玩轉Service Mesh微服務熔斷、限流騷操作
本文轉載自微信公眾號「無敵碼農」,作者無敵碼農 。轉載本文請聯系無敵碼農公眾號。
在微服務架構中,隨著服務調用鏈路變長,為了防止出現級聯雪崩,在微服務治理體系中,熔斷、限流作為服務自我保護的重要機制,是確保微服務架構穩定運行的關鍵手段之一。
那么什么是熔斷、限流?在傳統Spring Cloud微服務、以及新一代Service Mesh微服務架構中,它們分別又是怎么實現的?本文將對此進行闡述!
服務熔斷、限流概述
先理解下熔斷、限流的基本概念以及它們的應用場景。說起熔斷這個詞,大家印象深刻的可能是股市交易熔斷、或者電路保險絲斷開這樣的場景;而微服務中的熔斷本質上和這些場景中所描述的理念是一致的。都是為了在極端情況下,保證系統正常運行而設計的一種自我保護機制。
熔斷的基本邏輯就是隔離故障。在微服務架構盛行的今天,服務之間的調用鏈路相比單體應用時代變得更長了,服務化拆分帶來系統整體能力提升的同時,也增加了服務級聯故障出現的概率。例如調用鏈路“A->B->C->D”,如果服務D出現問題,那么鏈路上的A、B、C都可能會出現問題,這一點也很好理解,因為出現故障的服務D,必然會在某個時間段內阻塞C->D的調用請求,并最終蔓延至整個鏈路。而服務連接資源又是有限的,這種增加的調用耗時,會逐步消耗掉整個鏈路中所有服務的可用線程資源,從而成為壓垮整個微服務體系的幕后黑手。
而為了防止故障范圍的擴大,就需要對故障服務D進行隔離,隔離的方式就是服務C在感知到對D的調用頻繁出現故障(超時或錯誤)后,主動斷掉對D的連接,直接返回失敗調用結果。以此類推,如果微服務中的所有鏈路都設置這樣的熔斷機制,那么就能逐級實現鏈路的分級保護效果。
熔斷機制雖然解決不了故障,但卻能在故障發生時盡量保全非故障鏈路上的服務接口能被正常訪問,從而將故障范圍控制在局部。當然被熔斷的服務也不會一直處于熔斷狀態,在熔斷機制的設計中還要考慮故障恢復處理機制。
說完熔斷,再來說說限流。熔斷的主要目的是隔離故障,而引起故障的原因除了系統本身的問題外,還有一種可能就是請求量達到了系統處理能力的極限,后續新進入的請求會持續加重服務負載,最終導致資源耗盡,從而引起系統級聯故障、導致雪崩。而限流的目的就是拒絕多余流量、保證服務整體負載始終處于合理水平。
從限流范圍上看,微服務體系中的每個服務都可以根據自身情況設置合理的限流規則,例如調用鏈路“A->B->C->D”,B服務的承受力是1000QPS,如果超過該閥值,那么超出的請求就會被拒絕,但這也容易引起A對B的熔斷,所以對于微服務設置限流規則的設置最好還是根據壓測結果確定。
在實際場景中,對單個節點的微服務分別設置限流,雖然從邏輯上沒啥毛病,但實際操作起來卻并不容易,這主要是因為限流規則分散不好統一控制,另外對于單節點閥值的評估,在全鏈路環境下并不能得出“1+1=2”的結果。所以,一般做法是根據全鏈路壓測結果,在服務網關統一進行集群級別的限流處理。
接下來將分別介紹在Spring Cloud傳統微服務體系,以及新一代Service Mesh微服務體系中,熔斷、限流的基本實現原理,并重點演示基于Istio的微服務熔斷、限流邏輯具體實踐!
Spring Cloud微服務對熔斷/限流的處理
說起Spring Cloud微服務中的熔斷、限流,最先想到的肯定是Hystrix、Sentinel這樣的技術組件。關于這兩種著名的熔斷、限流組件,在筆者早先的文章<
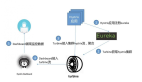
從本質上說Hystrix與Sentinel并無實質差別,它們都是以SDK的形式附著在具體微服務進程之上的、實現了熔斷/限流功能的本地工具包。具體示意圖如下:
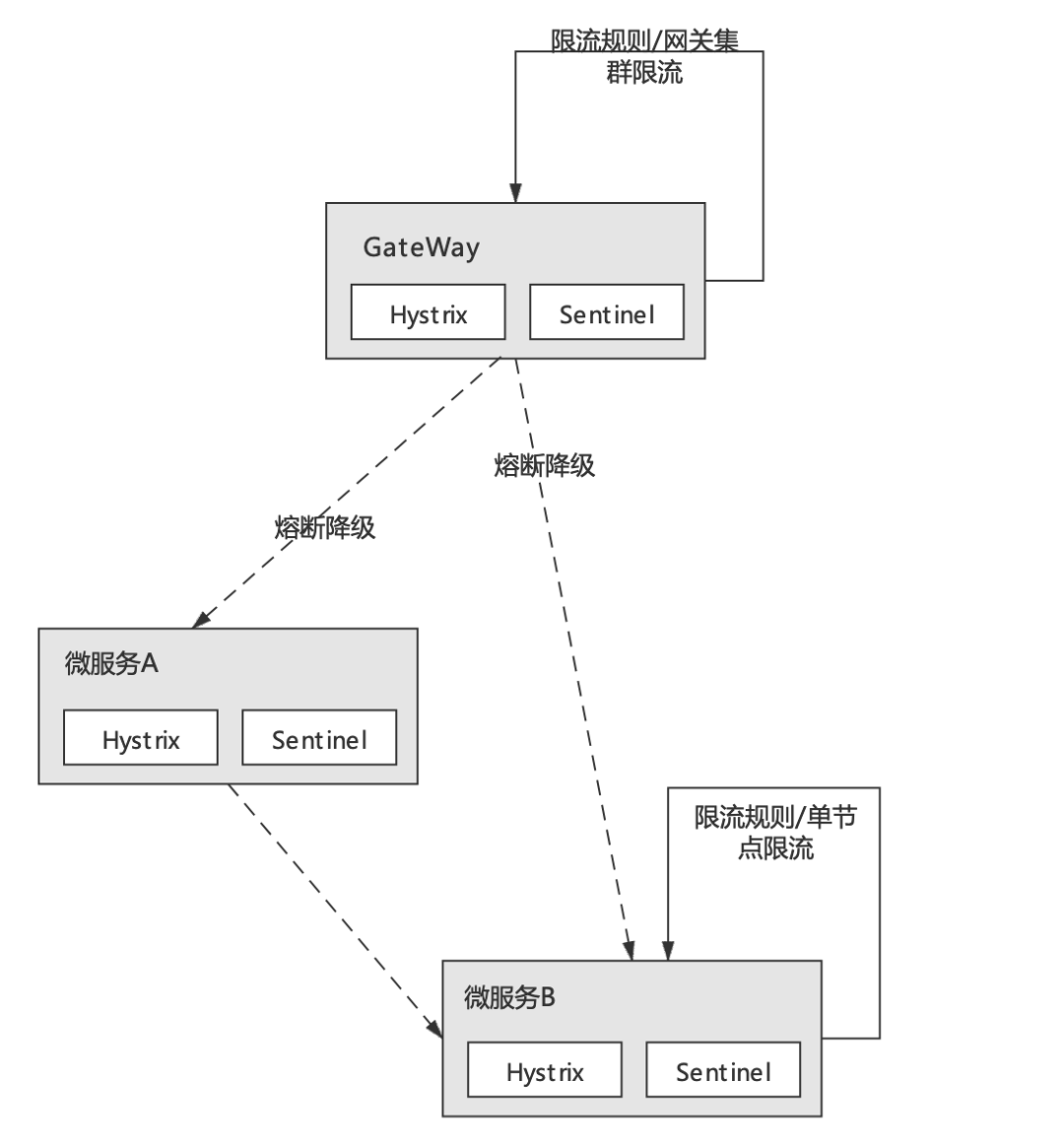
在Spring Cloud微服務中,Hystrix、Sentinel等熔斷、限流組件通過嵌入微服務進程,統計微服務一段時期內的入口流量及依賴服務的錯誤調用次數、并根據組件的所提供功能及規則配置,來決定是否觸發限流或熔斷降級邏輯。這樣的過程完全是附著在微服務進程本身完成的,雖然限流/熔斷組件本身也提供了線程池隔離之類資源隔離手段,但從服務治理的角度來看,這樣的方式顯然還是侵入了業務、占用了業務系統資源;并且分散于應用的規則配置,也不利于微服務體系的整體管控。
Service Mesh微服務熔斷/限流實現
前面簡單概述了Spring Cloud微服務體系中實現熔斷、限流機制的基本框架及存在的弊端。接下來將具體分析下同樣的邏輯在Service Mesh微服務架構中是如何實現的?
關于Service Mesh微服務架構如果你還比較陌生,可以先通過筆者之前的文章<<干貨|如何步入Service Mesh微服務架構時代>><<實戰|Service Mesh微服務架構實現服務間gRPC通信>>進行了解,這兩篇文章從概念到實踐詳細介紹了基于Istio的Service Mesh微服務架構的具體玩法。本文所依賴的操作環境及示例代碼均依賴于該文章所演示的案例。
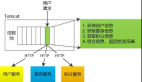
而回到本文的主題,要了解Service Mesh微服務架構中熔斷、限流的實現機制,還是需要從整體上理解服務網格實現的基本架構,具體如下圖所示:
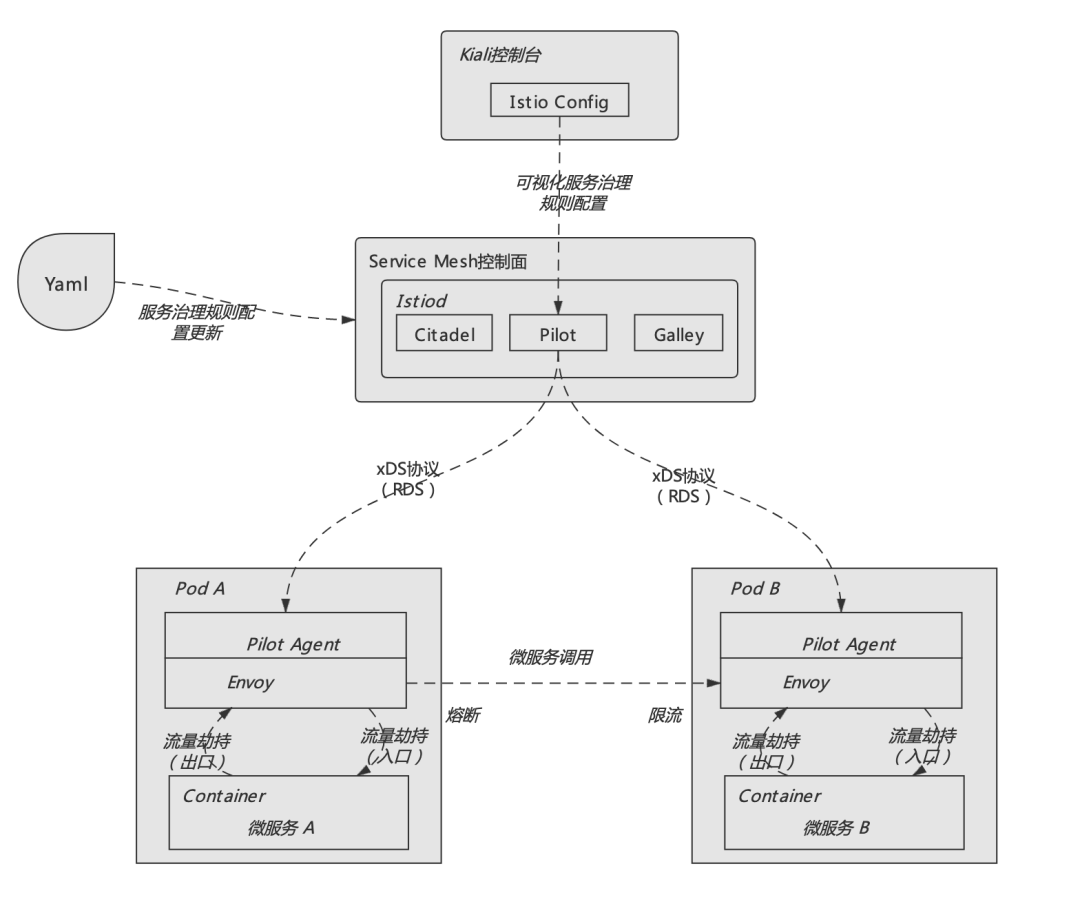
如上圖所示,Service Mesh架構總體上由控制面(Control Plane)、數據面(Data Plane)這兩部分組成。其中控制面主要承擔整個微服務體系治理信息的集中管控;而數據面則負責具體執行由控制面下發的各類服務治理信息及規則。例如服務節點信息的發現、以及本文所講述的熔斷、限流規則等都是通過控制面統一下發至各數據面節點的。
數據面就是一個個代理服務,在Service Mesh體系下每個具體的微服務實例都會自動創建一個與之對應的代理,這個代理服務就是我們俗稱的邊車(SideCar)。這些代理會主動劫持所代理的微服務實例的入口流量和出口流量,從而根據控制面下發的服務治理信息實現路由發現、負載均衡、熔斷、限流等系列邏輯。
從中可以看出,在Service Mesh微服務架構中,各個具體的微服務之間不再直接發生連接,而是轉由各自的SideCar代理實現,因此在應用形態上就形成了一組由代理所組成的網狀交互結構,這就是服務網格名稱的由來。具體如下圖所示:
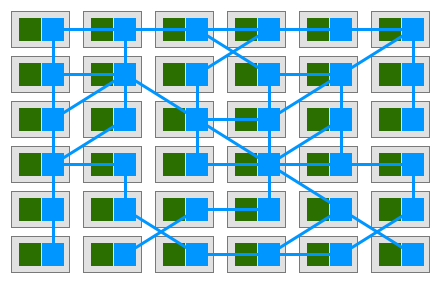
將微服務治理邏輯從原先具體的微服務進程中抽離出來,并實現由統一控制面管理、代理數據面執行的體系結構,這就是Service Mesh微服務體系與Spring Cloud傳統微服務體系在架構上最大的區別。
本文所提到的熔斷、限流邏輯,也是在這樣的架構模式下實現的。而控制面與數據面之間的具體通信則是通過一組被稱為xDS協議的數據交互方式實現。xDS協議的核心是定義了一套可擴展的通用微服務控制API,這些API不僅可以做到服務發現、還可以做到路由發現,可以說Service Mesh微服務體系中所有與服務治理相關的配置都可以通過xDS所提供的發現方式來實現,控制面與數據面之間正是通過這種全新的方案實現了各類數據的獲取、及動態資源的變更。
而具體來說xDS包含LDS(監聽發現服務)、CDS(集群發現服務)、EDS(節點發現服務)、SDS(密鑰發現服務)和RDS(路由發現服務)。xDS中的每種類型都會對應一個發現資源,而本文所要講述的熔斷、限流邏輯則是由RDS(路由發現服務)實現。由于篇幅的關系,就不展開講了,感興趣的讀者可以看看官方文檔,大家對此有個印象即可!
Istio服務網格熔斷、限流實踐
前面從整體架構的角度簡單分析了Service Mesh微服務治理體系的基本原理,接下來將基于Istio并結合微服務實戰案例,從實踐角度具體演示如何實現微服務之間的熔斷、限流配置。以下操作假設你已經在Kubernetes集群安裝了Istio,并正常部署了<<干貨|如何步入Service Mesh微服務架構時代>><<實戰|Service Mesh微服務架構實現服務間gRPC通信>>所演示的微服務案例。
Istio無需對代碼進行任何更改就可以為應用增加熔斷和限流功能。Istio中熔斷和限流在DestinationRule的CRD資源的TrafficPolicy中設置,通過設置連接池(connectionPool)實現限流、設置異常檢測(outlierDetection)實現熔斷。
限流邏輯演示
在Istio中,微服務的限流主要是通過設置connectionPool參數實現。該參數可以對上游服務的并發連接數和請求數進行限制(適用于TCP和HTTP),從而實現限流功能。例如要在API服務層實現限流,鏈路示意圖如下:
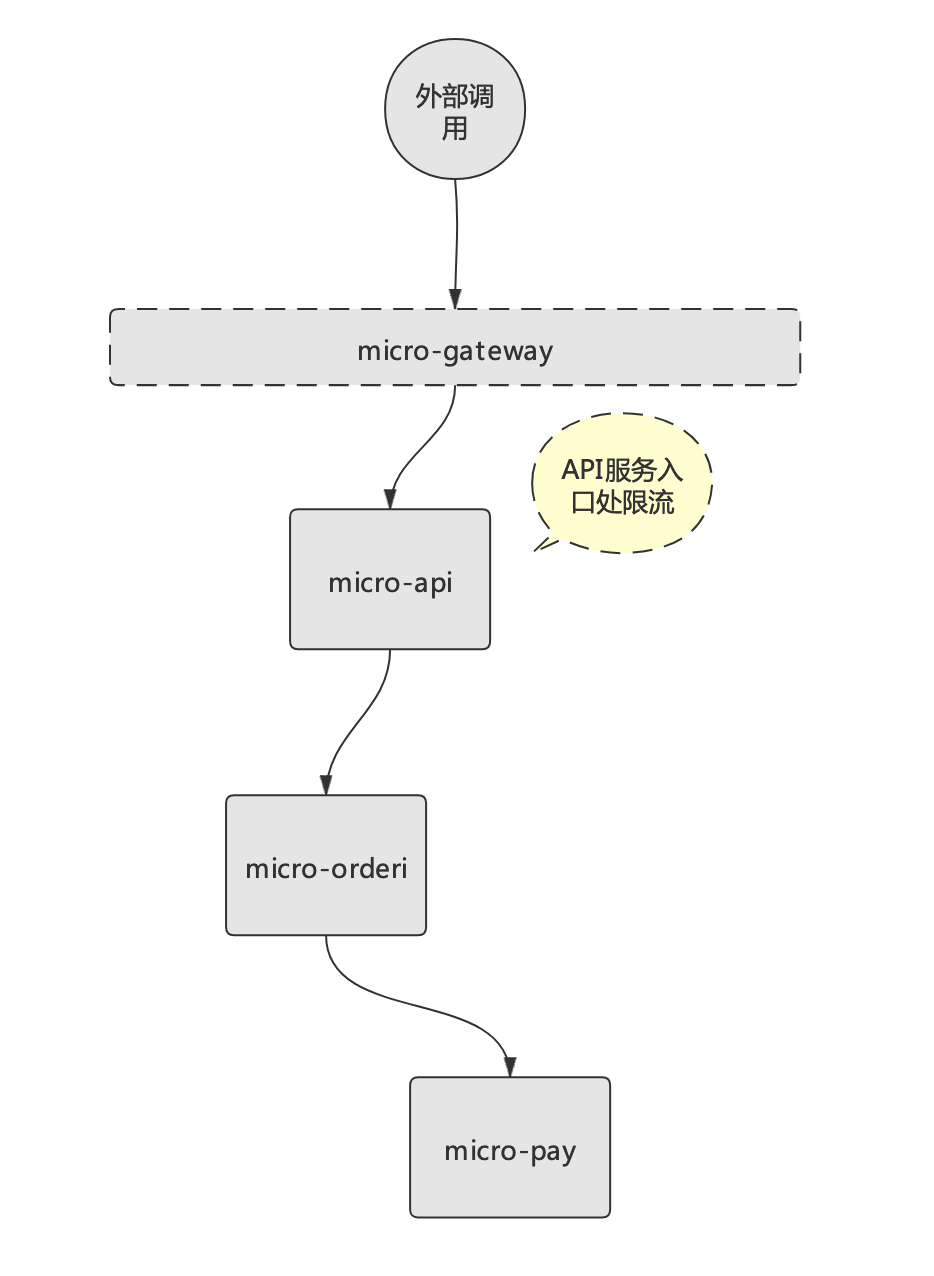
在Istio中實現此類限流邏輯,步驟如下:
1)、創建統一管理路由規則的配置文件(destination-rule-all.yaml),如:
- ---
- apiVersion: networking.istio.io/v1alpha3
- kind: DestinationRule
- metadata:
- name: micro-api
- spec:
- host: micro-api
- trafficPolicy:
- connectionPool:
- tcp:
- maxConnections: 1
- http:
- http1MaxPendingRequests: 1
- maxRequestsPerConnection: 1
- ---
上述規則文件定義了針對mico-api服務的限流規則,其中maxConnections(最大連接數為1)、http1MaxPendingRequests(最大等待請求數為1),如果連接和并發請求數超過1個,那么該服務就會觸發限流規則。
創建規則資源,命令如下:
- $ kubectl apply -f destination-rule-all.yaml
- destinationrule.networking.istio.io/micro-api unchanged
規則創建完后可以通過命令查看規則,命令如下:
- $ kubectl get destinationrule micro-api -o yaml
- apiVersion: networking.istio.io/v1beta1
- kind: DestinationRule
- metadata:
- ...
- spec:
- host: micro-api
- trafficPolicy:
- connectionPool:
- http:
- http1MaxPendingRequests: 1
- maxRequestsPerConnection: 1
- tcp:
- maxConnections: 1
可以看到,規則資源已經成功創建!
2)、部署壓測工具,驗證限流效果
接下來,通過部署Istio提供的壓測工具fortio,模擬調用微服務并觸發限流規則。部署fortio命令如下:
- $ kubectl apply -f samples/httpbin/sample-client/fortio-deploy.yaml
找到Istio安裝目錄“samples/httpbin/sample-client”后執行上述部署命令。
接下來通過fortio工具模擬壓測mico-api服務接口,命令如下:
- #將fortio服務pod信息寫入系統變量
- $ export FORTIO_POD=$(kubectl get pods -lapp=fortio -o 'jsonpath={.items[0].metadata.name}')
- #通過設置2個線程,并發調用20次進行壓測
- $ kubectl exec "$FORTIO_POD" -c fortio -- /usr/bin/fortio load -c 2 -qps 0 -n 20 -loglevel Warning -H "Content-Type:application/json" -payload '{"businessId": "51210428001784966", "amount":100, "channel":1}' http://10.211.55.12:31107/api/order/create
壓測數據效果如下:
- 11:18:54 I logger.go:127> Log level is now 3 Warning (was 2 Info)
- Fortio 1.11.3 running at 0 queries per second, 2->2 procs, for 20 calls: http://10.211.55.12:31107/api/order/create
- Starting at max qps with 2 thread(s) [gomax 2] for exactly 20 calls (10 per thread + 0)
- 11:18:54 W http_client.go:693> Parsed non ok code 503 (HTTP/1.1 503)
- 11:18:54 W http_client.go:693> Parsed non ok code 503 (HTTP/1.1 503)
- 11:18:54 W http_client.go:693> Parsed non ok code 503 (HTTP/1.1 503)
- 11:18:54 W http_client.go:693> Parsed non ok code 503 (HTTP/1.1 503)
- Ended after 262.382465ms : 20 calls. qps=76.225
- Aggregated Function Time : count 20 avg 0.025349997 +/- 0.01454 min 0.001397264 max 0.049622545 sum 0.506999934
- # range, mid point, percentile, count
- >= 0.00139726 <= 0.002 , 0.00169863 , 15.00, 3
- > 0.003 <= 0.004 , 0.0035 , 20.00, 1
- > 0.016 <= 0.018 , 0.017 , 25.00, 1
- > 0.018 <= 0.02 , 0.019 , 30.00, 1
- > 0.02 <= 0.025 , 0.0225 , 50.00, 4
- > 0.025 <= 0.03 , 0.0275 , 65.00, 3
- > 0.03 <= 0.035 , 0.0325 , 70.00, 1
- > 0.035 <= 0.04 , 0.0375 , 80.00, 2
- > 0.04 <= 0.045 , 0.0425 , 95.00, 3
- > 0.045 <= 0.0496225 , 0.0473113 , 100.00, 1
- # target 50% 0.025
- # target 75% 0.0375
- # target 90% 0.0433333
- # target 99% 0.048698
- # target 99.9% 0.0495301
- Sockets used: 6 (for perfect keepalive, would be 2)
- Jitter: false
- Code 200 : 16 (80.0 %)
- Code 503 : 4 (20.0 %)
- Response Header Sizes : count 20 avg 148.8 +/- 74.4 min 0 max 186 sum 2976
- Response Body/Total Sizes : count 20 avg 270.8 +/- 2.4 min 266 max 272 sum 5416
- All done 20 calls (plus 0 warmup) 25.350 ms avg, 76.2 qps
在可以看到20次請求,共成功16次,4次被限流后返回了503。查看istio-proxy狀態日志,命令如下:
- $ kubectl exec "$FORTIO_POD" -c istio-proxy -- pilot-agent request GET stats | grep micro-api | grep pending
- cluster.outbound|19090||micro-api.default.svc.cluster.local.circuit_breakers.default.rq_pending_open: 0
- cluster.outbound|19090||micro-api.default.svc.cluster.local.circuit_breakers.high.rq_pending_open: 0
- cluster.outbound|19090||micro-api.default.svc.cluster.local.upstream_rq_pending_active: 0
- cluster.outbound|19090||micro-api.default.svc.cluster.local.upstream_rq_pending_failure_eject: 0
- cluster.outbound|19090||micro-api.default.svc.cluster.local.upstream_rq_pending_overflow: 0
- cluster.outbound|19090||micro-api.default.svc.cluster.local.upstream_rq_pending_total: 0
從上述日志可以看出micro-api服務的限流規則被觸發了!
熔斷邏輯演示
熔斷是減少服務異常、降低服務延遲的一種設計模式,如果在一定時間內服務累計發生錯誤的次數超過了預定義閥值,Istio就會將該錯誤的服務從負載均衡池移除,當超過一段時間后,又會將服務再移回服務負載均衡池。
具體來說Istio引入了異常檢測來完成熔斷功能,通過周期性的動態異常檢測來確定上游服務(被調用方)中的某些實例是否異常,如果發現異常就將該實例從連接池中隔離出去,這就是異常值檢測。例如對于HTTP服務,如果API調用連續返回5xx錯誤,則在一定時間內連接池拒絕此服務;而對于TCP服務,一個主機連接超時/失敗次數達到一定次數就認為是連接錯誤。
隔離不是永久的,會有一個時間限制。當實例被隔離后會被標記為不健康,并且不會被加入到負載均衡池中。具體的隔離時間等于envoy中“outlier_detection.baseEjectionTime”的值乘以實例被隔離的次數。經過規定的隔離時間后,被隔離的實例將會自動恢復過來,重新接受調用方的遠程調用。
回到熔斷演示案例,假設micro-pay服務不穩定,micro-order服務要實現對該服務的熔斷策略,鏈路示意圖如下:
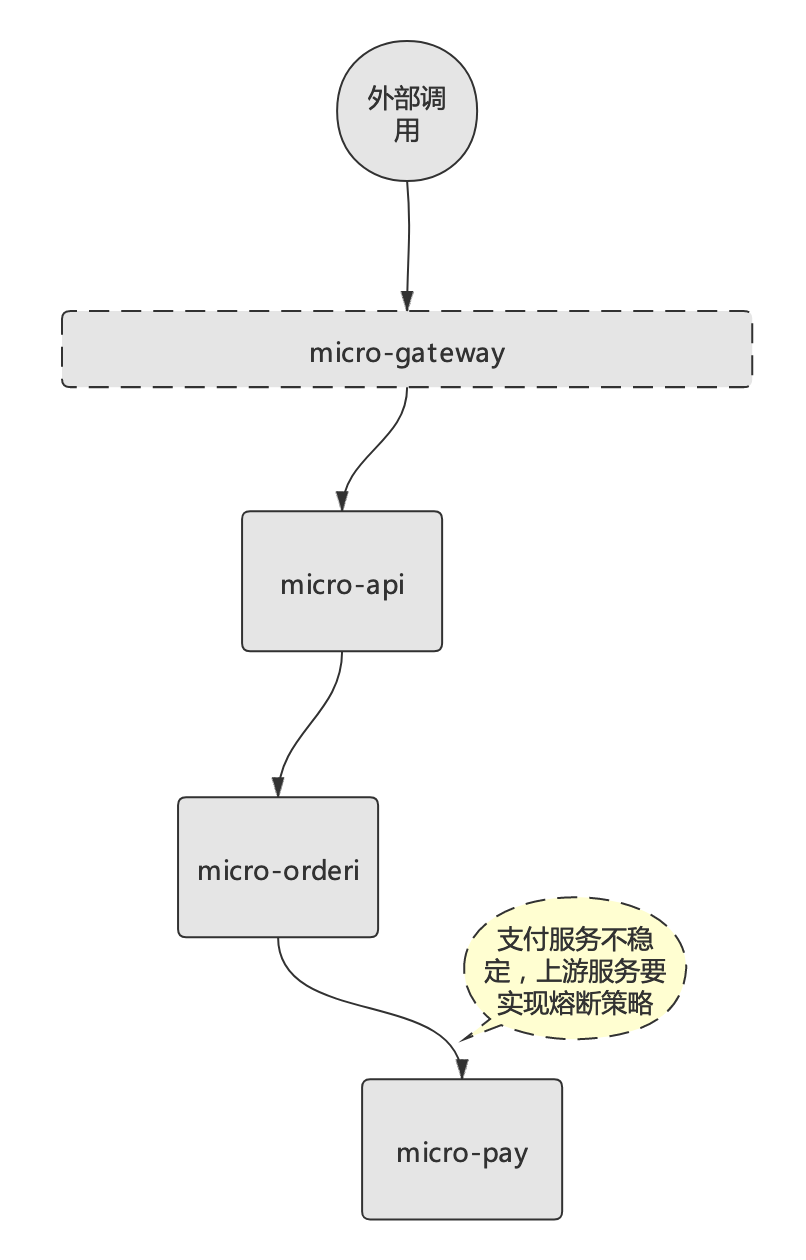
與限流配置類似,Istio的熔斷邏輯也是基于“DestinationRule”資源。針對micro-pay微服務的熔斷規則配置如下(可在destination-rule-all.yaml文件增加配置):
- ---
- apiVersion: networking.istio.io/v1alpha3
- kind: DestinationRule
- metadata:
- name: micro-pay
- spec:
- host: micro-pay
- trafficPolicy:
- #限流策略
- connectionPool:
- tcp:
- maxConnections: 1
- http:
- #http2MaxRequests: 1
- http1MaxPendingRequests: 1
- maxRequestsPerConnection: 1
- #熔斷策略
- outlierDetection:
- consecutive5xxErrors: 1
- interval: 1s
- baseEjectionTime: 3m
- maxEjectionPercent: 100
- ---
如上配置,為了演示micro-pay的報錯情況,這里也針對該微服務配置了限流規則。而熔斷策略配置的意思是:“每1秒鐘(interval)掃描一次上游主機(mico-pay)實例的情況,連續失敗1次返回5xx碼(consecutive5xxErrors)的所有實例,將會被移除連接池3分鐘(baseEjectionTime)”。
應用該規則,命令如下:
- $ kubectl apply -f destination-rule-all.yaml
之后可通過壓測工具(與限流方式類似),測試觸發熔斷規則的情況。具體查看方式如下:
- # kubectl exec -it $FORTIO_POD -c istio-proxy -- sh -c 'curl localhost:15000/stats' | grep micro-pay | grep outlier
如觸發成功,則可以查看到的信息如下:
- cluster.outbound|18888||micro-pay.default.svc.cluster.local.outlier_detection.ejections_active: 1
- cluster.outbound|18888||micro-pay.default.svc.cluster.local.outlier_detection.ejections_consecutive_5xx: 0
- cluster.outbound|18888||micro-pay.default.svc.cluster.local.outlier_detection.ejections_detected_consecutive_5xx: 2
- cluster.outbound|18888||micro-pay.default.svc.cluster.local.outlier_detection.ejections_detected_consecutive_gateway_failure: 0
- cluster.outbound|18888||micro-pay.default.svc.cluster.local.outlier_detection.ejections_detected_consecutive_local_origin_failure: 0
- cluster.outbound|18888||micro-pay.default.svc.cluster.local.outlier_detection.ejections_detected_failure_percentage: 0
- cluster.outbound|18888||micro-pay.default.svc.cluster.local.outlier_detection.ejections_detected_local_origin_failure_percentage: 0
- cluster.outbound|18888||micro-pay.default.svc.cluster.local.outlier_detection.ejections_detected_local_origin_success_rate: 0
- cluster.outbound|18888||micro-pay.default.svc.cluster.local.outlier_detection.ejections_detected_success_rate: 0
- cluster.outbound|18888||micro-pay.default.svc.cluster.local.outlier_detection.ejections_enforced_consecutive_5xx: 0
- cluster.outbound|18888||micro-pay.default.svc.cluster.local.outlier_detection.ejections_enforced_consecutive_gateway_failure: 0
- cluster.outbound|18888||micro-pay.default.svc.cluster.local.outlier_detection.ejections_enforced_consecutive_local_origin_failure: 0
- cluster.outbound|18888||micro-pay.default.svc.cluster.local.outlier_detection.ejections_enforced_failure_percentage: 0
- cluster.outbound|18888||micro-pay.default.svc.cluster.local.outlier_detection.ejections_enforced_local_origin_failure_percentage: 0
- cluster.outbound|18888||micro-pay.default.svc.cluster.local.outlier_detection.ejections_enforced_local_origin_success_rate: 0
- cluster.outbound|18888||micro-pay.default.svc.cluster.local.outlier_detection.ejections_enforced_success_rate: 0
- cluster.outbound|18888||micro-pay.default.svc.cluster.local.outlier_detection.ejections_enforced_total: 1
- cluster.outbound|18888||micro-pay.default.svc.cluster.local.outlier_detection.ejections_overflow: 0
- cluster.outbound|18888||micro-pay.default.svc.cluster.local.outlier_detection.ejections_success_rate: 0
- cluster.outbound|18888||micro-pay.default.svc.cluster.local.outlier_detection.ejections_total: 0
具體的觸發需要模擬上游服務失敗的情況,可以通過編寫錯誤代碼的方式進行模擬!
后記
本文從原理到實踐比較詳細地介紹了以Istio為代表的Service Mesh微服務架構實現熔斷、限流的基本方法。希望本文可以幫助各位老鐵進一步理解服務網格的架構內涵,并打開大家學習Service Mesh微服務架構的大門!