全面加速醫療AI創新研究 騰訊天衍實驗室多項成果入選國際頂會
近日,自然語言處理(NLP)領域的頂級會議ACL 2021(Annual Meeting of the Association for Computational Linguistics)和人工智能領域的頂級會議IJCAI 2021(International Joint Conference on Artificial Intelligence)相繼揭曉論文錄用結果,專注醫療人工智能與大數據技術研究的騰訊天衍實驗室共有3篇長文被ACL 2021主會錄用,1篇長文被Findings of ACL錄用,1篇長文被IJCAI 2021錄用,論文內容涵蓋信息抽取、問題生成、文檔檢索以及知識圖譜對齊等經典NLP研究方向。此外,在近期公布的數據挖掘領域國際會議PAKDD獲獎名單中,騰訊天衍實驗室在疾病預測領域的最新研究進展也榮獲了最佳學生論文獎項。
隨著AI技術與醫療行業走向深度融合,應用AI助推醫療智慧化、數字化升級已經成為未來發展方向之一。在本次獲錄的多篇論文中,騰訊天衍實驗室基于醫學AI臨床應用中的多種場景,針對多種機器學習方法展開了創新性研究,研發突破多項行業技術應用難點,有望充分釋放AI在醫療場景運用中的潛力,加速助推AI在醫療健康領域的實踐進程。

ACL是計算語言學和自然語言處理領域影響力最大、最具活力的國際學術會議之一,由計算語言學協會主辦,每年都會有眾多頂級學術機構和科技企業如斯坦福大學、谷歌等,在會議上提交在自然語言處理、人工智能、機器學習方面的最新研究成果。2021年ACL共收到3350篇長文投稿,主會錄用率21.3%。IJCAI則是國際人工智能聯合會議,也是人工智能研究人員和實踐者的頂級國際聚會,在人工智能領域備受學界關注,2021年共收到4204篇有效投稿,最終錄用率僅為13.9%。
讀懂醫療文檔中的復雜關聯
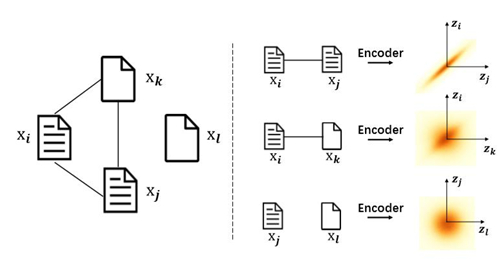
在醫療查詢領域,天衍實驗室提供了多種醫療文檔檢索功能,如相似病例檢索,基于醫療文檔的檢索與問答等。由于檢索速度和內存占用的需求,文檔哈希在現今的大規模信息檢索系統中扮演著越來越重要的角色。大量工作表明,醫療文本之間的語義以及鄰居信息在該文本的編碼和表達過程中往往扮演著更重要的角色,也對生產高質量哈希碼起著關鍵作用。為了將兩種信息良好地融合,在論文中,天衍實驗室將鄰居信息建模在基于圖誘導的高斯分布中,并通過圖驅動生成模型將語義和鄰居信息融合。
為了進一步處理文檔直接復雜的關聯關系,天衍實驗室進一步提出基于樹結構的近似方法來加速訓練。通過該近似方法,證明了訓練目標可以被分解為多個單個文檔或文檔對,從而提高模型的訓練效率。通過結合文本本身的語義信息及文檔之間的相關性,該算法能很好地將文檔相似性映射到哈希碼中,從而大大提高了文檔檢索的速度。
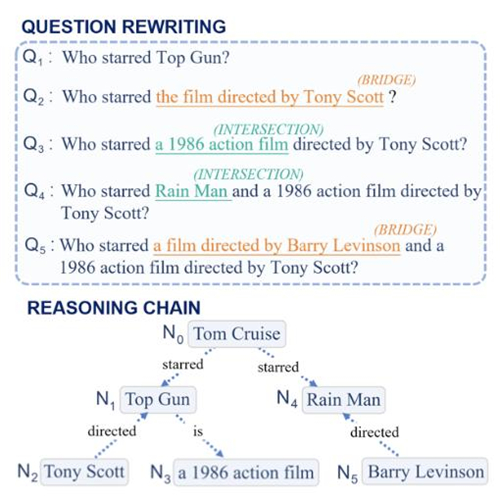
在智能問答場景下,天衍實驗室也開發設計了多種不同的問答助手,例如在醫保政策問答助手,嵌入各地醫保相關服務公眾號,協助回答用戶醫保政策相關的各類問題。然而,由于醫療場景的特殊性,天衍實驗室的研究員們發現先要獲取到大量高質量的問答語料是很困難的,因此在論文中,研究人員提出一種難度可控的多跳問題生成技術,旨在生成那些需要對文本中多處內容、進行多層推理才能作答的困難問題。
具體來說,對于一篇給定的文本c和指定的問題推理層級d,該技術將先對其內容進行構圖,然后從中抽取一條推理鏈,以此生成相關問題。先由一個簡單問題生成器QGInitial生成一個初始問題,再使用另一個問題改寫模型QGRewrite將其改寫為一個更困難的問題。QGRewrite共將重復使用d-1次,從而將問題逐步改寫為包含d層推理的復雜問題。在未來,該問題生成技術可用于為醫保政策、醫療文獻生成配套試題,測試相關人員的掌握程度。
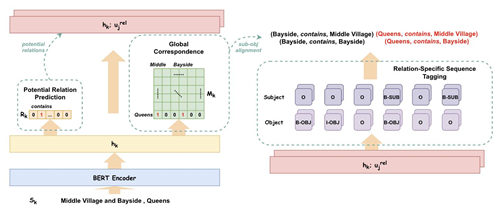
除此之外,在醫療場景中,從醫學相關文本中提取關鍵信息也一直是NLP在業務中落地的一個核心切入點。例如在篇章級別的藥品說明書中抽取(藥品,適應癥,疾病)等各種關系三元組構成藥品知識庫以支持處方合理性審核,用藥推薦等多個業務場景。但在實際算法設計過程中,研究人員發現由于醫療知識的復雜性,不同實體類別之間兩兩組合可以構成多種關系,而冗余的關系類別會極大的影響模型效率和表現,所以天衍實驗室提出一個全新的關系抽取框架,將其拆分為三個子任務:關系類別預測,實體抽取以及頭尾實體配對。
首先,該模型通過關系類別預測模塊從冗余的備選關系中選取最有可能的關系子集,然后以預測得到的關系類別作為序列標注的標簽抽取相關實體,在此過程中,研究人員也利用序列標注技術的特點解決了頭尾實體嵌套的問題,最后模型通過構建實體詞之間的關聯矩陣完成頭尾實體之間的組合配對。一系列實驗結果都證明該模型不僅提升了關系抽取的效率,也在NYT和WebNLG等多個關系抽取數據集上達到了SOTA效果。
破解醫療知識圖譜對齊技術瓶頸
醫療知識圖譜是醫療信息化中最重要的一項技術,也是實現智慧醫療的基石。在構建和更新醫療知識圖譜時,知識圖譜的對齊技術可以將多個不同來源的多個異構醫療知識圖譜進行實體和本體兩個層面的對齊,以構建知識覆蓋度更廣的醫療知識圖譜。在天衍實驗室的實際業務中,研究人員也是利用了知識圖譜對齊技術將各個業務上的醫療垂域知識圖譜進行對齊融合,形成了一整套大規模高置信的醫療知識圖譜,作為驅動騰訊智能醫療的重要根基。在這次放榜的兩大會議中,天衍實驗室也發表了兩篇知識圖譜對齊方向的最新研究成果。
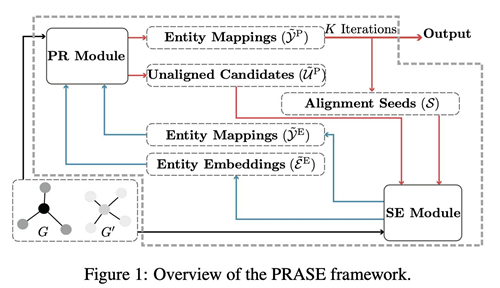
現有的知識圖譜對齊方法大體上可以分為基于推理的傳統方法和基于神經網絡的方法,兩者有各自的優勢但又存在著各自的問題:基于推理的傳統方法無法有效利用知識圖譜的圖結構信息,而基于神經網絡的方法無法利用適當的推理來減少錯誤對齊。因此,天衍實驗室提出了一種迭代框架(PRASE),將兩種方法有效地融合,來達成相互增強的目的。天衍實驗室的PRASE框架可以兼容傳統方法PARIS和多種神經網絡方法。在多個公開數據集和一個工業數據集(醫療知識圖譜)上均表現出了PRASE的SOTA性能。
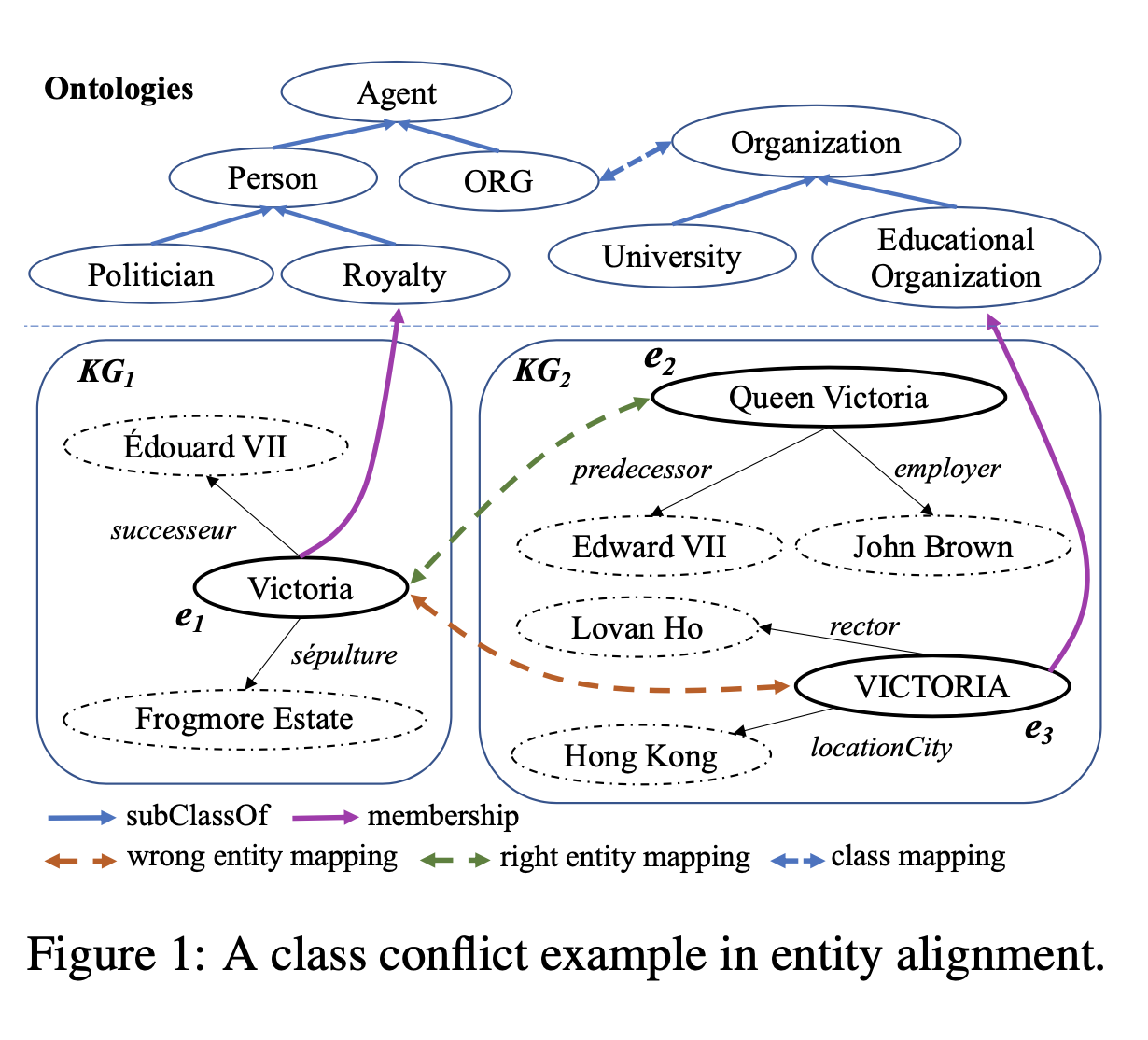
知識圖譜表示學習常常用在知識圖譜對齊任務上,但是目前的表示學習模型通常只會建模圖結構信息、實體名稱信息、實體屬性信息,而沒有考慮知識圖譜的本體信息。本體定義了知識圖譜的元信息以及實體的類別信息,在知識圖譜及其應用中有重要作用。在論文中,天衍實驗室提出了一種基于本體指導的知識圖譜對齊模型(OntoEA),將知識圖譜和本體層級信息共同進行建模,來發現并避免錯誤實體對齊中的類別沖突(class conflict)。天衍實驗室提出的OntoEA模型在多個公開數據集和一個工業數據集(醫療知識圖譜)上均超過了現有的知識圖譜對齊模型,這也證明了引入本體信息的有效性。
突破AI臨床輔診“普適性”難題
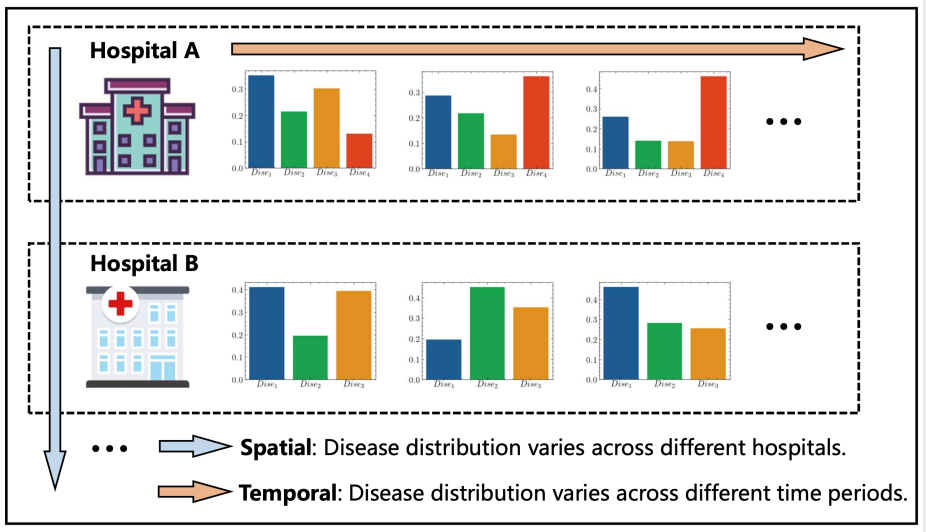
在實際業務場景中,輔診系統需要落地到不同的醫院,而不同醫院的接診病例、疾病體系存在較大的差異,研究人員不斷接到新的醫院數據,遇到新的疾病類別。隨著數據量的增多,結合全量數據進行模型訓練會耗費大量存儲和計算資源。面對此問題,研究人員考慮將其建模為一個增量學習的過程,即以序列形式,訓練多個機器學習模型的任務,保證模型對新舊類別的數據均具有良好的識別性能。
首先研究人員在模型中加入基于醫療實體抽取的預測通道,以文本中的醫療實體作為輸入,該預測通道既增大了醫療實體在疾病預測模型中的作用也為疾病預測的結果提供了一定的可解釋性。另外研究人員提出對于文本,實體兩個預測通道的編碼結果進行二次映射,構建一個基于醫療普適知識的特征空間,并不斷復用到新的任務中,保證在新任務所學到的特征能夠和之前任務所學到的特征進行一定程度的融合,以達到同一模型迅速復用于新醫院新疾病體系且避免災難性遺忘的目的。
本次天衍實驗室多篇上會論文不僅在研發層面實現多項重磅技術突破,具有重要學術價值和臨床應用價值,研究員們也將其技術輸出到騰訊健康小程序、QQ瀏覽器、微信搜一搜等C端應用、以及AI基層司、智慧醫保、公衛等B/G端應用,將創新科技落地到實際應用中,以進一步服務醫生和患者,從社會實踐層面發揮科技創新助力醫療行業智慧化發展的普世價值。
作為醫療AI 領域的創新力量,騰訊天衍實驗室秉承“科技向善”核心理念,一直以來專注于醫療健康領域AI算法研究及落地,以實際場景為依托不斷在NLP,知識圖譜、大數據以及醫療影像等領域探索最前沿的技術,已成功支持了數百家醫院的輔診、導診、疾病輔助診斷、智能用藥等產品,助力醫保、醫院、疾控中心和其他醫療機構的智能化知識挖掘和管理難題,實現知識化轉型。
ACL 2021主會錄用論文3篇:

Findings of ACL錄用1篇

IJCAI 2021錄用1篇:

PAKDD 2021最佳學生論文1篇: