引言
一直以來,人們試圖手工編寫算法來理解人工生成的內容,但是成功率極低。例如,計算機很難“掌握”圖像的語義內容。對于這類問題,AI科學家已經嘗試通過分析汽車、貓、外套等低級像素來解決,但結果并不理想。盡管顏色直方圖和特征檢測器在一定程度上發(fā)揮了作用,但在大多數實際應用中它們的準確率仍然極低。
在過去十年中,大數據和深度學習的結合從根本上改變了我們處理計算機視覺、自然語言處理和其他機器學習(ML)應用程序的方式。例如,從垃圾郵件檢測到真實的文本再到視頻合成等任務都取得了驚人的進步,在這些具體應用中準確率指標已經達到了超人的水平。但是,這些改進伴隨而來的一個顯著的副作用是嵌入向量的使用增加,即通過在深度神經網絡中獲取中間結果而產生的模型組件。OpenAI相關的Web頁面上提供了下面這樣一段比較貼切的概述:
“嵌入是一種特殊的數據表示格式,無論機器學習模型還是相關算法都很容易使用它。嵌入是文本語義的信息密集表示。每個嵌入都可以表示為一個浮點數向量;因此,向量空間中兩個嵌入之間的距離與原始格式中兩個輸入之間的語義相似性是相關的。例如,如果兩個文本相似,那么它們的向量表示也應該相似。”
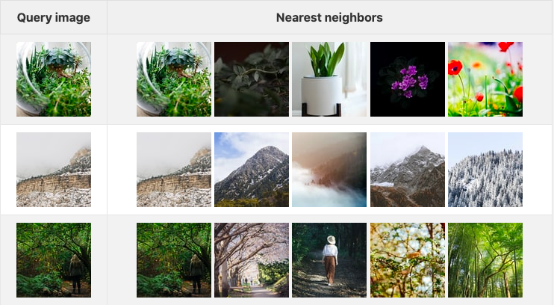
下表顯示了三個查詢圖像以及它們在嵌入空間中對應的前五個圖像。在此,我使用了Unsplash Lite網站提供的前1000個圖像作為數據集。

訓練嵌入任務的新模型
從理論上講,訓練一個新的ML模型并生成嵌入聽起來很簡單:采用最新的體系結構支持的預構建模型,并用一些數據對其進行訓練。
從表面上看,使用最新的模型架構似乎很容易達到最先進的效果。然而,這與事實相距甚遠。下面,不妨讓我們先回顧一下與訓練嵌入模型相關的一些常見陷阱(這些也適用于一般的機器學習模型):
1. 數據不足:在沒有足夠數據的情況下從頭開始訓練一個新的嵌入模型,這容易導致一種稱為過度擬合的現象。事實上,只有最大的全球性組織才有足夠的數據讓訓練從零開始成為一種新模型;其他公司或者個人則必須依靠反復微調。這種微調實際上對應一個過程;在這個過程中,一般都是基于一個已經訓練過的包含大量數據的模型,并在此基礎上使用一個較小的數據集進行不斷的提取操作。
2. 超參數選擇不當:超參數是用于控制訓練過程的常數,例如模型學習的速度或單個批次中用于訓練的數據量。在微調模型時,選擇一組合適的超參數非常重要,因為對特定值的微小更改可能會導致截然不同的結果。近期研究表明,ImageNet-1k的精度提高了5%以上(這是很大的),這一成果是通過改進訓練程序并從頭開始訓練同一模型實現的。
3. 高估自我監(jiān)督模型:自我監(jiān)督(self-supervision)一詞指的是一種訓練過程,其中輸入數據的“基礎”是通過利用數據本身而不是標簽來學習的。一般來說,自監(jiān)督方法非常適合預訓練(在使用較小的標記數據集對模型進行微調之前,使用大量未標記數據以自監(jiān)督方式訓練模型),但直接使用自監(jiān)督嵌入可能會導致次優(yōu)性能。
4. 解決上述三個問題的一種常見方法是,在根據標記數據微調模型之前,使用大量數據訓練自監(jiān)督模型。這已經被證明對NLP非常有效,但對CV(計算機視覺)并不是很有效。

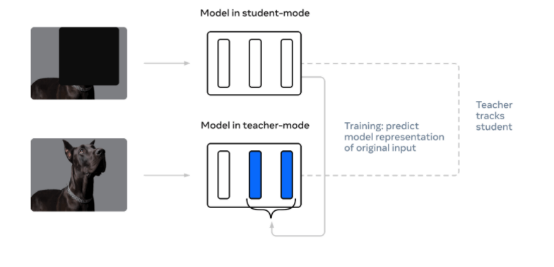
這里展示的是Meta公司的data2vec訓練技術的例子。這是一種自我監(jiān)督的方法,用于跨各種非結構化數據類型訓練深層神經網絡。(來源:元人工智能博客)
使用嵌入模型的缺陷
在訓練嵌入模型的過程中經常出現一些相關的常見錯誤。常見的情況是,許多希望使用嵌入的開發(fā)人員會立即在學術類數據集上使用預先訓練好的模型,例如ImageNet(用于圖像分類)和SQuAD(用于問答)。然而,盡管目前存在大量經過預訓練的模型可用,但要獲得最大的嵌入性能,還是應該避免以下陷阱:
1. 訓練和推理數據不匹配:使用由其他組織訓練的現成模型已成為開發(fā)ML應用程序的一種流行方式,而無需再耗費數千個GPU/TPU小時去重復訓練。理解特定嵌入模型的局限性,以及它如何影響應用程序性能,這一點是非常重要的;如果不了解模型的訓練數據和方法,則很容易誤解結果。例如,訓練嵌入音樂的模型在應用于實際的語音應用程序時往往效果不佳;反之,亦然。
2. 層選擇不當:當使用完全監(jiān)督的神經網絡作為嵌入模型時,特征通常取自激活的第二到最后一層(一般稱為倒數第二層)。但是,這可能會導致性能不理想;當然,具體情形還要取決于實際的應用程序。例如,當使用經過圖像分類訓練的模型嵌入徽標和/或品牌的圖像時,使用早期激活可能會提高性能。這是因為這種方案更好地保留了對那些并不是很復雜的圖像分類至關重要的一些低級特征(邊和角)。
3. 不相同的推理條件:為了從嵌入模型中提取最大性能,訓練和推理條件必須相同。實際上,情況往往并非如此。例如,在使用TorchVision的標準resnet50模型的過程中,當使用雙三次插值和最近鄰插值進行下采樣(downsample)時,會生成兩個完全不同的結果(見下文)。
BICUBIC INTERPOLATION | NEAREST INTERPOLATION | |
預測類 | coucal | robin, American robin, Turdus migratorius |
概率 | 27.28% | 47.65% |
嵌入向量 | [0.1392, 0.3572, 0.1988, ..., 0.2888, 0.6611, 0.2909] | [0.3463, 0.2558, 0.5562, ..., 0.6487, 0.8155, 0.3422] |
部署嵌入模型
一旦你順利通過前面的訓練并克服與驗證模型相關的所有障礙,那么,接下來的一個關鍵步驟就是擴展和部署程序。但嵌入模型部署說起來容易,做起來卻非易事。MLOps是與DevOps相關的一個領域,專門用于實現這一目的。
1. 選擇合適的硬件:嵌入模型與大多數其他ML模型類似,可以在各種類型的硬件上運行,從標準的日常CPU到可編程邏輯(FPGA)。幾乎所有的網站上發(fā)布的研究論文都集中在分析成本與效率之間的權衡,并強調大多數組織在解決這方面問題時所面臨的困難。
2. 模型部署方面已經有許多現成的MLOP和分布式計算平臺(包括許多開源平臺)可用。不過,弄清楚這些內容的工作邏輯并搞清它們如何適合您的應用程序本身就是一個挑戰(zhàn)。
3. 嵌入向量的存儲方案:隨著應用程序的擴展,您需要為嵌入向量找到一個可擴展且更持久的存儲解決方案。這正是矢量數據庫出現的原因。
一切由我自己來做!
如果真是這樣,請記住幾件至關重要的事情:
首先,ML與軟件工程非常不同:傳統(tǒng)的機器學習起源于統(tǒng)計學,這是一個與軟件工程非常不同的數學分支。正則化和特征選擇等重要的機器學習概念在數學中有很強的基礎。雖然用于訓練和推理的現代庫使得訓練和生成嵌入模型變得非常容易,但了解不同的超參數和訓練方法如何影響嵌入模型的性能仍然至關重要。
其次,學習使用PyTorch或Tensorflow等框架可能并不簡單。的確,這些庫大大加快了現代ML模型的訓練、驗證和部署;而且,另一方面,對于經驗豐富的ML開發(fā)人員或熟悉HDL的程序員來說,構建新模型或實現現有模型也是很直觀的。但是,盡管如此,對于大多數軟件開發(fā)人員來說,此領域涉及的基本概念本身可能就很難掌握。當然,還有一個問題就是選擇哪個框架的問題,因為這兩個框架使用的執(zhí)行引擎存在很多不同(我推薦你使用PyTorch)。
最后,找到一個適合你的代碼庫的MLOps平臺也需要時間。總之,有數百種不同的選擇可供你選擇。當然,僅僅評估每種選擇方案的利弊本身就可能是一個長達數年的研究項目。
說到這里,我不建議你學習ML和MLOps;因為這是一個相對漫長而乏味的過程,可能會從你手頭最重要的事情上爭奪時間。
用Towhee加速數據科學應用開發(fā)
Towhee是一個開源項目,旨在幫助軟件工程師開發(fā)和部署只需幾行代碼就可以利用嵌入模型的應用程序。Towhee項目為軟件開發(fā)人員提供了構建其ML應用程序的自由和靈活性,而無需深入嵌入模型和機器學習。
一個簡單的例子
一個管道(Pipeline)是由多個子任務(在Towhee中也稱為操作符)組成的單個嵌入生成任務。通過在管道中抽象整個任務,Towhee可以幫助用戶避免上面提到的許多嵌入生成時遇到的許多陷阱。
>>> from towhee import pipeline
>>> embedding_pipeline = pipeline('image-embedding-resnet50')
>>> embedding = embedding_pipeline('https://docs.towhee.io/img/logo.png')
在上面的例子中,圖像解碼、圖像變換、特征提取和嵌入規(guī)范化是編譯到單個管道中的四個子步驟——開發(fā)人員無需擔心模型和推理細節(jié)。此外,Towhee還為各種任務提供預構建的嵌入管道,包括音頻/音樂嵌入、圖像嵌入、面部嵌入等。
方法鏈式API調用
Towhee還提供了一個名為DataCollection的Python非結構化數據處理框架。簡而言之,DataCollection是一種方法鏈接式API,它允許開發(fā)人員在真實數據上快速原型化嵌入和其他ML模型。在下面的示例中,我們使用resnet50嵌入模型來使用DataCollection計算嵌入。
在本例中,我們將構建一個簡易應用程序。此程序中,我們可以使用1位數字3來過濾素數:
>>> from towhee.functional import DataCollection
>>> def is_prime(x):
... if x <= 1:
... return False
... for i in range(2, int(x/2)+1):
... if not x % i:
... return False
... return True
...
>>> dc = (
... DataCollection.range(100)
... .filter(is_prime) #第一階段:查找素數
... .filter(lambda x: x%10 == 3) #第二階段:查找以3結尾的素數
... .map(str) #第二階段:轉換成字符串
... )
...
>>> dc.to_list()
借助DataCollection,你可以使用僅僅一行代碼來開發(fā)整個應用程序。例如,下面內容中將向你展示如何開發(fā)一個反向圖像搜索應用程序。
Towhee訓練
如上所述,完全或自我監(jiān)督的訓練模型通常擅長用于完成一般性任務。然而,有時你會想要創(chuàng)建一個嵌入模型,它擅長于某些特定的東西,例如區(qū)分貓和狗。為此,Towhee專門提供了一個訓練/微調框架:
>>> from towhee.trainer.training_config import TrainingConfig
>>> training_config = TrainingConfig(
... batch_size=2,
... epoch_num=2,
... output_dir='quick_start_output'
... )
您還需要指定一個要訓練的數據集:
>>> train_data = dataset('train', size=20, transform=my_data_transformer)
>>> eval_data = dataset('eval', size=10, transform=my_data_transformer)一切就緒后,從現有操作符訓練一個新的嵌入模型就是小菜一碟了:
>>> op.train(
... training_config,
... train_dataset=train_data,
... eval_dataset=eval_data
... )
一旦完成上面代碼后,您可以在應用程序中使用相同的運算符,而無需更改其余代碼。


上圖中顯示的是一幅嵌入模型試圖編碼的圖像核心區(qū)域的注意力熱圖。在Towhee的未來版本中,我們會直接將注意力熱圖和其他可視化工具集成到我們的微調框架中。
示例應用程序:反向圖像搜索
為了演示如何使用Towhee,讓我們快速構建一個小型反向圖像搜索應用程序。反向圖像搜索是眾所周知的。所以,我們不再贅述有關細節(jié),而是直接切入主題:
>>> import towhee
>>> from towhee.functional import DataCollection
我們將使用一個小數據集和10個查詢圖像。程序中,我們使用DataCollection實現加載數據集和查詢圖像:
>>> dataset = DataCollection.from_glob('./image_dataset/dataset/*.JPEG').unstream()
>>> query = DataCollection.from_glob('./image_dataset/query/*.JPEG').unstream()下一步是在整個數據集集合上計算嵌入:
>>> dc_data = (
... dataset.image_decode.cv2()
... .image_embedding.timm(model_name='resnet50')
... )
...
這一步創(chuàng)建了一組局部的嵌入向量——每個向量對應于數據集中的一個圖像。現在階段,我們就可以查詢最近的鄰居數據了:
>>> result = (
... query.image_decode.cv2() #解碼查詢集中的所有圖像
... .image_embedding.timm(model_name='resnet50') #使用'resnet50'嵌入模型計算嵌入
... .towhee.search_vectors(data=dc_data, cal='L2', topk=5) #搜索數據集
... .map(lambda x: x.ids) #獲取類似結果的ID(文件路徑)
... .select_from(dataset) #獲取結果圖像
... )
...
此外,我們還提供了一種使用Ray框架部署應用程序的方法。為此,你只需要調用一下命令query.set_engine('ray'),其他一切就好辦了!
總結
最后,我們不認為Towhee項目是一個成熟的端到端模型服務或MLOps平臺,而且這也不是我們打算實現的目標。相反,我們的目標是加速需要嵌入和其他ML任務的應用程序的開發(fā)。不過,借助Towhee開源項目,我們希望能夠在本地機器(Pipeline+Trainer)上實現嵌入模型和管道的快速原型化,特別是只需幾行代碼就可以開發(fā)以ML為中心的應用程序(數據收集),并允許輕松快速地部署到集群(通過Ray框架)上。
譯者介紹
朱先忠,51CTO社區(qū)編輯,51CTO專家博客、講師,濰坊一所高校計算機教師,自由編程界老兵一枚。早期專注各種微軟技術(編著成ASP.NET AJX、Cocos 2d-X相關三本技術圖書),近十多年投身于開源世界(熟悉流行全棧Web開發(fā)技術),了解基于OneNet/AliOS+Arduino/ESP32/樹莓派等物聯(lián)網開發(fā)技術與Scala+Hadoop+Spark+Flink等大數據開發(fā)技術。
原文標題:Making Machine Learning More Accessible for Application Developers,作者:Frank Liu
鏈接:https://dzone.com/articles/making-machine-learning-more-accessible-for-applic-1