













新年上班第一天生產環境分布式文件系統崩了!
作者個人研發的在高并發場景下,提供的簡單、穩定、可擴展的延遲消息隊列框架,具有精準的定時任務和延遲隊列處理功能。自開源半年多以來,已成功為十幾家中小型企業提供了精準定時調度方案,經受住了生產環境的考驗。為使更多童鞋受益,現給出開源框架地址:
https://github.com/sunshinelyz/mykit-delay
寫在前面
說來也怪,早不崩晚不崩,偏偏在上班第一天的時候,生產環境分布式文件系統崩了。我才剛來到我的工位坐下,“叮鈴鈴”電話響了,是運營打來的,“喂,冰河,快點看看,生產環境的圖片和視頻都無法上傳了,系統崩潰了,快點看看啊!”。你說我一個不是做運維的,直接打來電話讓我看生產環境的事故?原來是運維那哥們還沒上班,額,好吧,我接受了,于是我迅速整理好工位,擺出電腦,登錄服務器,一頓操作猛如虎,10分鐘搞定了,剩下的就是異步復制圖片和視頻了。
今天,就和小伙伴們分享下,這次生產環境分布式文件系統出現的問題,以及我是如何10分鐘排查問題和解決問題的。另外,本文不是基于生產環境事故寫的,而是事后,我在我本機虛擬機上模擬的環境。解決問題的思路和方法都是一樣的。
額,估計運維要被3.25了!!
文章已收錄到:
https://github.com/sunshinelyz/technology-binghe
https://gitee.com/binghe001/technology-binghe
問題定位
通過登錄服務器查看系統的訪問日志,發現日志文件中輸出了如下異常信息。
- org.csource.common.MyException: getStoreStorage fail, errno code: 28
- at org.csource.fastdfs.StorageClient.newWritableStorageConnection(StorageClient.java:1629)
- at org.csource.fastdfs.StorageClient.do_upload_file(StorageClient.java:639)
- at org.csource.fastdfs.StorageClient.upload_file(StorageClient.java:162)
- at org.csource.fastdfs.StorageClient.upload_file(StorageClient.java:180)
很明顯,是系統無法上傳文件導致的問題,這個日志信息很重要,對問題的排查起到了至關重要的作用。
分析原因
既然是上傳文件出現了問題,那我先試試能不能訪問以前上傳的文件呢?經過驗證,以前上傳的文件是可以訪問的,再次驗證了是上傳文件的問題。
既然生產環境是使用的分布式文件系統,一般情況下是沒啥問題的,上傳文件出現了問題,大概率的事件是服務器磁盤空間不足了。那我就來順著這個思路排查下問題。
于是乎,我使用df -h 查看服務器的存儲空間使用率,已經達到91%了。
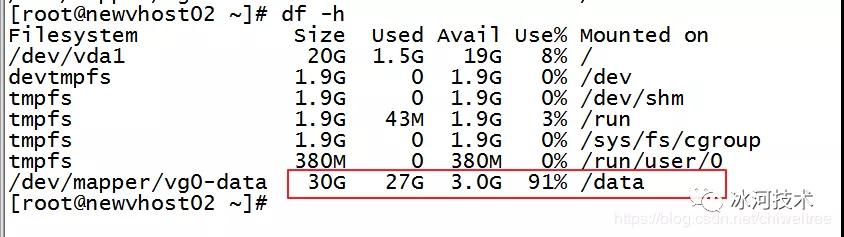
嗯,磁盤空間有可能是引起問題的原因。接下來,再來進一步確認下是否是磁盤空間造成的問題。
于是,我再打開/etc/fdfs/目錄下的tracker.conf的配置,看到預留的存儲空間為10%(注:這里的分布式文件系統使用的是FastDFS)。
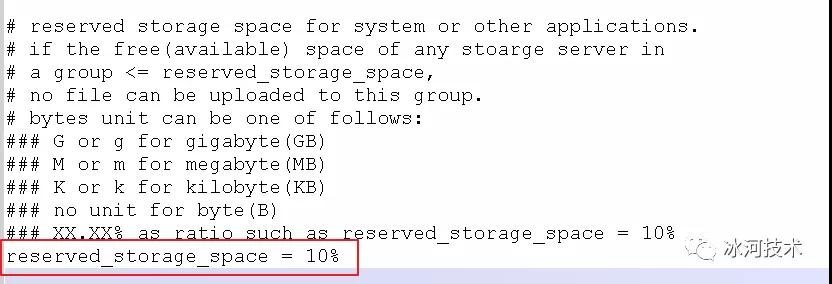
看到這里,可以確定就是磁盤空間不足造成的無法上傳文件的問題。
總體原因就是:服務器磁盤空間已使用91%,而在分布式文件系統的配置中預留的磁盤空間為10%,實際在上傳文件的時候,系統已經檢測到當前服務器剩余的磁盤空間不足10%,拋出異常,拒絕上傳文件。
到此,問題出現的原因已經確定了,接下來就是要解決問題了。
解決問題
首先,有兩種方式可以解決這個問題,一種就是刪除不需要的文件;另一種就是擴容磁盤空間。
刪除不需要的文件
這種方式慎用,這里,我也簡單的介紹下這種方式。我給小伙伴們提供了幾種遞歸刪除的方式。
遞歸刪除.pyc格式的文件。
- find . -name '*.pyc' -exec rm -rf {} \;
打印當前文件夾下指定大小的文件
- find . -name "*" -size 145800c -print
遞歸刪除指定大小的文件(145800)
- find . -name "*" -size 145800c -exec rm -rf {} \;
遞歸刪除指定大小的文件,并打印出來
- find . -name "*" -size 145800c -print -exec rm -rf {} \;
下面是對上述命令的一些簡要說明。
- "." 表示從當前目錄開始遞歸查找
- “ -name '*.exe' "根據名稱來查找,要查找所有以.exe結尾的文件夾或者文件
- " -type f "查找的類型為文件
- "-print" 輸出查找的文件目錄名
- -size 145800c 指定文件的大小
- -exec rm -rf {} \; 遞歸刪除(前面查詢出來的結果)
擴容磁盤空間
這里,冰河推薦使用這種方式,我修復生產環境的故障也是使用的這種方式。
通過查看服務器的磁盤空間發現,/data目錄下的空間足足有5TB,呵呵,運維哥們為啥不把文件系統的數據存儲目錄指向/data目錄呢。于是乎,我開始將文件系統的數據存儲目錄遷移到/data目錄下,整個過程如下所示。
注意:這里,我就簡單的模擬將 /opt/fastdfs_storage_data下的數據遷移至/data下。
(1)拷貝文件,遷移數據
- cp -r /opt/fastdfs_storage_data /data
- cp -r /opt/fastdfs_storage /data
- cp -r /opt/fastdfs_tracker /data
(2)修改路徑
這里需要修改文件系統的 /etc/fdfs/storage.conf ,mod_fastdfs.conf ,client.conf,tracker.conf文件。
- /etc/fdfs/storage.conf
- store_path0=/data/fastdfs_storage_data
- base_path=/data/fastdfs_storage
- /etc/fdfs/mod_fastdfs.conf
- store_path0=/data/fastdfs_storage_data (有兩處)
- base_path=/data/fastdfs_storage
- /etc/fdfs/client.conf
- base_path=/data/fastdfs_tracker
- /etc/fdfs/tracker.conf
- base_path=/data/fastdfs_tracker
重新建立 M00 至存儲目錄的符號連接:ln -s /data/fastdfs_storage_data/data /data/fastdfs_storage_data/data/M00
(3)殺掉進程, 重啟存儲服務 (追蹤器和存儲器)
依次執行以下命令
- pkill -9 fdfs
- service fdfs_trackerd start
- service fdfs_storaged start
(4)修改文件的讀取路徑 nginx配置
- location ~/group1/M00{
- root /data/fastdfs_storage_data/data;
- }
(5)重啟nginx
- cd /opt/nginx/sbin
- ./nginx -s reload
好了,問題搞定,運營可以正常上傳圖片和視頻了。
本文轉載自微信公眾號「 冰河技術」,可以通過以下二維碼關注。轉載本文請聯系 冰河技術公眾號。













