你寫的ML代碼占多少內存?這件事很重要,但很多人還不懂
在進行機器學習任務時,你需要學會使用代碼快速檢查模型的內存占用量。原因很簡單,硬件資源是有限的,單個機器學習模塊不應該占用系統的所有內存,這一點在邊緣計算場景中尤其重要。
比如,你寫了一個很棒的機器學習程序,或者搭建了一個不錯的神經網絡模型,然后想在某些 Web 服務或 REST API 上部署模型。或者你是基于工廠傳感器的數據流開發了模型,計劃將其部署在其中一臺工業計算機上。
這時,你的模型可能是硬件上運行的幾百個模型之一,所以你必須對內存占用峰值有所了解。否則多個模型同時達到了內存占用峰值,系統可能會崩潰。
因此,搞清楚代碼運行時的內存配置文件(動態數量)非常重要。這與模型的大小和壓縮均無關,可能是你事先已經將其保存在磁盤上的特殊對象,例如 Scikit-learn Joblib dump、Python Pickle dump,TensorFlow HFD5 等。
Scalene:簡潔的內存 / CPU/GPU 分析器
首先要討論的是 Scalene,它是一個 Python 的高性能 CPU 和內存分析器,由馬薩諸塞大學研發。其 GitHub 頁面是這樣介紹的:「 Scalene 是適用于 Python 的高性能 CPU、GPU 和內存分析器,它可以執行許多其他 Python 分析器無法做到的事情,提供詳細信息比其他分析器快幾個數量級。」
安裝
它是一個 Python 包,所以按照通常方法安裝:
- pip install scalene
這樣適用于 Linux OS,作者沒有在 Windows 10 上進行測試。
在 CLI 或 Jupyter Notebook 內部使用
Scalene 的使用非常簡單:
- scalene <yourapp.py>
也可以使用魔術命令在 Jupyter notebook 中使用它:
- %load_ext scalene
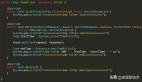
輸出示例
下面是一個輸出示例。稍后將對此進行更深入的研究。
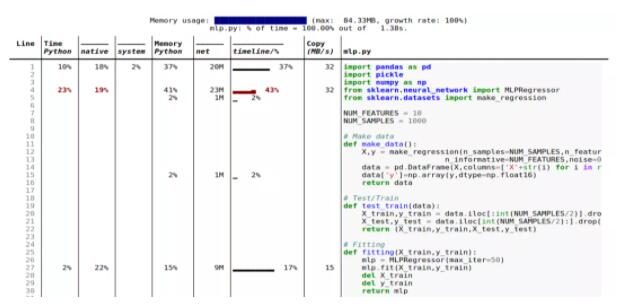
這些是 Scalene 一些很酷的功能:
- 行和函數:報告有關整個函數和每個獨立代碼行的信息;
- 線程:支持 Python 線程;
- 多進程處理:支持使用 multiprocessing 庫;
- Python 與 C 的時間:Scalene 用在 Python 與本機代碼(例如庫)上的時間;
- 系統時間:區分系統時間(例如,休眠或執行 I / O 操作);
- GPU:報告在英偉達 GPU 上使用的時間(如果有);
- 復制量:報告每秒要復制的數據量;
- 泄漏檢測:自動查明可能造成內存泄漏的線路。
ML 代碼具體示例
接下來看一下 Scalene 用于內存配置標準機器學習代碼的工作。對三個模型使用 Scikit-learn 庫,并利用其綜合數據生成功能來創建數據集。
對比的是兩種不同類型的 ML 模型:
- 多元線性回歸模型;
- 具有相同數據集的深度神經網絡模型。
線性回歸模型
使用標準導入和 NUM_FEATURES 、 NUM_SMPLES 兩個變量進行一些實驗。
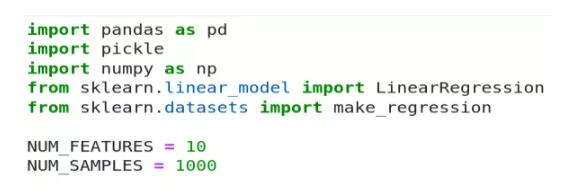
這里沒有展示數據生成和模型擬合代碼,它們是非常標準的。作者將擬合的模型另存為 pickled dump,并將其與測試 CSV 文件一起加載以進行推斷。

為了清晰起見,將所有內容置于 Scalene 執行和報告環境下循環運行。

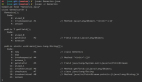
當運行命令時:
- $ scalene linearmodel.py --html >> linearmodel-scalene.html
將這些結果作為輸出。注意,此處使用了 --html 標志并將輸出通過管道傳輸到 HTML 文件,以便于報告。

令人驚訝的是,內存占用幾乎完全由外部 I / O(例如 Pandas 和 Scikit-learn estimator 加載)控制,少量會將測試數據寫到磁盤上的 CSV 文件中。實際的 ML 建模、Numpy、Pandas 操作和推理,根本不會影響內存。
我們可以縮放數據集大小(行數)和模型復雜度(特征數),并運行相同的內存配置文件以記錄各種操作在內存消耗方面的表現。結果顯示在這里。
此處,X 軸代表特征 / 數據點集。注意該圖描繪的是百分比,而不是絕對值,展示了各種類型操作的相對重要性。
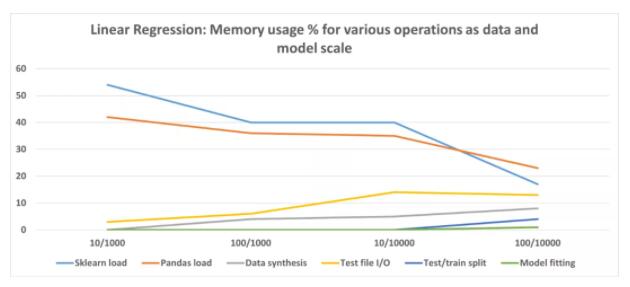
從這些實驗中得出的結論是,Scikit-learn 線性回歸估計非常高效,并且不會為實際模型擬合或推理消耗大量內存。
但就代碼而言,它確實有固定的內存占用,并在加載時會消耗大量內存。不過隨著數據大小和模型復雜性的增加,整個代碼占用百分比會下降。如果使用這樣的模型,則可能需要關注數據文件 I / O,優化代碼以獲得更好的內存性能。
深度神經網絡如何?
如果我們使用 2 個隱藏層的神經網絡(每個隱藏層有 50 個神經元)運行類似的實驗,那么結果如下所示。
代碼地址:https://github.com/tirthajyoti/Machine-Learning-with-Python/blob/master/Memory-profiling/Scalene/mlp.py
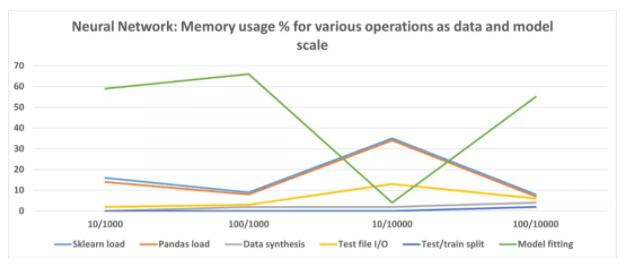
與線性回歸模型不同,神經網絡模型在訓練 / 擬合步驟中消耗大量內存。但是,由于特征少且數據量大,擬合占用的內存較少。此外,還可以嘗試各種體系結構和超參數,并記錄內存使用情況,達到合適的設置。
復現說明
如果你使用相同的代碼復現實驗,結果可能會因硬件、磁盤 / CPU / GPU / 內存類型的不同而大相徑庭。
一些關鍵建議
- 最好在代碼中編寫專注于單個任務的小型函數;
- 保留一些自由變量,例如特征數和數據點,借助最少的更改來運行相同的代碼,在數據 / 模型縮放時檢查內存配置文件;
- 如果要將一種 ML 算法與另一種 ML 算法進行比較,請讓整體代碼的結構和流程盡可能相同以減少混亂。最好只更改 estimator 類并對比內存配置文件;
- 數據和模型 I / O(導入語句,磁盤上的模型持久性)在內存占用方面可能會出乎意料地占主導地位,具體取決于建模方案,優化時切勿忽略這些;
- 出于相同原因,請考慮比較來自多個實現 / 程序包的同一算法的內存配置文件(例如 Keras、PyTorch、Scikitlearn)。如果內存優化是主要目標,那么即使在功能或性能上不是最佳,也必須尋找一種占用最小內存且可以滿意完成工作的實現方式;
- 如果數據 I / O 成為瓶頸,請探索更快的選項或其他存儲類型,例如,用 parquet 文件和 Apache Arrow 存儲替換 Pandas CSV。可以看看這篇文章:
《How fast is reading Parquet file (with Arrow) vs. CSV with Pandas?》
https://towardsdatascience.com/how-fast-is-reading-parquet-file-with-arrow-vs-csv-with-pandas-2f8095722e94
Scalene 能做的其他事
在本文中,僅討論了內存分析的一小部分,目光放在了規范機器學習建模代碼上。事實上 Scalene CLI 也有其他可以利用的選項:
- 僅分析 CPU 時間,不分析內存;
- 僅使用非零內存減少資源占用;
- 指定 CPU 和內存分配的最小閾值;
- 設置 CPU 采樣率;
- 多線程并行,隨后檢查差異。
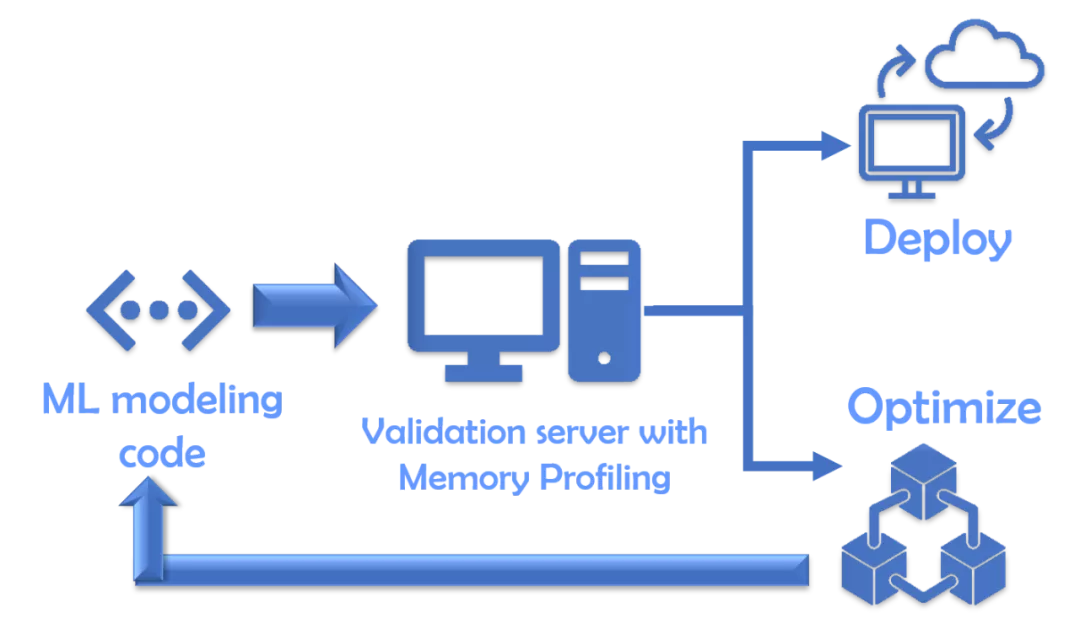
最終驗證(可選)
在資源較少的情況下,你最好托管一個驗證環境 / 服務器,該服務器將接受給定的建模代碼(如已開發),并通過這樣的內存分析器運行它以創建運行時統計信息。如果它通過內存占用空間的預定標準,則只有建模代碼會被接受用于進一步部署。
總結
在本文中,我們討論了對機器學習代碼進行內存配置的重要性。我們需要使其更好地部署在服務和機器中,讓平臺或工程團隊能夠方便運用。分析內存也可以讓我們找到更高效的、面向特定數據或算法的優化方式。
希望你能在使用這些工具和技術進行機器學習部署時能夠獲得成功。