性能優化:關于緩存的一些思考
利用緩存做性能優化的案例非常多,從基礎的操作系統到數據庫、分布式緩存、本地緩存等。 它們表現形式各異,卻有著共同的樸素的本質: 彌補CPU的高算力和IO的慢讀寫之間巨大的鴻溝。
和架構選型類似,每引入一個組件,都會導致復雜度的上升。以緩存為例,它帶來性能提升的同時,也帶來一些問題,需要開發者設計和權衡。
本文的思維脈絡如下:
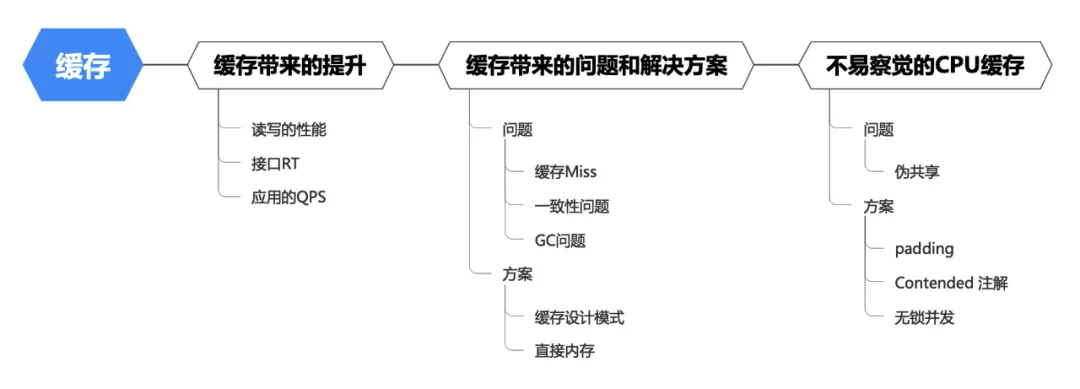
一、緩存和多級緩存
1.緩存的引入
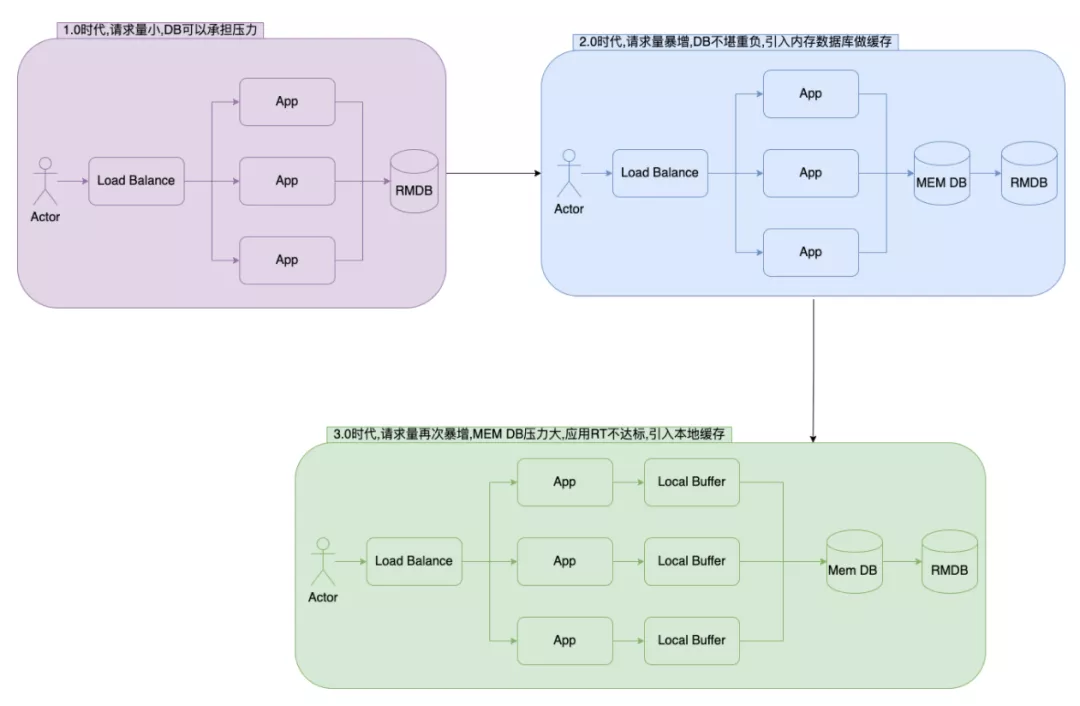
在初期業務量小的時候,數據庫能承擔讀寫壓力,應用可以直接和DB交互,架構簡單且強壯。
經過一段時間發展后,業務量迎來了大規模增長,此時DB查詢壓力和耗時都在增長。此時引入分布式緩存,在減少DB壓力的同時,還提供了更高的QPS。
再往后發展,分布式緩存也成為了瓶頸,高頻的QPS是一筆負擔;另外緩存驅逐以及網絡抖動會影響系統的穩定性,此時引入本地緩存,可以減輕分布式緩存的壓力,并減少網絡以及序列化開銷。
2.讀寫的性能提升
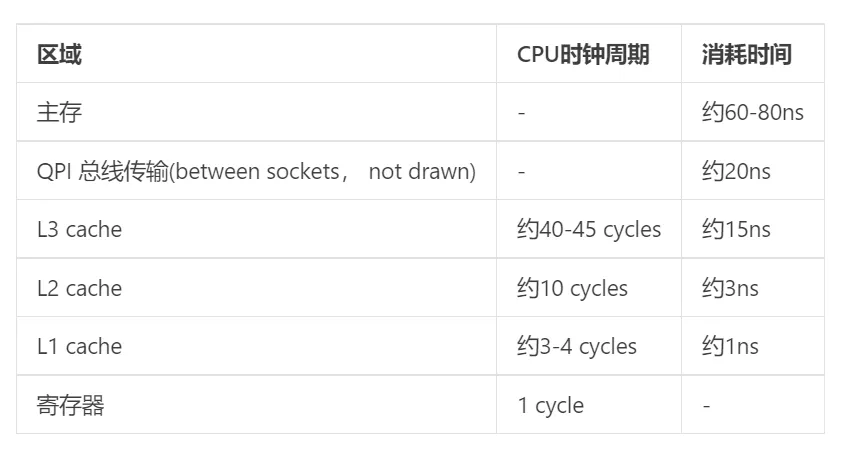
緩存通過減少IO操作來獲得讀寫的性能提升。有一個表格,可以看見磁盤、網絡的IO操作耗時,遠高于內存存取。
-
讀優化:當請求命中緩存后,可直接返回,從而略過IO讀取,減小讀的成本。
-
寫優化 : 將寫操作在緩沖中合并,讓IO設備可以批量處理,減小寫的成本。

緩存帶來的QPS、RT提升比較直觀,不補充介紹。
3.緩存Miss
緩存Miss是必然會面對的問題,緩存需保證在有限的容量下,將熱點的數據維護在緩存中,從而達到性能、成本的平衡。
緩存通常使用LRU算法淘汰近期不常用的Key。
近似LRU
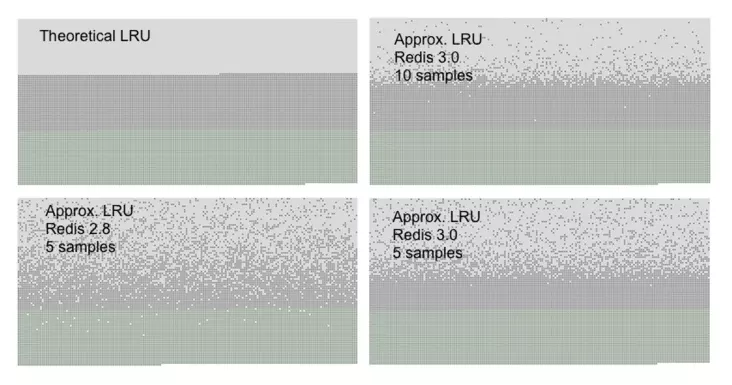
可以先試想嚴格LRU的實現。假設Redis當前有50W規模的key,先通過Keys 遍歷獲得所有Key,然后比對出空閑時間最長的某個key,最后執行淘汰。這樣的流程下來,是非常昂貴的,Keys命令是一筆不小的開銷,其次大規模執行比對也很昂貴。
當然嚴格LRU實現的優化空間還是有的,YY一下,可以通過活躍度分離出活躍Key和待回收Key, 淘汰時只關注待回收key即可;回收算法引入鏈表或者樹的結構,使Key按空閑時間有序,淘汰時直接獲取。然而這些優化不可避免的是,在緩存讀寫時,這些輔助的數據結構需要同步更新,帶來的存儲以及計算的成本很高。
在Redis中它采用了近似LRU的實現,它隨機采樣5個Key,淘汰掉其中空閑時間最長的那個。近似LRU實現起來更簡單、成本更低,在效果上接近嚴格LRU。它的缺點是存在一定的幾率淘汰掉最近被訪問的Key,即在TTL到期前也可能被淘汰。
避免短期大量失效
在一些場景中,程序是批量加載數據到緩存的, 比如通過Excel上傳數據,系統解析后,批量寫入DB和緩存。此時若不經設計,這批數據的超時時間往往是一致的。緩存到期后,本該緩存承擔的流量將打到DB上,從而降低接口甚至系統的性能和穩定性。
可以利用隨機數打散緩存失效時間,例如設置TTL=8hr+random(8000)ms。
4.緩存一致性
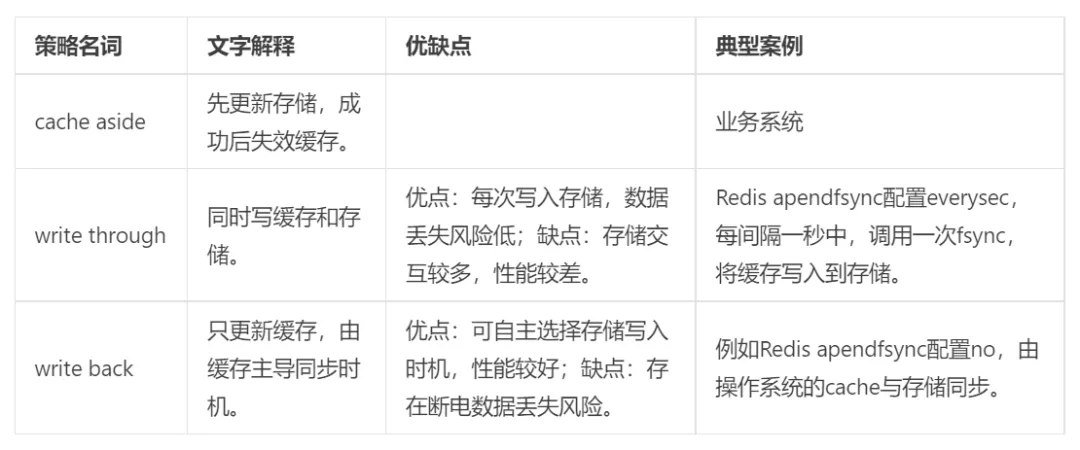
系統應盡量保證DB、緩存的數據一致性,較常使用的是cache aside設計模式。
避免使用非常規的緩存設計模式:先更新緩存、后更新DB;先更新DB、后更新緩存(cache aside是直接失效緩存)。這些模式的不一致風險較高。
緩存設計模式
業務系統通常使用cache aside 模式,操作系統、數據庫、分布式緩存等會使用write throgh、write back。
cache aside的緩存不一致
Cache aside模式大部分時間運行良好,在一些極端場景下,仍可能出現不一致風險。主要來自兩方面:
-
由于中間件或者網絡等問題,緩存失效失敗。
-
出現意外的緩存失效、讀取的時序。
緩存失效失敗很容易理解,不做補充。主要介紹時序引起的不一致問題。
考慮這樣的時間軸,A線程發現cache miss后重新加載緩存,此時讀的數據還是老的, 另一個線程B更新數據并失效緩存。若B線程失效緩存的操作完成時間早于A線程,A線程會寫入老的數據。
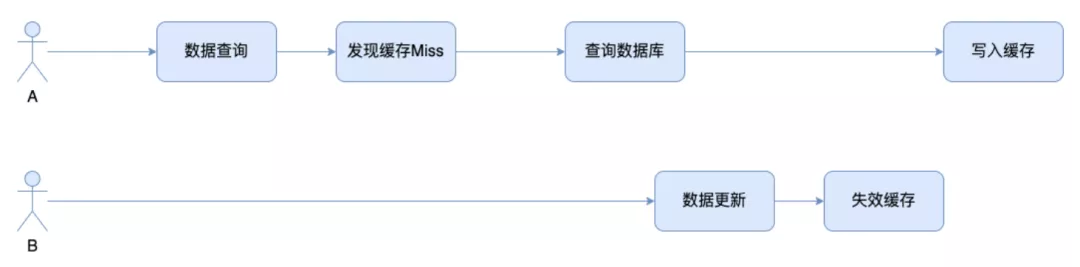
緩存不一致有一些緩解方法,例如延遲雙刪、CDC同步。這些方案都提升了系統復雜度,需綜合考慮業務的容忍度,方案的復雜度等。
-
延遲雙刪:主線程失效緩存后,將失效指令放入延時隊列,另一個線程輪詢隊列獲取指令并執行。
-
CDC同步:通過canal訂閱MySQL binlog的變更,上報給Kafka,系統監聽Kafka消息觸發緩存失效。
二、從堆內存到直接內存
1.直接內存的引入
Java本地緩存分兩類,基于堆內存的、基于直接內存的。
采用堆內存做緩存的主要問題是GC,由于緩存對象的生命周期往往較長,需要通過Major GC進行回收。若緩存的規模很大,那么GC會非常耗時。
采用直接內存做緩存的主要問題是內存管理。程序需自主控制內存的分配和回收,存在OOM或者Memory Leak的風險。另外直接內存不能存取對象,在操作時需進行序列化。
直接內存能減少GC壓力,因為它只需要保存直接內存的引用,而對象本身是存儲在直接內存中。引用晉升到老年代后占用的空間很小,對GC的負擔可忽略。
直接內存的回收依賴System。gc的調用,但這個調用JVM不保證執行、也不保證何時執行,它的行為是不可控的。程序一般需要自行管理,成對去調用malloc、free,依托于這種“手工、類C”的內存管理,可以增加內存回收的可控性和靈活性。
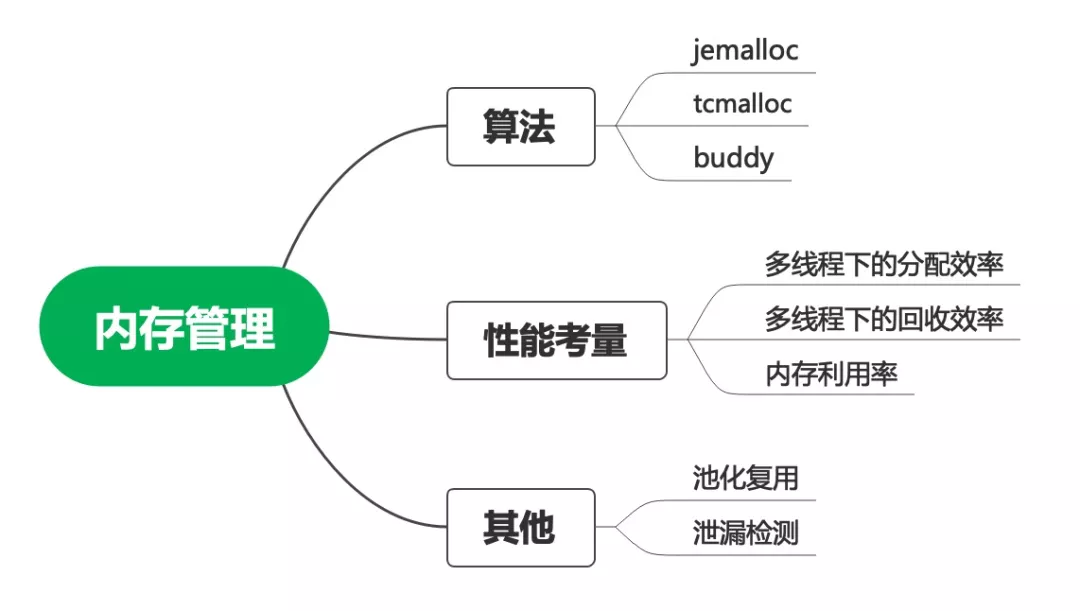
2.直接內存管理
由于直接內存的分配和回收比較昂貴,需要通過內核操作物理內存。申請的時候一般是申請大的內存快,然后再根據需求分配小塊給線程。回收的時候不直接釋放,而是放入內存池來重用。
如何快速找到一個空閑塊、如何減少內存碎片、如何快速回收等等,它是一個系統性的問題,也有很多專門的算法。
Jemalloc是綜合能力較好的算法,free BSD、Redis默認采用了該算法,OHC緩存也建議服務器配置該算法。Netty的作者實現了Java版本,感興趣的可以閱讀。
三、CPU緩存
利用上分布式緩存、本地緩存之后,還可以繼續提升的就是CPU緩存了。它雖不易察覺,但在高并發下對性能存在一定的影響。
CPU緩存分為L1、L2、L3 三級,越靠近CPU的,容量越小,命中率越高。當L3等級的緩存都取不到數據的時候,需從主存中獲取。
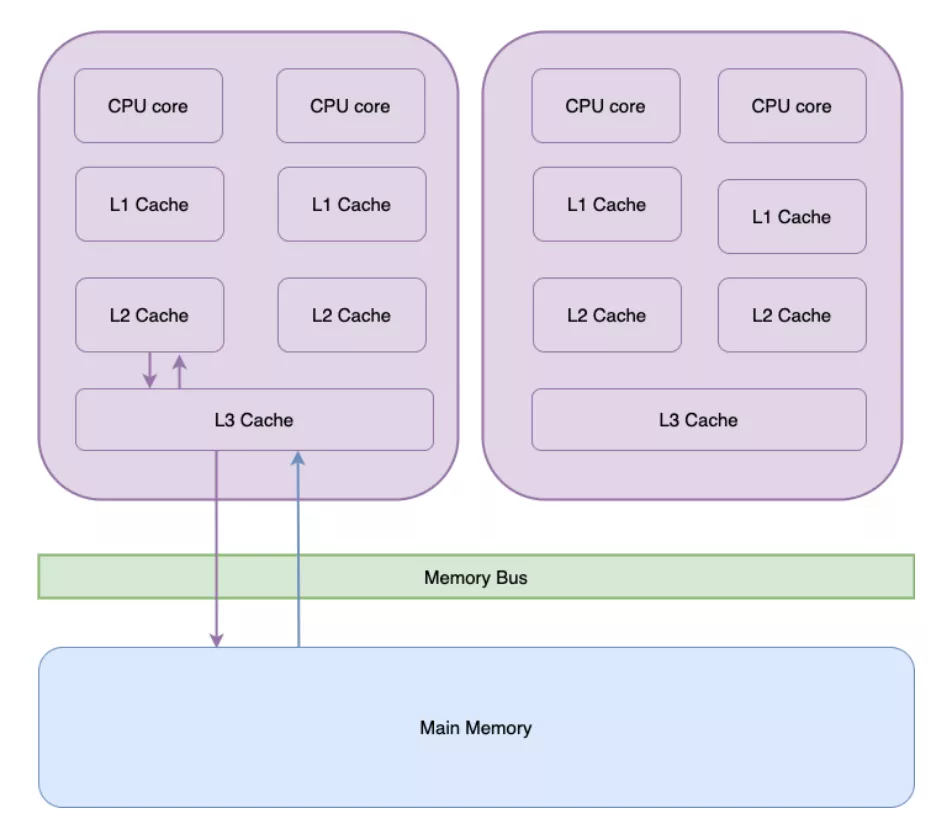
1.CPU cache line
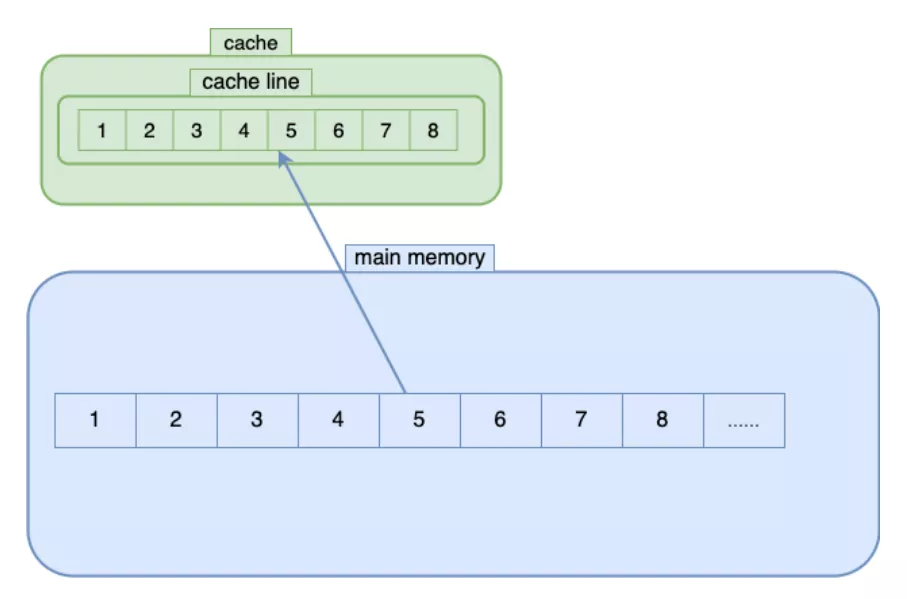
CPU緩存由cache line組成,每一個cache line為64字節,能容納8個long值。在CPU從主存獲取數據時,以cache line為單位加載,于是相鄰的數據會一并加載到緩存中。很容易想到,數組的順序遍歷、相鄰數據的計算是非常高效的。
2.偽共享 false sharing
CPU緩存也存在一致性問題,它通過MESI協議、MESIF協議來保證。
偽共享來源于高并發時cache line出現了緩存不一致。同一個cache line中的數據會被不同線程修改,它們相互影響,導致處理性能降低。
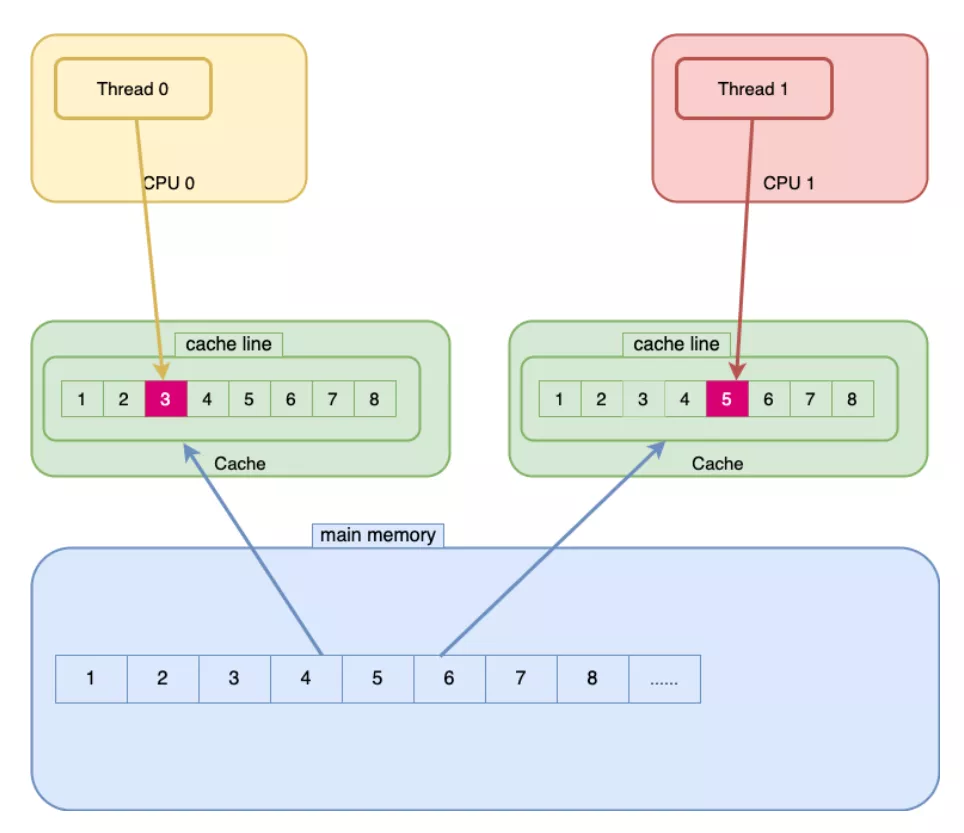
上圖模擬一個偽共享場景,NoPadding是線程共享對象,thread0會修改no0、thread1會修改no1。當thread0修改時,除了修改自身的cache line,依據CPU緩存協議還會導致thread1對應的cache line失效,這時thread1發現cache miss后從主存加載,修改后又導致thread0的cache line失效。
- NoPadding {
- long no0;
- long no1;
- }
3.偽共享解決方案
padding
通過填充,讓no0、no1落在不同的cache line中:
- Padding {
- long p1, p2, p3, p4, p5, p6, p7;
- volatile long no0 = 0L;
- long p9, p10, p11, p12, p13, p14;
- volatile long no1 = 0L;
- }
案例:jctools
Contended 注解
委托JVM填充cache line:
- @sun.misc.Contended static final class CounterCell {
- volatile long value;
- CounterCell(long x) { value = x; }
- }
案例:JDK源碼中LongAdder中的Cell、ConcurrentHashMap的CounterCell。
無鎖并發
無鎖并發可以從本質上解決偽共享問題,它無需填充cache line,并且執行效率是最高的。
案例:disruptor
四、總結
近來由于業務對接口RT提出了更高的要求,在性能優化的過程中,緩存的使用是非常多的。借此機會記錄下在這段時間的思考。私以為,在引入某一項技術的時候,需整體的去看,了解其概念、原理、適用場景、注意事項,這樣可以在設計之初就規避掉一些風險。
分布式緩存、本地緩存、CPU緩存涵蓋的內容非常多,本文做了一些歸納。對細節感興趣的同學可以閱讀《Redis 設計與實現》、disruptor設計文檔及代碼。