“有的放矢”才是性能優化的正確打開方式
在Kafka消息發送端遇到性能瓶頸時是否有辦法正確的評估瓶頸在哪呢?如何針對性的進行調優呢?
1、Kafka 消息發送端監控指標
其實Kafka早就為我們考慮好了,Kafka提供了豐富的監控指標,并提供了JMX的方式來獲取這些監控指標,在客戶端提供的監控指標如下圖所示:
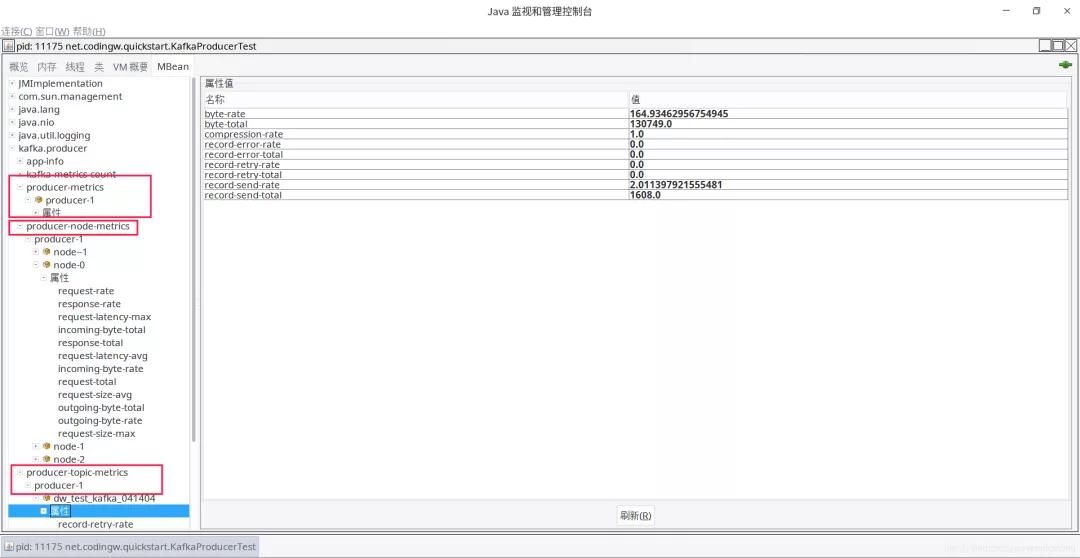
主要的監控指標分類如下:
- producer-metrics
消息發送端的監控指標,其子節點為該進程下所有的生產者
- producer-node-metrics
以Broker節點為維度,每一個發送方的數據指標。
- producer-topic-metrics
以topic為維度,統計該發送端的一些指標。
Kafka Producer相關的指標比較多,本文不會一一羅列。
1.1 producer-metrics
producer-metrics是發送端一個非常重要的監控項,如下圖所示:
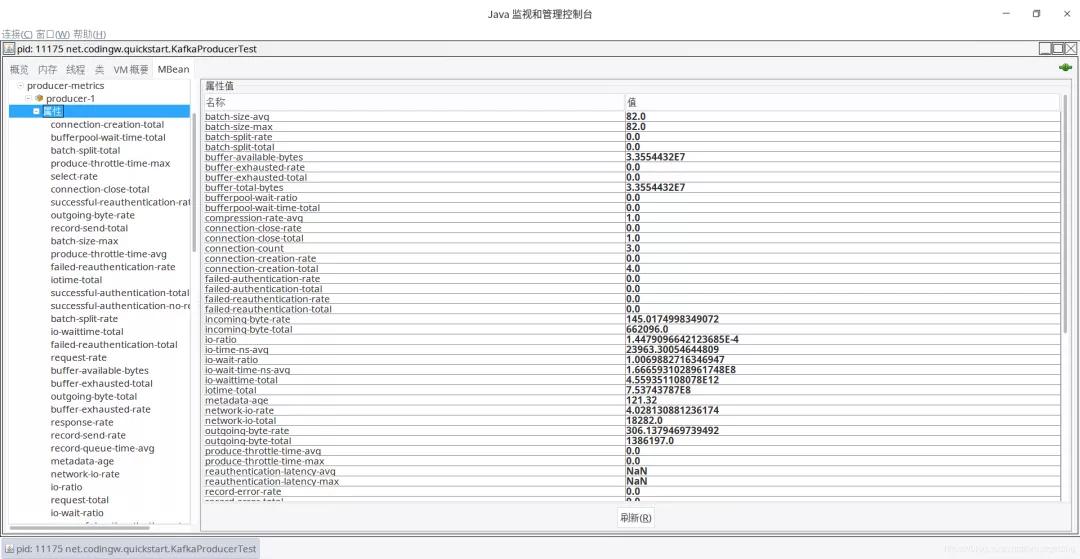
其重點項說明如下:
- batch-size-avg
Sender線程實際發送消息時一個批次(ProducerBatch)的平均大小。
- batch-size-max
Sender線程時間發送消息時一個批次的最大大小。
實踐指導:個人覺得這兩個參數非常有必要進行采集,如果該值遠小于batch.size設置的值,如果吞吐量不達預期,可以適當調大linger.ms。
- batch-split-rate
Kafka提供了對大的ProducerBatch分割成小的機制,即如果客戶端的ProducerBatch如果超過了服務端允許的最大消息大小,將會觸發在客戶端分割重新發送,該值記錄每秒切割的速率
- batch-split-total
Kafka 發生的 split 次數。
溫馨提示:按照筆者對這部分源碼的閱讀,我覺得ProducerBatch的split的意義不大,因為新分配的ProducerBatch的容量會等于batch.size,未超過該大小,則該Batch不會被分隔,筆者認為該功能大概率無法完成實際的切割意圖。
實踐指導:如果該值不為0,則表示服務端,客戶端設置的消息大小不合理,客戶端設置的batch.szie大小應該小于服務端設置的 max.message.bytes,默認值100W字節(約等于1M)
- buffer-available-bytes
當前發送端緩存區可用字節大小。
- buffer-total-bytes
發送端總的緩存區大小,默認為32M,33,554,432個字節。
實戰指導:如果緩存區剩余字節數持續較低,需要評估緩存區大小是否合適,Sender線程遇到了瓶頸,從而考慮網絡、Brorker是否遇到瓶頸。
- bufferpool-wait-ratio
- bufferpool-wait-time-total
客戶端從緩存區中申請內存用于創建ProducerBatch所阻塞的總時長。
實戰指導:如果該值持續大于0,說明發送存在瓶頸,可以適當降低linger.ms的值,讓消息有機會得到更加及時的處理。
- produce-throttle-time-avg
消息發送被broker限流的平均時間
- produce-throttle-time-max
消息發送被broker限流的最大時間
- io-ratio
IO線程處理IO讀寫的總時間
- io-time-ns-avg
每一次事件選擇器調用IO操作的平均時間(單位為納秒)
- io-waittime-total
io線程等待讀寫就緒的平均時間(單位為納秒)
- iotime-total
io處理總時間。
- network-io-rate
客戶端每秒所有連接的網絡讀寫tps。
- network-io-total
客戶端所有連接上的網絡操作(讀或寫)總數。
1.2 通用指標
Kafka在消息發送端除了上述指標外,還有一些通用類的監控指標,這類指標的統計維度包括:消息發送者、節點、TOPIC三個維度。
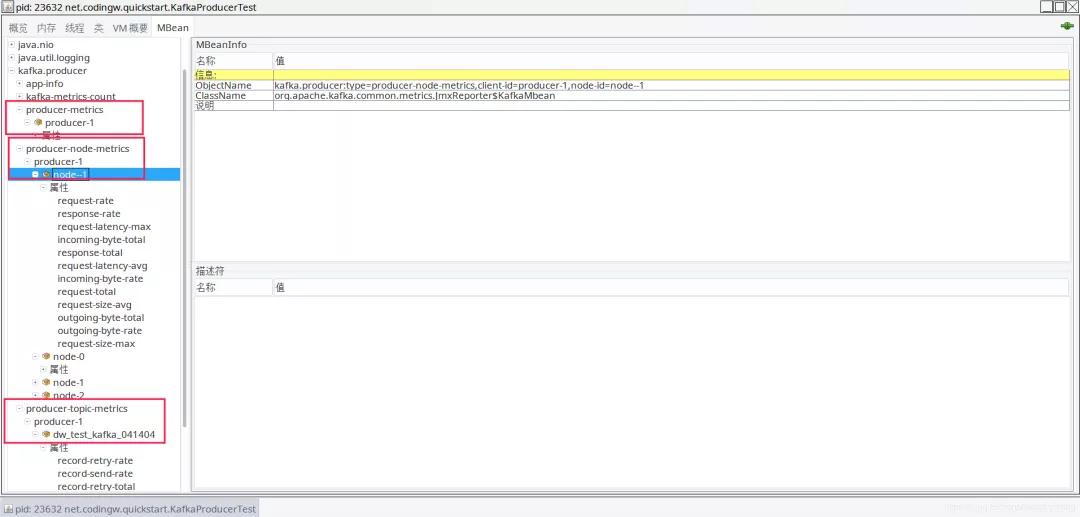
主要的維度說明如下:
- producer-metics
發送端維度
- producer-node-metrics
發送端-Broker節點維度
- producer-topic-metrics
發送端-主題維度的統計
接下來說明的指標,分別以不同的維度進行統計,但其表示的含義表示一樣,故接下來統一說明。
- incoming-byte-rate
每秒的入端流量,每秒進入的字節數。
- incoming-byte-total
總共進入的字節數。
- outgoing-byte-total
總出發送的字節數。
- request-latency-avg
消息發送的平均延時。
- request-latency-max
消息發送的最大延遲時間。
實戰指導:latency-avg與max可以反應消息發送的延遲性能,如果延遲過高,說明Sender線程發送消息存在瓶頸,建議該值與linger.ms進行比較,如果該值顯著小于linger.ms,則為了提高吞吐率,可適當調整batch.size的大小。
- request-rate
每秒發送Tps
- request-size-avg
消息發送的平均大小。
- request-size-max
Sender線程單次消息發送的最大大小。
實戰指導:如果該值遲遲小于max.request.size,說明客戶端消息積壓的消息不多,如果從其他維度表明遇到了瓶頸,可以適當linger.ms,batch.size,可有效提高吞吐。
- request-total
請求發送的總字節數
- response-rate
每秒接受服務端響應TPS
- response-total
收到服務端響應總數量。
2、監控指標采集
雖然Kafka內置了眾多的監控指標,但這些指標默認是存儲在內存中,既然是存放在內存中,為了避免監控數據無休止的增加內存觸發內存溢出,通常監控數據的存儲基本是基于滑動窗口,即只會存儲最近一段時間內的監控數據,進行滾動覆蓋。
故為了更加直觀的展示這些指標,因為需要定時將這些信息進行采集,統一存儲在其他數據庫等持久化存儲,可以根據歷史數據繪制曲線,希望實現的效果如下圖所示:
基本的監控采集系統架構設計如下圖所示:
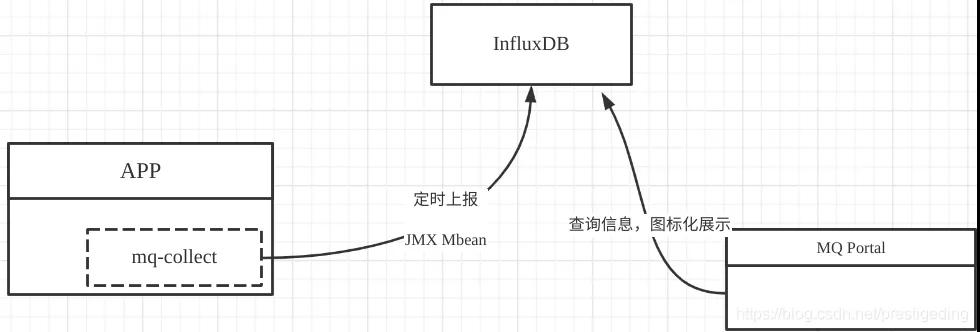
mq-collect應該是放在生產者SDK中,通過mq-collect類庫異步定時將采集信息上傳的到時序數據庫InfluxDB,然后通過mq-portal門戶展示頁面,對每一個生產客戶端按指標進行可視化展示,實現監控數據的可視化,從而為性能優化提供依據。
本文轉載自微信公眾號「中間件興趣圈」,可以通過以下二維碼關注。轉載本文請聯系中間件興趣圈公眾號。