè)主題:
- 隨機(jī)初始化(例如,從統(tǒng)一的隨機(jī)向量開始訓(xùn)練)。
- 特定的有監(jiān)督任務(wù)的預(yù)訓(xùn)練(例如,遷移學(xué)習(xí) [Transfer Learning])。
- 無監(jiān)督任務(wù)的預(yù)訓(xùn)練(例如,word2vec 與 GloVe 之類的統(tǒng)計(jì)學(xué)方法)。
- 訓(xùn)練目標(biāo)(例如,目標(biāo)對(duì)結(jié)果向量的影響)。
- 上下文的選擇(例如,每個(gè)單詞受到附近的單詞的影響)。
神經(jīng)詞嵌入起源于語言建模領(lǐng)域,其中訓(xùn)練所得的網(wǎng)絡(luò)則用于基于先前詞的序列來預(yù)測下一個(gè)詞。
6.訓(xùn)練神經(jīng)網(wǎng)絡(luò)
這個(gè)較長的章節(jié)是為神經(jīng)網(wǎng)絡(luò)新手而寫的,它著重于訓(xùn)練神經(jīng)網(wǎng)絡(luò)的具體步驟。
神經(jīng)網(wǎng)絡(luò)的訓(xùn)練,是通過運(yùn)用基于梯度的方法將訓(xùn)練集上的損失函數(shù)最小化來完成的。
本節(jié)重點(diǎn)介紹隨機(jī)梯度下降法(還有相似的如 Mini-batch 這樣的方法)以及訓(xùn)練過程中的一些重要主題,比如說正則化。
有趣的是,本節(jié)還提供了神經(jīng)網(wǎng)絡(luò)的計(jì)算圖形透視圖,為諸如 Theano 和 TensorFlow 這樣的符號(hào)化數(shù)值計(jì)算庫提供了一個(gè)引子,而這些庫則是當(dāng)前流行的用于實(shí)現(xiàn)深度學(xué)習(xí)模型的基礎(chǔ)。
一旦圖形被構(gòu)建,就可以直接運(yùn)行正向計(jì)算(計(jì)算計(jì)算結(jié)果)或者反向計(jì)算(計(jì)算梯度)
7.級(jí)聯(lián)和多任務(wù)學(xué)習(xí)
在前一節(jié)的基礎(chǔ)上,本節(jié)總結(jié)了級(jí)聯(lián) NLP 模型和多語言任務(wù)學(xué)習(xí)模型的作用。
級(jí)聯(lián)模型(Model cascading):利用神經(jīng)網(wǎng)絡(luò)模型計(jì)算圖的定義來使用中間表示(編碼)開發(fā)更復(fù)雜的模型。
例如,我們可能有一個(gè)前饋網(wǎng)絡(luò),它用于根據(jù)詞的相鄰詞和(或)構(gòu)成它的字符來預(yù)測詞的詞性。
多任務(wù)學(xué)習(xí)(Multi-task learning):有一些相互關(guān)聯(lián)的自然語言預(yù)測任務(wù),它們不會(huì)相互影響,但它們各自的信息可以跨任務(wù)共享。
用于預(yù)測塊邊界、命名實(shí)體邊界和句子中的下一個(gè)單詞的信息,都依賴于一些共享的基礎(chǔ)句法語義表示
這兩個(gè)先進(jìn)的概念都是在神經(jīng)網(wǎng)絡(luò)的背景下描述的,它允許模型或信息在訓(xùn)練(誤差反向傳播)和預(yù)測期間具有連通性。
8.結(jié)構(gòu)化輸出預(yù)測
本節(jié)關(guān)注的是使用深度學(xué)習(xí)方法進(jìn)行結(jié)構(gòu)化預(yù)測的自然語言任務(wù),比如說序列、樹,以及圖。
典型的例子是序列標(biāo)記(例如詞性標(biāo)注 [Part-of-speech tagging]),序列分割(分塊,NER [Named-entity Recognition,命名實(shí)體識(shí)別])以及句法分析。
本部分涵蓋了基于貪心思想和基于搜索的結(jié)構(gòu)化預(yù)測,重點(diǎn)關(guān)注后者。
常用的自然語言結(jié)構(gòu)化預(yù)測方法,是基于搜索的方法。
9.卷積層
本節(jié)提供了卷積神經(jīng)網(wǎng)絡(luò)(CNN,Convolutional Neural Networks)的速成課程,以及闡述了這一網(wǎng)絡(luò)對(duì)自然語言領(lǐng)域的影響。
值得注意的是,當(dāng)下已經(jīng)證明了 CNN 對(duì)諸如情感分析(Sentiment analysis)這樣的分類 NLP 任務(wù)非常有效,例如學(xué)習(xí)尋找文本中的特定子序列或結(jié)構(gòu)以進(jìn)行預(yù)測。
卷積神經(jīng)網(wǎng)絡(luò)被設(shè)計(jì)來識(shí)別大型結(jié)構(gòu)中的指示性局部預(yù)測因子(Indicative local predictors),并且將它們組合起來以產(chǎn)生結(jié)構(gòu)的固定大小的向量表示,從而捕獲這些對(duì)于預(yù)測任務(wù)而言最具信息性的局部方面(Local aspects)。
10.循環(huán)神經(jīng)網(wǎng)絡(luò)
與前一節(jié)一樣,本節(jié)重點(diǎn)介紹了在 NLP 中所使用的特定網(wǎng)絡(luò)及其作用與應(yīng)用。在 NLP 中,遞歸神經(jīng)網(wǎng)絡(luò)(RNN,Recurrent Neural Networks)用于序列建模。
遞歸神經(jīng)網(wǎng)絡(luò)(RNN)允許在固定大小的向量中表示任意大小的結(jié)構(gòu)化輸入,同時(shí)也會(huì)注意輸入的結(jié)構(gòu)化屬性。
考慮到 RNN,特別是 NLP 中的長短期記憶(LSTM)的普及,這個(gè)較大的章節(jié)介紹了各種關(guān)于循環(huán)神經(jīng)網(wǎng)絡(luò)的主題與模型,其中包括:
- RNN 的抽象概念(例如網(wǎng)絡(luò)圖中的循環(huán)連接)。
- RNN 訓(xùn)練(例如通過時(shí)間進(jìn)行反向傳播)。
- 多層(堆疊)RNN(例如深度學(xué)習(xí)的 “深度” 部分)。
- BI-RNN(例如前向和反向序列作為輸入)。
- 用于表示的 RNN 堆疊。
我們將在 RNN 模型結(jié)構(gòu)或結(jié)構(gòu)元素上花費(fèi)一定的時(shí)間,特別是:
- 接受器(Acceptor):完整的序列輸入后,它計(jì)算輸出的損失。
- 編碼器(Encoder):最終向量用作輸入序列的編碼器。
- 轉(zhuǎn)換器(Transducer):為輸入序列中的每個(gè)觀測對(duì)象創(chuàng)建一個(gè)輸出。
- 編碼器 - 解碼器(Encoder-Decoder):輸入序列在被解碼為輸出序列之前,會(huì)編碼成為固定長度的向量。
11.循環(huán)神經(jīng)網(wǎng)絡(luò)的具體架構(gòu)
本章節(jié)基于上一節(jié)的內(nèi)容,介紹了具體的 RNN 算法。
具體包括如下幾點(diǎn):
- 簡單的 RNN(SRNN)。
- 長短期記憶(LSTM)。
- 門控循環(huán)單元(GRU,Gated Recurrent Unit)。
12.樹型建模
最后一節(jié)則重點(diǎn)關(guān)注一個(gè)更復(fù)雜的網(wǎng)絡(luò),我們稱為學(xué)習(xí)樹型建模的遞歸神經(jīng)網(wǎng)絡(luò)。
樹,可以是句法樹,話語樹,甚至是由一個(gè)句子中各個(gè)部分所表達(dá)的情緒的樹。我們希望基于特定的樹節(jié)點(diǎn)或基于根節(jié)點(diǎn)來預(yù)測值,或者為完整的樹或樹的一部分指定一個(gè)質(zhì)量值。
由于遞歸神經(jīng)網(wǎng)絡(luò)保留了輸入序列的狀態(tài),所以遞歸神經(jīng)網(wǎng)絡(luò)會(huì)維持樹中節(jié)點(diǎn)的狀態(tài)。
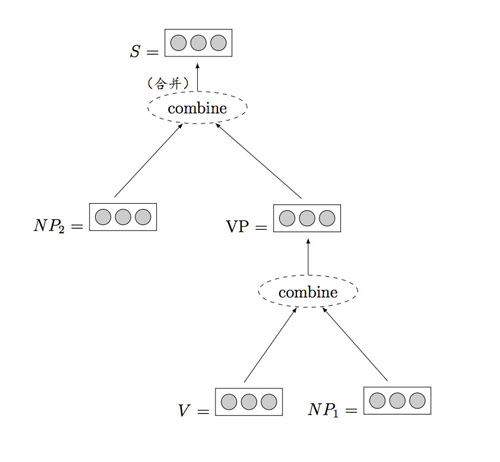
遞歸神經(jīng)網(wǎng)絡(luò)的例子,摘自 “A Primer on Neural Network Models for Natural Language Processing”。
擴(kuò)展閱讀
如果您正在深入研究,本節(jié)將提供更多有關(guān)該主題的資源。
A Primer on Neural Network Models for Natural Language Processing,2015 年發(fā)表。
Neural Network Methods for Natural Language Processing,2017 年出版。
總結(jié)
這篇文章介紹了一些關(guān)于自然語言處理中的深度學(xué)習(xí)的入門知識(shí)。
具體來說,你學(xué)到了:
- 對(duì)自然語言處理領(lǐng)域影響最大的神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)。
- 對(duì)可以通過深度學(xué)習(xí)算法成功解決的自然語言處理任務(wù)有一個(gè)廣泛的認(rèn)識(shí)。
- 密集表示以及相應(yīng)的學(xué)習(xí)方法的重要性。
原文鏈接:https://machinelearningmastery.com/primer-neural-network-models-natural-language-processing/
作者:Jason Brownlee
【本文是51CTO專欄作者“云加社區(qū)”的原創(chuàng)稿件,轉(zhuǎn)載請(qǐng)通過51CTO聯(lián)系原作者獲取授權(quán)】