入職第一天,MySQL就崩了...
圖片來自 Pexels
入職的第一天我就經歷了一次生產事故,運維同學告警說線上 MySQL 負載壓力大,直接就把主庫 MySQL 壓崩了(第一天這可不是好兆頭)。
運維同學緊急進行了主從切換,在事后尋找導致生產事故的原因時,排查到是慢查詢導致 MySQL 雪崩的主要原因。
在導出慢查詢的 SQL 后,項目經理直接說吧這個 MySQL 優化的功能交給新來的吧!
我趕緊打開跳板機進行查看,不看不知道一看嚇一跳:

單表的數據量已經達到了 5 億級別!這尼瑪肯定是歷史問題一直堆積到現在才導致的啊,項目經理直接就把這個坑甩給了我,我心中想,我難道試崗期都過不了么????
好在我身經百戰,趕快與項目經理與老同事進行溝通,了解業務場景,才發現導致現在的情況是這樣的。
我所在的公司是主要做 IM 社交系統的,這個 5 億級別的數據表是關注表,也是俗稱的粉絲表,在類似與某些大 V、或者是網紅,粉絲過百萬是非常常見的。
在 A 關注 B 后會產生一條記錄,B 關注 A 時也會產生一條記錄,時間積累久了才達到今天這樣的數據規模,項目經理慢悠悠的對我說,這個優化不用著急,先出方案吧!
我心中一萬個草泥馬經過,這上來就給了一塊不好啃的骨頭,看來是要試試我能力的深淺啊。
按照我之前經驗,單表在達到 500W 左右的數據就應該考慮分表了,常見分表方案無非就是 hash 取模,或者 range 分區這兩種方法。
但是這次的數據分表與遷移過程難度在于兩方面:
- 數據平滑過度,在不停機的情況把單表數據逐步遷移。(老板說:敢宕機分分鐘損失幾千塊,KPI 直接給你扣成負的)
- 數據分區,采用 hash 還是 range?(暫時不能使用一些分庫分表中間件,無奈)
首先說說 hash:
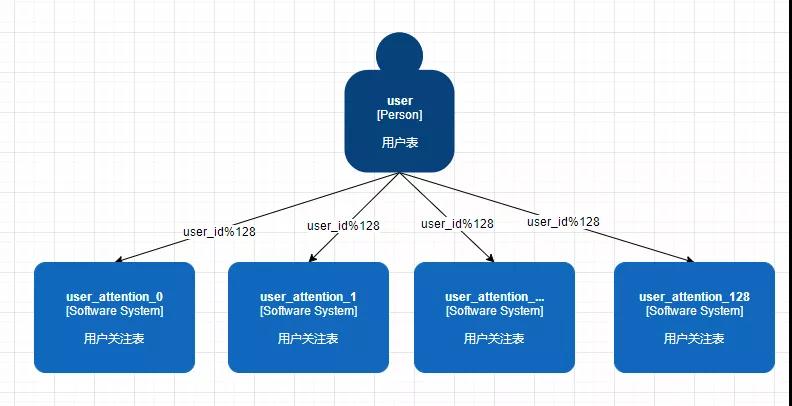
常規我們都是拿用戶 id 進行取模,模到多少直接把數據塞進去就行了,簡單粗暴。
但是假如說 user_id=128 與 user_id=257 再模 128 后都是對應 user_attention_1 這個表,他倆也恰好是網紅,旗下粉絲過百萬,那輕輕松松兩個人就能把數據表撐滿。
其他用戶再進來數據的時候無疑 user_attention_1 這個表還會成為一張大表,這就是典型的數據熱點問題,這個方案可以 PASS。
有的同學說可以 user_id 和 fans_id 組合進行取模進行分配,我也考慮過這個問題。
雖然這樣子數據分配均勻了,但是會有一個致命的問題就是查詢問題(因為目前沒有做類似 MongoDB 與 DB2 這種高性能查詢 DB,也沒做數據同步,考慮到工作量還是查詢現有的分表內的數據)。
例如業務場景經常用到的查詢就是我關注了那些人,那些人關注了我,所以我們的查詢代碼可能會是這樣寫的:
- //我關注了誰
- select * from user_attention where user_id = #{userId}
- //誰關注了我
- select * from user_attention where fans_id = #{userId}
在我們進行 user_id 與 fans_id 組合后 hash 后,如果我想查詢我關注的人與誰關注我的時候,那我將檢索 128 張表才能得到結果。
這個也太惡心了,肯定不可取,并且考慮到以后擴容至少也要影響一半數據,實在不好用,這個方案 PASS。
接下來說說 range:
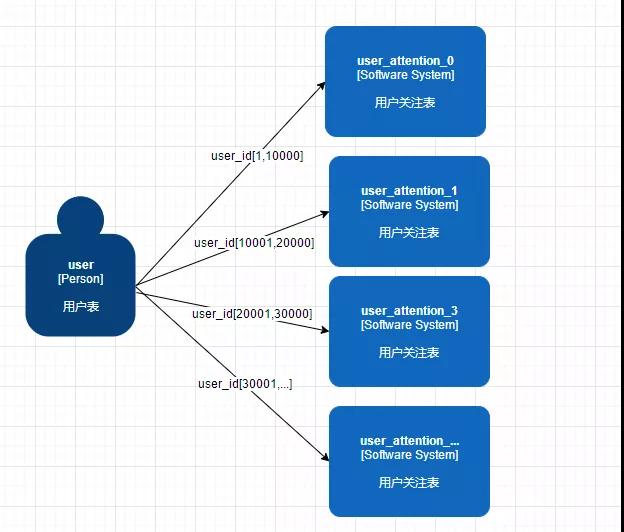
Range 看起來也很簡單,用戶 id 在一定的范圍時候就把他路由到一個表中。
例如用戶 id=128,那就在 [0,10000] 這個區間中對應的是 user_attention_0 這個表,就直接把數據塞進去就可以了。
但是這樣同樣也會產生熱點數據問題,看來簡單的水平分區已經不能滿足,這個方案也可以 PASS 了,還是要另尋他徑啊。
經過我日夜奮戰,深思熟慮之后,給出了三個解決方案:
第一種方案:range+一致性 hash 環組合(hash 環節點 10000)
什么是 hash 環看這里:
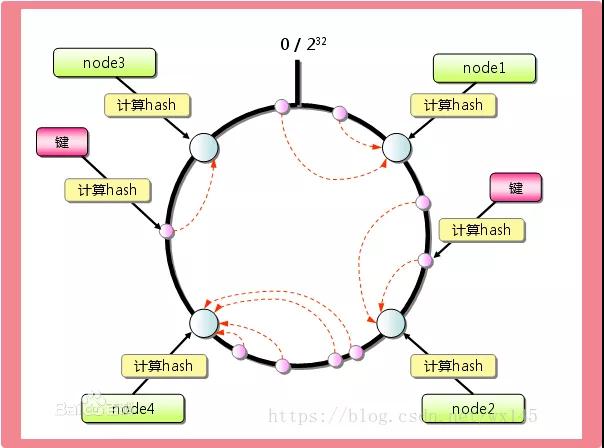
想采用這個方案主要是因為:
- 擴容簡單,影響范圍小,只涉及 hash 環上單個節點影響。
- 數據遷移簡單,每次擴容只需吧新增的節點與后置節點進行數據交互。
- 查詢范圍小,按照 range 與 hash 關系檢索部分表分區。
大概思路我們還是先按照 user_id 進行大概范圍劃分,但是 range 之后我后面對應的可能就不是一個表了,而是一個 hash 環。
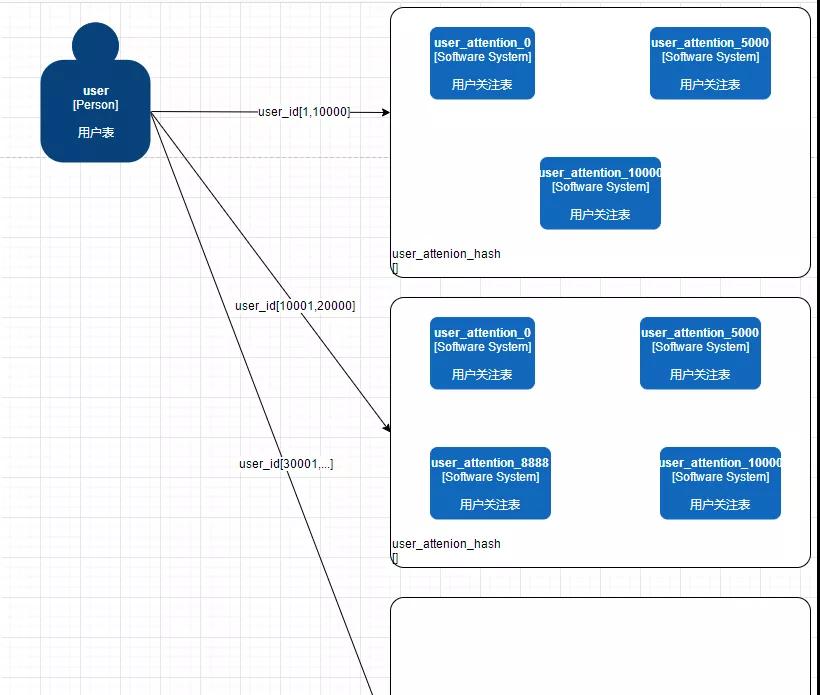
在每個 range 區域后都對應著自己一套的環,我們可以根據實際情況進行擴容,比如在 [1,10000] 這個范圍內只有 2 個大 V,那我們分三個表就夠了,預留 1500 萬的數據容量。
[10001,20000] 中有 4 個網紅和大 V,hash 環上就給出實際 4 張表,我們的用戶 id 可以順時針順序坐落到第一個物理表,數據進行入庫。
凡事有利有弊,方案也要結合工時,實際可行性與技術評審之后才能決定,弊端咱也要列出來:
- 設計復雜,需要增加 range 區域與 hash 環關系。
- 系統內修改波及較多,查詢關系復雜,多了一層路由表的概念,雖然盡量吧用戶數據分配到一個區之內,但是想查詢誰關注我,與我關注誰這樣的邏輯時還是復雜。
第二種方案:range+hash 取模(hash 模 300)
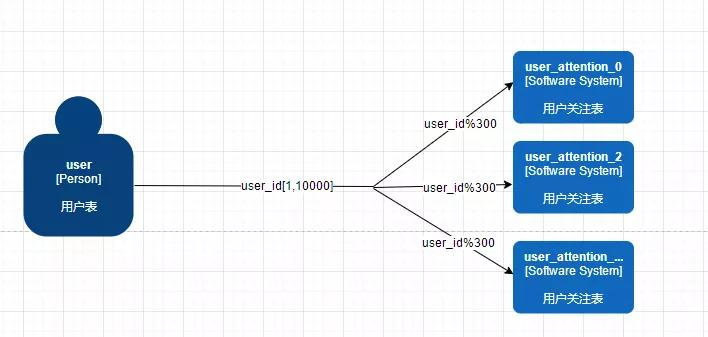
這個其實就比較好理解了,就是一個簡單的 range+hash 取模組合的形式,先 range 到一定的范圍后,在這個范圍內進行 hash 取模找到對應的表進行存儲。
這個方案比方案一簡單點,但是方案一存在的問題他也存在,并且他還有擴容數據影響范圍廣的問題。
但是實現起來就簡單不少,從查詢方面看根據不同場景可以控制取模的大小范圍,根據實際情況每個分區的 hash 模采用不同的值。
最后一種方案:range userId 分區
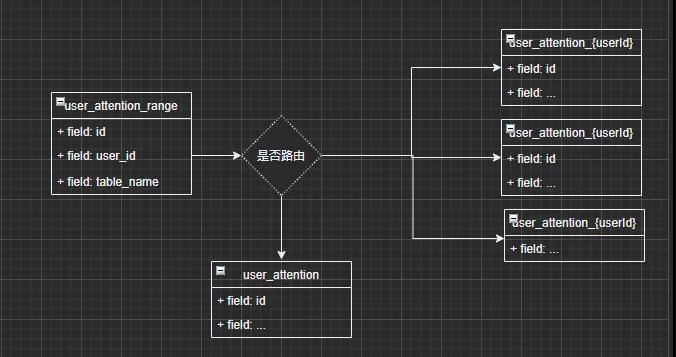
這個方案是我覺得靠譜性與實施性可能最高的一種,看起來挺像第二種方案的,但是更具體了一點,首先會定義一個中間關系表 user_attention_routing。

我們會把用戶范圍與路由到哪個表做成關系,根據范圍區間進行查找,結合現有數據當某個大 V,或者網紅數據量比較大,我們就給他路由自成一表數據大概是這樣的。

例如 user_id=256 是個大 V,就把他單獨提出來讓他自成一表,在查詢范圍的時候優先查是否有自己單獨對應的路由表。
而其他那些零碎用戶還是路由到一個統一表內,這時候有的同學會說這樣子數據不都又不均勻了么。
我也曾這樣認為,但是分到絕對的均勻基本不太可能,只能做到相對,盡量把某些大 V 分出去,不占用公共資源。
當某個人突然成為大 V 后,再把這個人再單獨分出去,不斷演變這個過程,保證數據的平衡。
并且這樣子處理之后很多原來的關聯查詢其實改動不大了,只要在數據遷移后對原來的所有包含 user_attention 進行動態的改造即可(使用個 mybatis 的攔截器就能搞定)。
PS:其實分析實際業務場景大部分的關注數據還是來源于那些零碎用戶的。
分表方案首先就這樣定了,接下來另一個問題就是查詢問題,上文說過很多業務查詢無非就是誰關注了我,我關注了誰這樣的場景,如果繼續使用之前的:
- //我關注了誰
- select * from user_attention where user_id = #{userId}
- //誰關注了我
- select * from user_attention where fans_id = #{userId}
這樣的方案,當我要查詢我的粉絲有哪些時,這樣就悲劇了,我還是要檢索全表根據 fansid 找到我所有的粉絲,因為表內只記錄了我關注了誰這樣的數據。
考慮到這樣的問題,我決定重新設計數據存儲形式,使用空間換時間的思路,原來處理的方式是用戶在關注對方的時候產生一條記錄。
現在處理方式是用戶 A 在關注用戶 B 時寫入兩條數據,通過字段區分關系,假如 user_attention 表是這樣的:

在用戶 1 關注 2 后產生兩條數據,state(1 代表我關注了,0 代表我被關注了,2 代表咱倆互關),采用這樣的數據存儲方式后,我所有的查詢都可以從 user_id 進行出發了,不在逆向去推 fans_id 這樣的方式。
數據庫索引設計上,考慮好 user_id、fans_id、state 與 user_id、state 這樣的結構即可,是不是感覺很簡單,雖然數據量存儲變多了,但是查詢方便了好多。
分表和查詢問題解決了,最后就是要考慮數據遷移的過程了,這一步也非常重要。搞不好就要被扣掉自己的 KPI 了(步步為營啊)!
數據遷移最需要考慮的問題就是個時效性,遷移程序必不可少,如何生產環境正常跑著,遷移腳本線下跑著數據互不影響呢?
答案就是經典套路數據雙寫,因為老的數據不是一下子就遷移到新表內的,現在和 user_attention 產生的數據還是要保持的,在產生老表數據的同時,根據路由規則,直接存到新表內一份。
線下的遷移程序多開幾臺服務慢慢跑唄,不過可要控制好數據量,別占滿 IO 影響生產環境,線下的模擬和演練也是必不可少的,誰都不能保證會不會出啥問題呢。
遷移腳本和線上做好 user_id 和 fans_id 的唯一索引就行,在某些極端情況下,數據會存在新表內寫入數據,但是老表內數據還沒更新的可能這個做好版本號控制和日志記錄就可以了,這些都比較簡單。
當新表數據和老表完全同步時我們就可以吧所有系統內波及老表查詢的語句都改成新表查詢,驗證下有沒有問題,如果沒有問題最后就可以痛快的!
- truncate table user_attention;
干掉這個 5 億數據量的定時炸彈了。好了,今天分享就結束了,看來我不僅能挺過試崗期也能挺過試用期了,不說了下班回家抱娃去了??。
作者:TOM,一個二線城市的程序員
編輯:陶家龍
出處:轉載自公眾號 JavaTom