













面試侃集合 | SynchronousQueue非公平模式篇
面試官:好了,你也休息了十分鐘了,咱們接著往下聊聊SynchronousQueue的非公平模式吧。
Hydra:好的,有了前面公平模式的基礎,非公平模式理解起來就非常簡單了。公平模式下,SynchronousQueue底層使用的是TransferQueue,是一個先進先出的隊列,而非公平模式與它不同,底層采用了后進先出的TransferStack棧來實現。
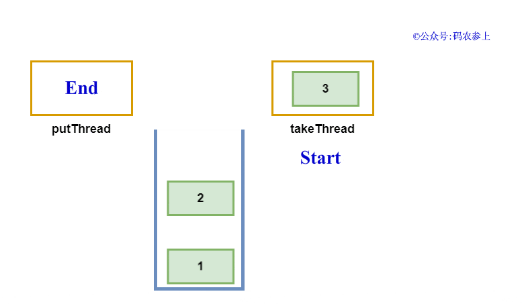
下面我們還是先寫一個例子來看看效果,首先創建3個線程使用put方法向SynchronousQueue中插入數據,結束后再使用3個線程調用take方法:
- SynchronousQueue<Integer> queue=new SynchronousQueue<>(false);
- @AllArgsConstructor
- class PutThread implements Runnable{
- int i;
- @SneakyThrows
- @Override
- public void run() {
- queue.put(i);
- System.out.println("putThread "+i+" end");
- }
- }
- class TakeThread implements Runnable{
- @SneakyThrows
- @Override
- public void run() {
- System.out.println("takeThread take: "+queue.take());
- }
- }
- for (int i = 1; i <=3; i++) {
- new Thread(new PutThread(i)).start();
- Thread.sleep(1000);
- }
- for (int i = 1; i <=3 ; i++) {
- new Thread(new TakeThread()).start();
- Thread.sleep(1000);
- }
運行上面的代碼,查看結果:
- takeThread take: 3
- putThread 3 end
- takeThread take: 2
- putThread 2 end
- takeThread take: 1
- putThread 1 end
可以看到,生產者線程在執行完put后會進行阻塞,直到有消費者線程調用take方法取走了數據,才會喚醒被阻塞的線程。并且,數據的出隊與入隊順序是相反的,即非公平模式下采用的是后進先出的順序。
面試官:就是把結構從隊列換成了棧,真就這么簡單?
Hydra:并不是,包括底層節點以及出入棧的邏輯都做了相應的改變。我們先看節點,在之前的公平模式中隊列的節點是QNode,非公平模式下棧中節點是SNode,定義如下:
- volatile SNode next; // 指向下一個節點的指針
- volatile SNode match; // 存放和它進行匹配的節點
- volatile Thread waiter; // 保存阻塞的線程
- Object item;
- int mode;
- SNode(Object item) {
- this.item = item;
- }
和QNode類似,如果是生產者構建的節點,那么item非空,如果是消費者產生的節點,那么item為null。此外還有一個mode屬性用來表示節點的狀態,它使用TransferStack中定義的3個常量來表示不同狀態:
- static final int REQUEST = 0; //消費者
- static final int DATA = 1; //生產者
- static final int FULFILLING = 2; //匹配中狀態
TransferStack中沒有攜帶參數的構造函數,使用一個head節點來標記棧頂節點:
- volatile SNode head;
面試官:基本結構就講到這吧,還是老規矩,先從入隊操作開始分析吧。
Hydra:當棧為空、或棧頂元素的類型與自己相同時,會先創建一個SNode節點,并將它的next節點指向當前棧頂的head,然后將head指針指向自己。這個過程中通過使用CAS保證線程安全,如果失敗則退出,在循環中采取自旋的方式不斷進行嘗試,直到節點入棧成功。用一張圖來表示兩個線程同時入棧的場景:
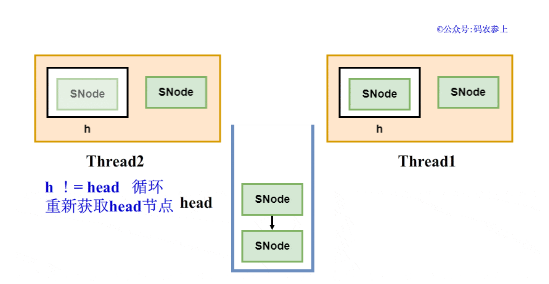
當節點完成入棧后,調用awaitFulfill方法,等待匹配的操作的到來。在這一過程中,會使節點對應的線程進行自旋或掛起操作,直到匹配操作的節點將自己喚醒,或被其他線程中斷、等待超時。
當入棧后的節點是棧頂節點,或者節點的類型為FULFILLING匹配狀態時,那么可能會馬上完成匹配,因此先進行自旋,當超過自旋次數上限后再掛起。而如果節點在自旋過程中,有新的節點壓入棧頂,會將非棧頂節點剩余的自旋次數直接清零,掛起線程避免浪費資源。
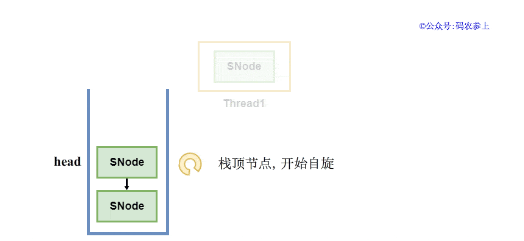
面試官:你上面也說了,掛起的線程有可能會超時或者被中斷,這時候應該怎么處理?
Hydra:當這兩種情況出現時,SNode會將match屬性設為自身,退出awaitFulfill方法,然后調用clean方法將對應的節點清理出棧。具體情形可分為兩種情況。先說簡單的情況,如果清理的是棧頂節點,那么直接將head節點指向它的next節點,即將當前棧頂節點彈出即可。
面試官:那么如果要刪除的節點不是棧頂的節點呢?
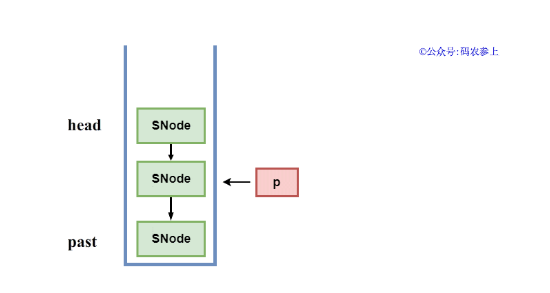
Hydra:如果清理的不是棧頂節點,會稍微有一些麻煩。因為棧的底層是一個單向的鏈表結構,所以需要從棧頂head節點開始遍歷,遍歷到被刪除節點的后繼節點為止。所以在清除工作開始前,先使用了一個past節點標記需要刪除節點的下一個節點,作為結束遍歷的標記。
然后創建一個標記節點p,初始時指向head節點,開始循環,如果p的next節點不是需要被刪除的節點,那么就將p向后移一個位置,直到找到這個需要被刪除的中斷或超時的節點,然后將p的next指向這個刪除節點的next節點,在邏輯上完成鏈表中節點的刪除。
面試官:單一類型節點的入棧應該說完了吧,接下來說說不同類型節點間是如何實現的匹配操作吧?
Hydra:好的,那我們先回顧一點上面的知識,前面說過每個節點有一個mode屬性代表它的模式,REQUEST表示它是消費者,DATA表示是生產者,FULFILLING表明正處于匹配中的狀態。
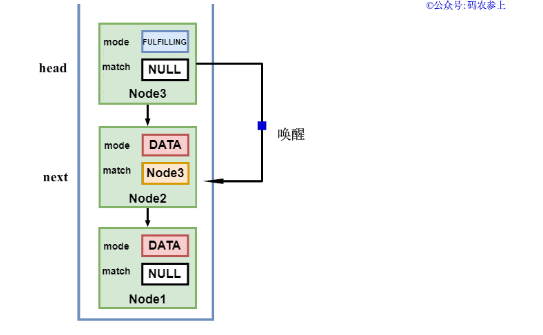
在一個新的線程調用方法時,先判斷它的類型mode是什么,如果和當前棧頂head節點類型不同,且head節點的狀態不為匹配中時,將它的狀態設置為FULFILLING|mode,壓入棧中。然后將嘗試匹配新的head節點和它的next節點,如果匹配成功,會將next節點的match屬性設置為head節點,喚醒掛起的next節點中的線程。
在完成匹配后,當前頭節點對應的線程會協助推進head節點,將head指向next節點的下一個節點,即完成了棧頂兩節點的出棧。最終消費者線程會返回匹配的生產者節點中的item數據值,而生產者線程也會結束運行退出。
我們以棧中當前節點為DATA類型,新節點為REQUEST類型畫一張圖,來直觀的感受一下上面的流程:
面試官:總算是講完了,能對SynchronousQueue做一個簡單的總結嗎?
Hydra:SynchronousQueue基于底層結構,實現了線程配對通信這一機制。在它的公平模式下使用的是先進先出(FIFO)的隊列,非公平模式下使用的是后進先出(LIFO)的棧,并且SynchronousQueue沒有使用synchronized或ReentrantLock,而是使用了大量的CAS操作來保證并發操作。可能我們在平常的工作中使用場景不是很多,但是在線程池的設計中使用了SynchronousQueue,還是有很重要的應用場景的。
面試官:講的還行,不過剛才這些和公平模式聽起來感覺區別不大啊,沒有什么技術含量。這樣吧,你明天過來我們加試一場,我再給你打分。
Hydra:(溜了溜了,還是找家別的靠譜公司吧……)

















