Transformer在計算機視覺領域走到哪了?
Transformer 模型在自然語言處理(NLP)領域已然成為一個新范式,如今越來越多的研究在嘗試將 Transformer 模型強大的建模能力應用到計算機視覺(CV)領域。那么未來,Transformer 會不會如同在 NLP 領域的應用一樣革新 CV 領域?今后的研究思路又有哪些?微軟亞洲研究院多媒體搜索與挖掘組的研究員們基于 Vision Transformer 模型在圖像和視頻理解領域的最新工作,可能會帶給你一些新的理解。
作為一個由自注意力機制組成的網絡結構,Transformer一“出場”就以強大的縮放性、學習長距離的依賴等優勢,替代卷積神經網絡(CNN)、循環神經網絡(RNN)等網絡結構,“席卷”了自然語言處理(NLP)領域的理解、生成任務。
然而,Transformer 并未止步于此,2020年,Transformer 模型首次被應用到了圖像分類任務中并得到了比 CNN 模型更好的結果。此后,不少研究都開始嘗試將 Transformer 模型強大的建模能力應用到計算機視覺領域。目前,Transformer 已經在三大圖像問題上——分類、檢測和分割,都取得了不錯的效果。視覺與語言預訓練、圖像超分、視頻修復和視頻目標追蹤等任務也正在成為 Transformer “跨界”的熱門方向,在 Transformer 結構基礎上進行應用和設計,也都取得了不錯的成績。
Transformer“跨界”圖像任務
最近幾年,隨著基于 Transformer 的預訓練模型在 NLP 領域不斷展現出驚人的能力,越來越多的工作將 Transformer 引入到了圖像以及相關的跨模態領域,Transformer 的自注意力機制以其領域無關性和高效的計算,極大地推動了圖像相關任務的發展。
端到端的視覺和語言跨模態預訓練模型
視覺-語言預訓練任務屬于圖像領域,其目標是利用大規模圖片和語言對應的數據集,通過設計預訓練任務學習更加魯棒且具有代表性的跨模態特征,從而提高下游視覺-語言任務的性能。
現有的視覺-語言預訓練工作大都沿用傳統視覺-語言任務的視覺特征表示,即基于目標檢測網絡離線抽取的區域視覺特征,將研究重點放到了視覺-語言(vision-language,VL)的特征融合以及預訓練上,卻忽略了視覺特征的優化對于跨模態模型的重要性。這種傳統的視覺特征對于 VL 任務的學習主要有兩點問題:
1)視覺特征受限于原本視覺檢測任務的目標類別
2)忽略了非目標區域中對于上下文理解的重要信息
為了在VL模型中優化視覺特征,微軟亞洲研究院多媒體搜索與挖掘組的研究員們 提出了一種端到端的 VL 預訓練網絡 SOHO ,為 VL 訓練模型提供了一條全新的探索路徑。 該工作的相關論文“Seeing Out of tHe bOx: End-to-End Pre-training for Vision-Language Representation Learning”已收錄于CVPR 2021 Oral。
論文鏈接: https://arxiv.org/abs/2104.03135
GitHub地址: https://github.com/researchmm/soho

SOHO 模型的主要思路是: 將視覺編碼器整合到 VL 的訓練網絡中,依靠 VL 預訓練任務優化整個網絡,從而簡化訓練流程,緩解依賴人工標注數據的問題,同時使得視覺編碼器能夠在 VL 預訓練任務的指導下在線更新,提供更好的視覺表征。
經驗證, SOHO 模型不僅降低了對人工標注數據的需求,而且在下游多個視覺-語言任務(包括視覺問答、圖片語言檢索、自然語言圖像推理等)的公平比較下,都取得了 SOTA 的成績 。
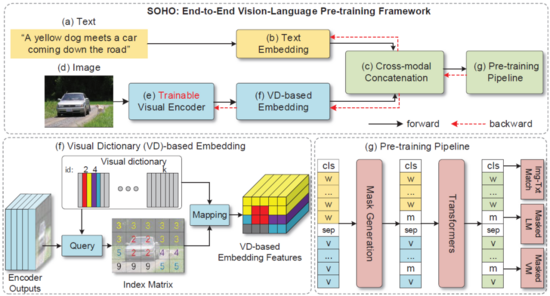
圖1:端到端的視覺語言預訓練網絡 SOHO
如圖1所示,SOHO 由三部分組成:1)基于卷積網絡的視覺編碼器(可在線更新);2)基于視覺字典(Visual Dictionary)的視覺嵌入層;3)由多層 Transformer 組成的 VL 融合網絡。三個部分“各司其職”,卷積網絡負責將一張圖像表征為一組向量,然后利用視覺字典對圖像中相近的特征向量進行表征,最后利用 Transformer 組成的網絡將基于字典嵌入的視覺特征與文本特征融合到一起。
對于視覺編碼器,研究員們采用了 ResNet-101 作為基礎網絡結構對輸入圖像進行編碼,與基于目標檢測模型的圖像編碼器相比,這種方式的好處是:可以簡化操作。為了將圖像中相近的特征用統一的特征表征,同時為 MVM(Masked vision Modeling)提供類別標簽,研究員們利用了視覺字典。整個字典在網絡學習的過程中都采用了動量更新的方式進行學習。基于 Transform 的特征融合網絡則采用了和 BERT 相同的網絡結構。
為了優化整個網絡,研究員們利用 MVM、MLM(Masked Language Modeling) 以及 ITM(Image-Text Matching) 三個預訓練任務進行了模型訓練,并將得到的參數應用到了四個相關的 VL 下游任務上,均取得了較好的結果(如表格1-4所示)。

表格1:SOHO 在 MSCOCO 數據集上與其他方法的 text retrieval(TR)和 image retrieval(IR)的性能比較
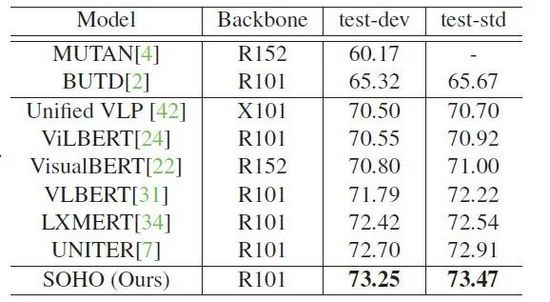
表格2:SOHO 在 VQA 2.0 數據集上的 VQA 性能表現
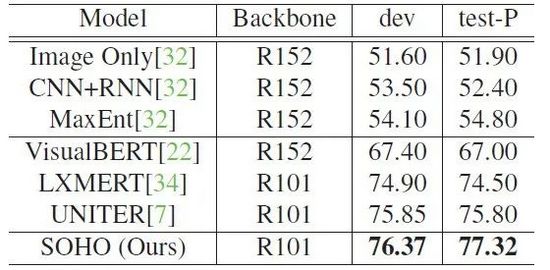
表格3:SOHO 在 NLVR2 數據集上的 Visual Reasoning 性能表現
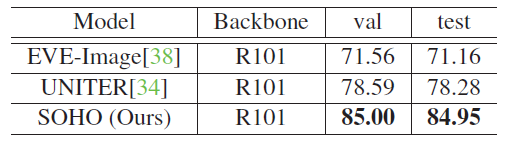
表 格4: SOHO 在 SNLI-VE 數據集上的 Visual Entailment 性能表現
最后,通過對視覺字典中部分 ID 對應的圖片內容進行可視化(如圖2所示),研究員們發現即使沒有強監督的視覺類別標注,SOHO 也可以將具有相似語義的視覺內容聚類到同一個字典項中。相對于使用基于目標檢測的視覺語言模型,SOHO 擺脫了圖片框的回歸需求,推理時間(inference time)也加快了10倍,在真實場景應用中更加實際和便捷。

圖2:Visual Dictionary 部分 ID 對應圖片內容的可視化
基于紋理 Transformer 模型的圖像超分辯率技術
從古老的膠片照相機到今天的數碼時代,人類拍攝和保存了大量的圖片信息,但這些圖片不可避免地存在各種不同程度的瑕疵。將圖片變得更清晰、更鮮活,一直是計算機視覺領域的重要話題。針對于圖像超分辨率的問題,微軟亞洲研究院的研究員們創新性地將 Transformer 結構應用在了圖像生成領域,提出了一種 基于紋理 Transformer 模型的圖像超分辯率方法 TTSR 。
該模型可以有效地搜索與遷移高清的紋理信息,最大程度地利用參考圖像的信息,并可以正確地將高清紋理遷移到生成的超分辨率結果當中,從而解決了紋理模糊和紋理失真的問題。 該工作“Learning Texture Transformer Network for Image Super-Resolution”發表在 CVPR 2020。
論文鏈接: https://arxiv.org/pdf/2006.04139.pdf
GitHub地址: https://github.com/researchmm/TTSR

與先前盲猜圖片細節的方法不同,研究員們通過引入一張高分辨率參考圖像來指引整個超分辨率過程。高分辨率參考圖像的引入,將圖像超分辨率問題由較為困難的紋理恢復/生成轉化為了相對簡單的紋理搜索與遷移,使得超分辨率結果在指標以及視覺效果上有了顯著的提升。如圖3所示,TTSR 模型包括:可學習的紋理提取器模塊(Learnable Texture Extractor)、相關性嵌入模塊(Relevance Embedding)、硬注意力模塊(Hard Attention)、軟注意力模塊(Soft Attention)。
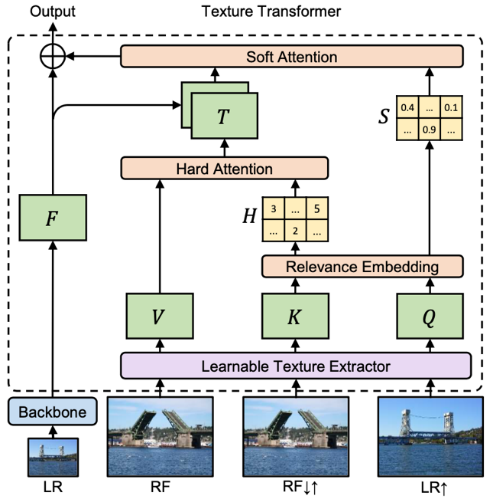
圖3:紋理 Transformer 模型
傳統 Transformer 通過堆疊使得模型具有更強的表達能力,然而在圖像生成問題中,簡單的堆疊很難產生很好的效果。為了進一步提升模型對參考圖像信息的提取和利用,研究員們提出了 跨層級的特征融合機制 ——將所提出的紋理 Transformer 應用于 x1、x2、x4 三個不同的層級,并將不同層級間的特征通過上采樣或帶步長的卷積進行交叉融合。因此,不同粒度的參考圖像信息會滲透到不同的層級,使得網絡的特征表達能力增強,提高生成圖像的質量。
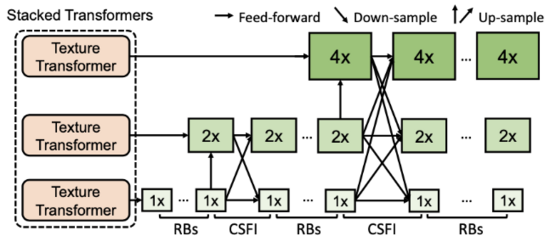
圖4:多個紋理 Transformer 跨層級堆疊模型
研究員們在 CUFED5、Sun80、Urban100、Manga109 數據集上針對 TTSR 方法進行了量化比較,具體如表格5所示。圖5展示了 TTSR 與現有的方法在不同數據集上的視覺比較結果,可以發現 TTSR 顯著領先于其他方法的結果。
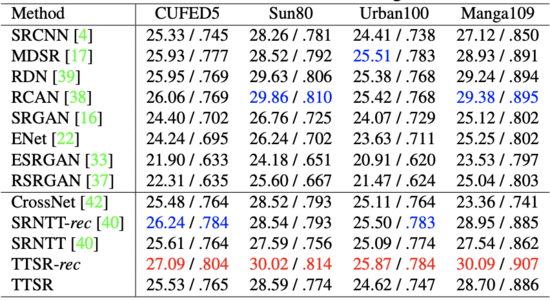
表格5:TTSR 與現有方法在不同數據集上的量化比較結果

圖5: TTSR 與現有方法在不同數據集上的視覺比較結果
Transformer“跨界”視頻任務
相對于圖像的空間信息,視頻還增加了時序維度的信息。 Transformer 可以很好地在空間-時序維度上進行建模,進而更好地學習圖像與特征中的長距離依賴關系,有利于視頻相關任務的增強與提高。
視頻修復:Transformer 初嘗試
視頻修復(video inpainting)是一個旨在通過視頻中已知內容來推斷并填補缺失內容的經典任務。它在老舊視頻恢復、去除水印等視頻編輯中有著廣泛應用。盡管視頻修復技術有很大的應用價值,然而在復雜變化的多個視頻幀中找到相關信息,并生成在圖像空間和時序上看起來和諧、一致的內容,仍然面臨著巨大的挑戰。
為了解決這樣的問題,微軟亞洲研究院的研究員們利用并重新設計了Transformer結構,提出了 Spatial-Temporal Transformer Network (STTN)。 相關論文“Learning Joint Spatial-Temporal Transformations for Video Inpainting”發表在了 ECCV 2020。
論文鏈接: https://arxiv.org/abs/2007.10247
GitHub地址: https://github.com/researchmm/STTN

STTN 模型的輸入是帶有缺失內容的視頻幀以及每一幀的掩碼,輸出則是對應的修復好的視頻幀。如圖6所示,STTN 模型的輸入是帶有缺失內容的視頻幀以及每一幀的掩碼,輸出則是對應的修復好的視頻幀。如圖6所示,STTN 模型采用了 CNN-Transformer 的混合結構。其中,frame-level encoder 以及 frame-level decoder 采用了 CNN,分別將每個視頻幀從像素編碼成特征以及將特征解碼成視頻幀。Transformer 則作為模型的主干,它將輸入的視頻幀特征切成塊,并對塊的序列進行建模,再通過多層時空 Transformer 層挖掘輸入幀中的已知信息來推斷缺失內容。
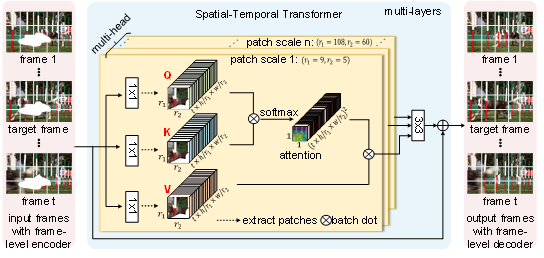
圖6: Spatial-Temporal Transformer Network (STTN) 模型結構示意圖
時空 Transformer 層繼承了經典 Transformer 層強大的注意力機制,能聚焦于與缺失內容相關的信息上,通過多層的堆疊不斷更新優化預測的內容。 同時,不同于經典 Transformer 層中每個頭部的是模型采用了固定的塊大小,STTN 為了捕捉到盡可能多的上下文信息,在不同的頭部上采用了不同大小的塊切取方式。 因此,當缺失區域的特征不夠豐富時,基于大的塊的注意力機制可以有效利用較多的已知信息; 當缺失區域的特征豐富之后,基于小的塊的注意力機制有助于模型聚焦更細微的變化。 如圖7所示,通過可視化 STTN 最后一層 Transformer 的注意力圖,可以發現 STTN 為了填補目標幀中狗身上的缺失區域,能夠 “精準追蹤” 到其他幀里的信息,來修復缺失區域。
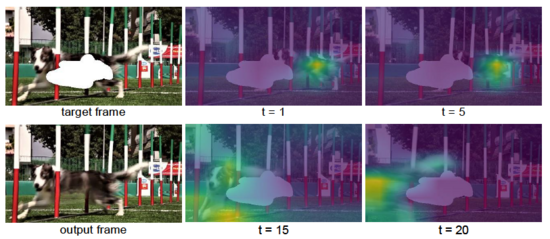
圖7:Attention map 的可視化(attention 的部分用黃色高亮)。盡管視頻里狗由于奔跑,在不同的幀里形態和位置差異較大,但為了填補目標幀(target frame)中狗身上缺失的部分,STTN 可以 “精準追蹤” 到相關的幀里這只跑動的狗。
除了 STTN 模型,該論文還提出了用動態和靜態兩種不同的視頻掩碼來模擬實際應用。 動態掩碼指視頻每一幀的掩碼是連續變化的,用來模擬移除運動物體的應用; 而靜態掩碼不會隨著視頻變化,用來模擬水印移除。 論文通過在 DAVIS 和 Youtube-VOS 數據集上定性和定量的分析,驗證了 STTN 在視頻修復任務上的優越性。 如視頻1所示,STTN 能夠生成視覺上更真實的修復結果。 同時得益于 STTN 強大的并行建模能力,它也加快了運行速度(24.10 fps VS. 3.84 fps)。
目標跟蹤新范式:基于時空 Transformer
視頻目標跟蹤(Visual Object Tracking)是計算機視覺領域中的一項基礎且頗具挑戰性的任務。在過去幾年中,基于卷積神經網絡,目標跟蹤迎來了快速的發展。然而卷積神經網絡并不擅長建模圖像與特征中的長距離依賴關系,同時現有的目標跟蹤器或是僅利用了空間信息,亦或是并未考慮到時間與空間之間的聯系,造成跟蹤器在復雜場景下性能的下降。
如何解決以上問題?微軟亞洲研究院的研究員們 提出了一種名為 STARK 的基于時空 Transformer 的目標跟蹤器新范式 ,將目標跟蹤建模為一種端到端的邊界框預測問題,從而徹底擺脫以往跟蹤器使用的超參敏感的后處理,該方法在多個短時與長時跟蹤數據集上都取得了當前最優的性能。
相關論文“Learning Spatio-Temporal Transformer for Visual Tracking”
鏈接: https://arxiv.org/abs/2103.17154
GitHub地址: https://github.com/researchmm/stark

STARK 包括 Spatial-Only 和 Spatio-Temporal 兩個版本,其中 Spatial-Only 版本僅使用空間信息,Spatio-Temporal 版本則同時利用了時間和空間信息。
Spatial-Only 版本的框架圖如圖8所示。首先,第一幀的模板和當前幀的搜索區域會一同送入骨干網絡提取視覺特征,然后特征圖沿空間維度展開并拼接,進而得到一個特征序列。之后,Transformer 編碼器會建模序列元素之間的全局關聯,并利用學習到的全局信息來強化原始特征,使得新的特征序列對目標具有更強的判別力。受 DETR 的啟發,研究員們使用了一個解碼器以及一個目標查詢(Target Query)來對編碼器的輸出進行譯碼。目標查詢與前面提到的編碼器輸出的特征序列進行交互,從而學習到和目標相關的重要信息。最后,編碼器輸出的特征序列以及譯碼器輸出的新的目標查詢特征再一同送入邊界框預測模塊,得到最終的邊界框坐標。
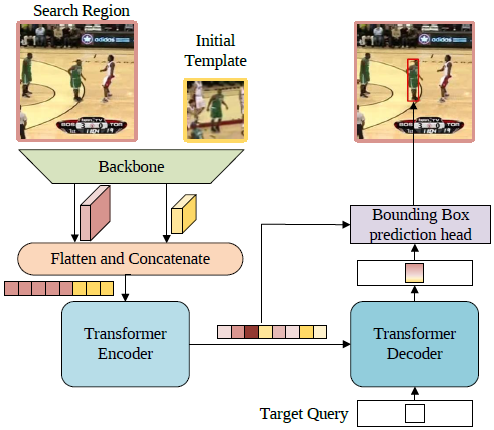
圖8:Spatial-Only 版本的框架圖
邊界框預測模塊的結構如圖9所示,首先從編碼器的輸出序列中取出搜索區域相關的特征,用該特征序列與譯碼器輸出的目標查詢特征計算一次注意力機制,強化目標所在區域的特征,削弱非目標區域的特征。然后,經注意力機制強化后的搜索區域特征序列的空間結構被還原,并通過簡單的全卷積網絡預測目標左上角和右下角一對角點(corners)的熱力圖,最終的角點坐標則通過計算角點坐標的數學期望得到。不同于之前的Siamese和DCF方法,該框架將目標跟蹤建模為一個直接的邊界框預測問題,每一幀上都可直接預測一個邊界框坐標,無需使用任何超參敏感的后處理。
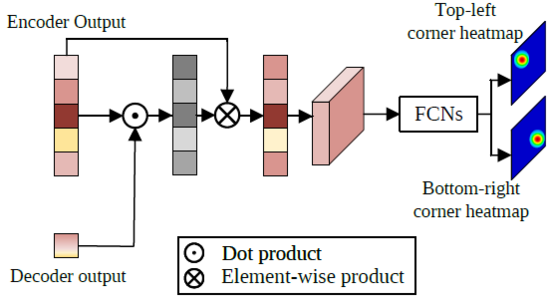
圖9:邊界框預測模塊的結構
Spatio-Temporal 版本的框架圖如圖10所示,粉色區域展示了為了利用時序信息而新加入的結構。新框架額外加入了一個 “動態模板” 作為新輸入。動態模板是根據中間幀跟蹤結果裁剪得到的,并隨著跟蹤的進行動態更新,為整個框架補充了之前缺少的時序信息。利用第一幀模板、當前幀搜索區域、動態模板同時作為 Transformer 編碼器的輸入,編碼器能夠從全局視角提取時空信息,學習到魯棒的時空聯合表示。除動態模板之外,研究員們還引入了由多層感知機實現的更新控制器來更新動態模板,它與邊界框預測頭并聯,以預測當前幀可靠程度的置信度分數。
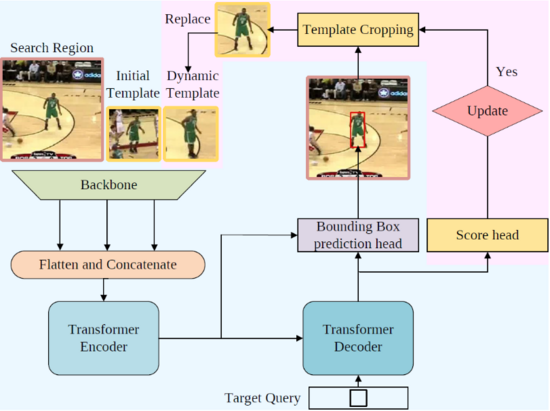
圖10:Spatio-Temporal 版本框架圖
STARK 在多個短時跟蹤與長時跟蹤數據集上都取得了目前最先進的性能,并且運行速度可達 30FPS 到 40FPS。其中,在 LaSOT, GOT-10K, TrackingNet 三個大規模目標跟蹤數據集上的結果如下所示。
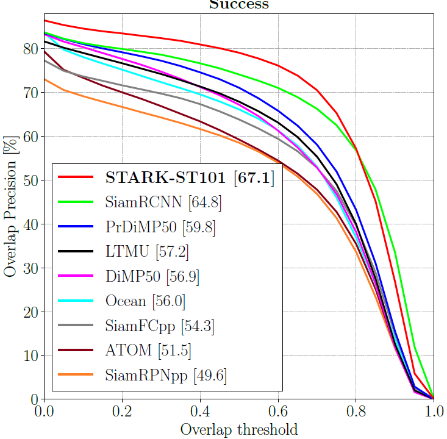
圖11:LaSOT 數據集上的結果比較

表格6:GOT-10K 數據集上的結果比較

表格7:TrackingNet 數據集上的結果比較
上述四個工作將 Transformer 結構成功地應用于圖像內容增強和視頻內容分析, 充分地展現了 Transformer 的優勢和潛力。目前研究員們已經看到,無論是在圖像分類、物體檢測與分割等基礎視覺任務上,還是在 3D 點云分析、圖像視頻內容生成等新興課題中,Transformer 都大放異彩。未來,視覺 Transformer 結構的設計和自動化搜索將會是一個非常具有前景的研究課題。相信 Transformer 結構在計算機視覺領域會繼續展現其強大的模型潛力。