這個登上Nature封面的群體學習,無需中央協調員比聯邦學習更優(yōu)秀
本文經AI新媒體量子位(公眾號ID:QbitAI)授權轉載,轉載請聯系出處。
如今,在一些疾病的診斷領域,AI的準確率已經超過了醫(yī)生。
靠譜的診斷結果背后,是建立海量數據集上的機器學習。
但實際上,可用于訓練的醫(yī)療數據非常分散,想要把世界各地的數據都集合起來又會引發(fā)對數據所有權、隱私性、保密性、安全性的擔憂,甚至數據壟斷的威脅……
常用的方法如聯邦學習,可以解決上述的一些問題,但該模型的參數由“中央協調員”( central coordinator)處理,造成了“權力”的集中,且它的星形架構也導致容錯性降低。
就沒有好的解決辦法嗎?
有,Nature封面為我們刊登了一種叫做Swarm Learning (群體學習,SL)的全新機器學習方法!

該方法結合了邊緣計算、基于區(qū)塊鏈的對等網絡,無需“中央協調員”,超越了聯邦學習,可以在不違反隱私法的情況下集合來自世界各地的任何醫(yī)療數據。
研究人員用了四個異質性疾病 (結核病、COVID-19、白血病和肺部病變),來驗證了Swarm Learning方法使用分布式數據來診斷疾病的可行性。
具體如何實現?
群體學習方法采用去中心化的架構,用私人許可的區(qū)塊鏈技術實現。
整個Swarm網絡由多個Swarm邊緣節(jié)點組成,節(jié)點之間通過該網絡來共享參數,每個節(jié)點使用私有數據和網絡提供的模型來訓練自己的模型。
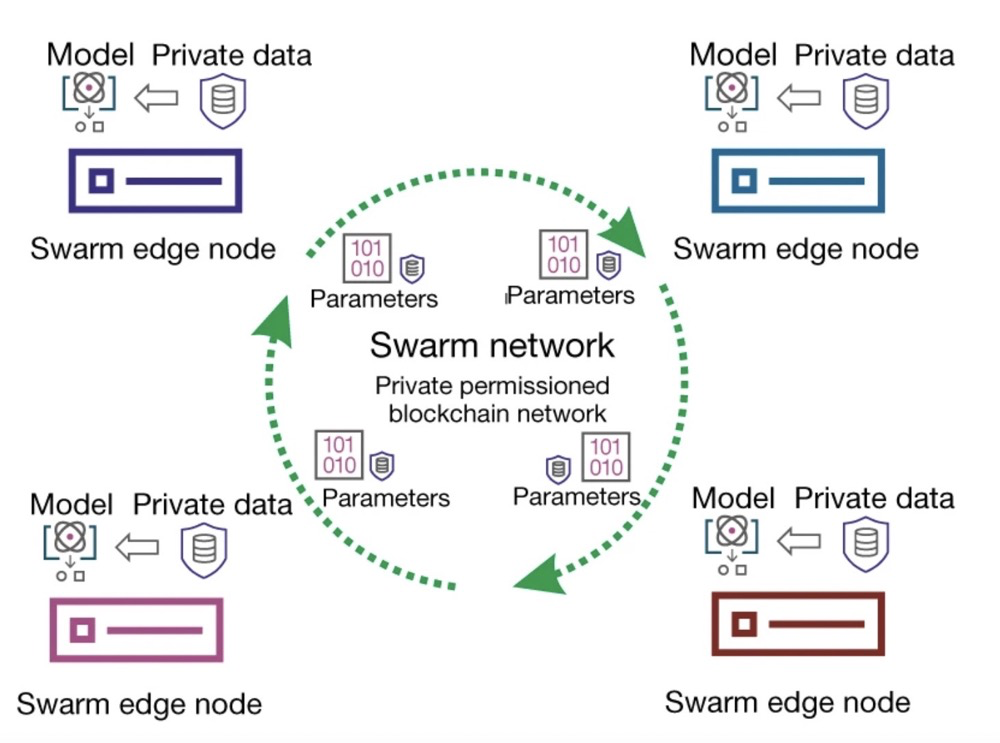
該方法提供安全措施,以支持通過私有許可區(qū)塊鏈技術保證數據的所有權、安全性和機密性。
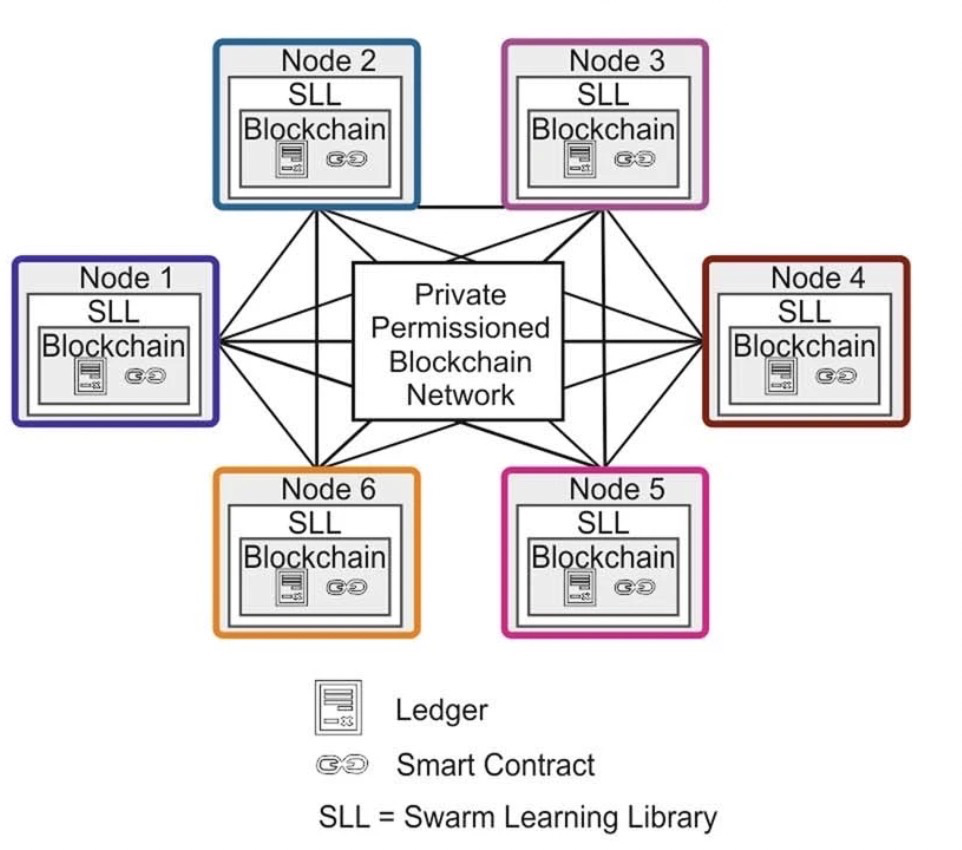
其中,只有預先授權的參與者才能加入,且新節(jié)點的加入是動態(tài)的,通過適當的授權措施來識別參與者,并通過區(qū)塊鏈智能合約注冊,讓參與者獲得模型,執(zhí)行本地模型訓練。
直到本地模型訓練到滿足定義的同步條件后,才可以通過Swarm的API交換模型參數,并在新一輪訓練開始之前,合并新的參數配置來更新模型。
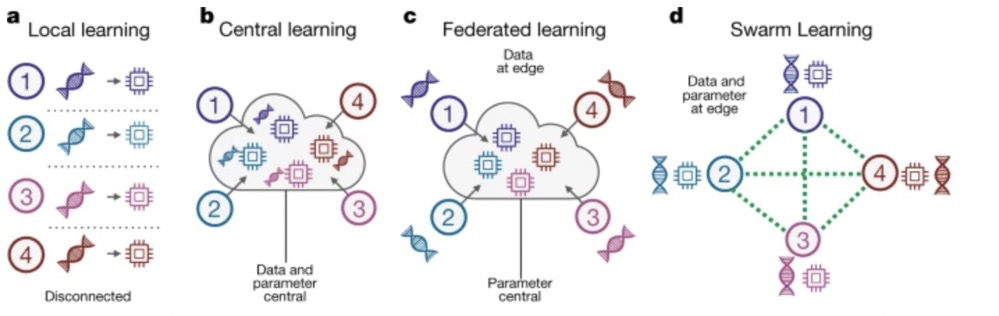
△ 群體學習與其他機器學習方法的架構對比
因此該群體學習方法具有以下特點:
- 可以將數據所有者的醫(yī)療數據保存在本地;
- 不需要交換原始數據,因此可減少數據流量(data traffic);
- 可以提供高水平地數據安全保護;
- 無需中央管理員就可保證分散成員安全、透明和公平地加入;
- 允許所有成員同等權利地合并參數;
- 保護機器學習模型免受攻擊。
為了驗證該方法基于分布式數據開發(fā)診斷疾病功能的可行性,研究人員用它來診斷四種疾病。
區(qū)分輕度和重度 COVID-19 ,表現優(yōu)于單個節(jié)點
首先是白血病。
研究人員將超過12000多個的樣本數據“孤立”到各個節(jié)點,以模擬中現實世界中分布在世界各地的醫(yī)療中心。
再用群體學習訓練這些數據再去診斷未知病人,他們發(fā)現,無論如何改變各個節(jié)點的樣本分布情況,群體學習方法的診斷準確率均優(yōu)于單個節(jié)點。
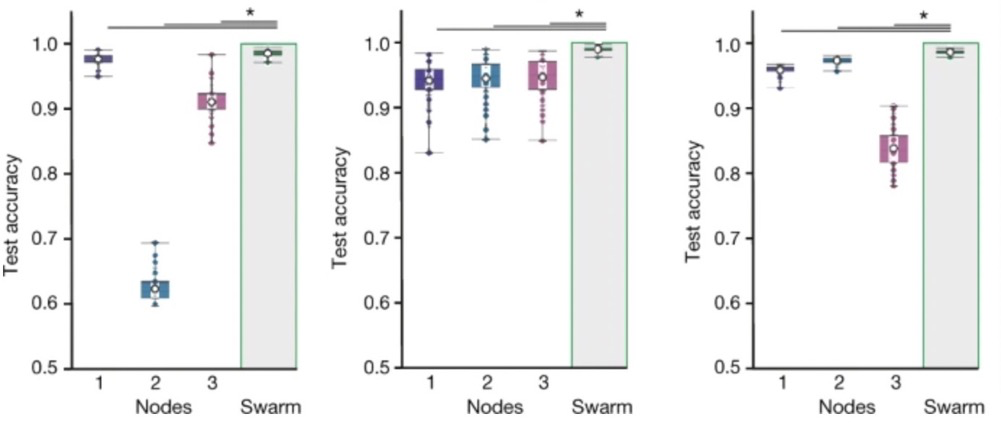
接著使用群體學習識別結核病或肺部病變患者,結果也是如此,且減少訓練樣本的數量以后,群體學習的預測效果雖然下降,但仍優(yōu)于任何一個單獨的節(jié)點。
緊跟疫情,研究人員也檢測了群體學習對于診斷新冠病毒的效果。
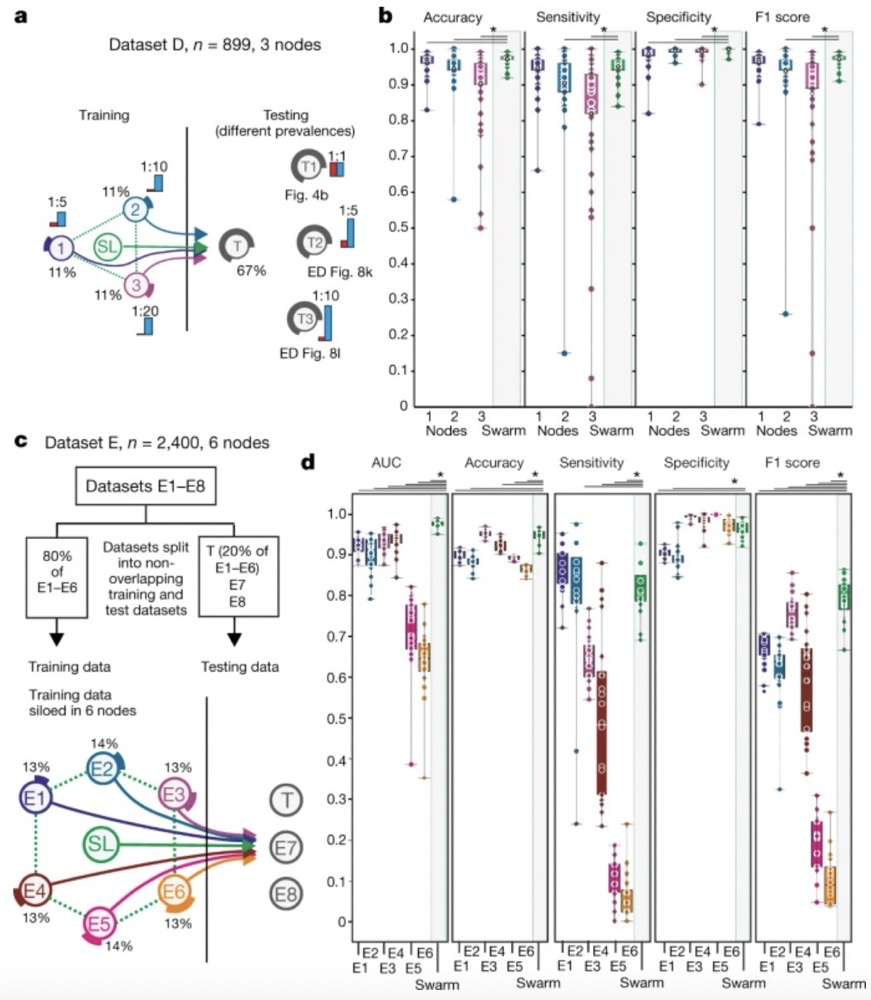
結果顯示,在區(qū)分輕度和重度 COVID-19 時,群體學習的表現優(yōu)于單個節(jié)點。
最后,研究人員表示,群體學習作為一個去中心化的學習方法,有望取代目前跨機構醫(yī)學研究中的數據共享模式,在保證數據隱私等方面的情況下,幫助AI獲得更豐富全面的數據,為AI診斷疾病提供更高的準確率。
論文地址:
https://www.nature.com/articles/s41586-021-03583-3
GitHub代碼:
https://github.com/schultzelab/swarm_learning