













Gartner APM 魔力象限技術解讀——全量存儲?No! 按需存儲?YES
調用鏈記錄了完整的請求狀態及流轉信息,是一座巨大的數據寶庫。但是,其龐大的數據量帶來的成本及性能問題是每個實際應用 Tracing 同學繞不開的難題。如何以最低的成本,按需記錄最有價值的鏈路及其關聯數據,是本文探討的主要話題。 核心關鍵詞是:邊緣計算 + 冷熱數據分離。 如果你正面臨全量存儲調用鏈成本過高,而采樣后查不到數據或圖表不準等問題,請耐心讀完本文,相信會給你帶來一些啟發。
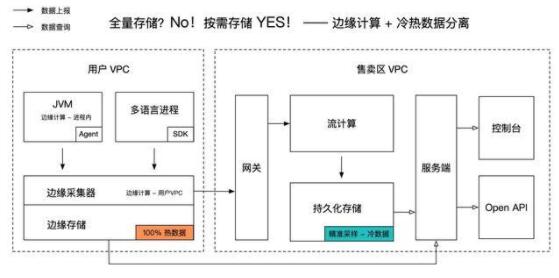
邊緣計算,記錄更有價值的數據
邊緣計算,顧名思義就是在邊緣節點進行數據計算,趕時髦的話也可以稱之為“計算左移”。在網絡帶寬受限,傳輸開銷與全局數據熱點難以解決的背景下, 邊緣計算是尋求成本與價值平衡最優解的一種有效方法。
Tracing 領域最常用的邊緣計算就是在用戶進程內進行數據過濾和分析。而在公有云環境,用戶集群或專有網絡內部的數據加工也屬于邊緣計算,這樣可以節省大量的公網傳輸開銷,并分散全局數據計算的壓力。
此外,從數據層面看,邊緣計算一方面可以篩選出更有價值的數據,另一方面可以通過加工提煉數據的深層價值,以最小的成本記錄最有價值的數據。
篩選更有價值的數據
鏈路數據的價值分布是不均勻的。 據不完全統計,調用鏈的實際查詢率小于百萬分之一。全量存儲數據不僅會造成巨大的成本浪費,也會顯著影響整條數據鏈路的性能及穩定性。如下列舉兩種常見的篩選策略。
基于鏈路數據特征進行調用鏈采樣上報(Tag-based Sampling)。 比如錯/慢調用全采,特定服務每秒前N次采樣,特定業務場景自定義采樣等。下圖展示了阿里云 ARMS 自定義采樣配置頁面,用戶可以根據自身需要自由定制存儲策略,實際存儲成本通常小于原始數據的 5%。
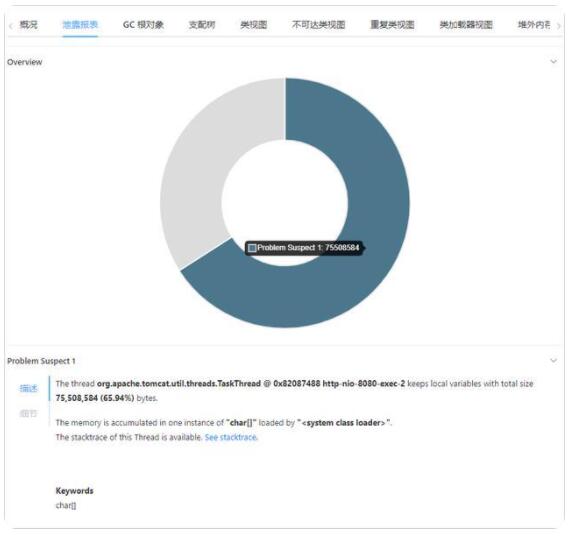
異常場景下自動保留關聯數據現場。 我們在診斷問題根因時,除了調用鏈之外,還需要結合日志、異常堆棧、本地方法耗時、內存快照等關聯信息進行綜合判斷。如果每一次請求的關聯信息全都記錄下來,大概率會造成系統的崩潰。因此, 能否通過邊緣計算自動保留異常場景下的快照現場是衡量 Tracing 產品優劣的重要標準之一。 如下圖所示,阿里云 ARMS 產品提供了慢調用線程剖析,內存異常 HeapDump 等能力。

無論哪種篩選策略,其核心思想都是 通過邊緣節點的數據計算,丟棄無用或低價值數據,保留異常現場或滿足特定條件的高價值數據。 這種基于數據價值的選擇性上報策略性價比遠高于全量數據上報,未來可能會成為 Tracing 的主流趨勢。
提煉數據價值
除了數據篩選,在邊緣節點進行數據加工,比如預聚合和壓縮,同樣可以在滿足用戶需求的前提下,有效節省傳輸和存儲成本。
預聚合統計:在客戶端進行預聚合的最大好處, 就是在不損失數據精度的同時大幅減少數據上報量。 比如,對調用鏈進行 1% 采樣后,仍然可以提供精準的服務概覽/上下游等監控告警能力。
數據壓縮:對重復出現的長文本(如異常堆棧,SQL 語句)進行壓縮編碼,也可以有效降低網絡開銷。結合非關鍵字段模糊化處理效果更佳。
冷熱數據分離,低成本滿足個性化的后聚合分析需求
邊緣計算可以滿足大部分預聚合分析場景,但是無法滿足多樣化的后聚合分析需求,比如某個業務需要統計耗時大于3秒的接口及來源分布,這種個性化的后聚合分析規則是無法窮舉的。而當我們無法預先定義分析規則時,貌似就只能采用成本極高的全量原始數據存儲。難道就沒有優化的空間么?答案是有的,接下來我們就介紹一種低成本解決后聚合分析問題的方案——冷熱數據分離。
冷熱數據分離方案簡述
冷熱數據分離的價值基礎在于用戶的查詢行為滿足時間上的局部性原理。 簡單理解就是,最近的數據最常被查詢,冷數據查詢概率較小。例如,由于問題診斷的時效性,50% 以上的鏈路查詢分析發生在 30分鐘內,7天之后的鏈路查詢通常集中在錯慢調用鏈。理論基礎成立,接下來討論如何實現冷熱數據分離。
首先,熱數據存在時效性,如果只需記錄最近一段時間內的熱數據,對于存儲空間的要求就會下降很多。另外,在公有云環境下,不同用戶的數據天然具備隔離性。因此,在用戶 VPC 內部的熱數據計算和存儲方案就具備更優的性價比。
其次,冷數據的查詢具備指向性,可以通過不同的采樣策略篩選出滿足診斷需求的冷數據進行持久化存儲。例如錯慢采樣,特定業務場景采樣等。由于冷數據存儲周期較長,對穩定性要求較高,可以考慮在 Region 內統一管理。
綜上所述,熱數據存儲周期短,成本低,但可以滿足實時全量后聚合分析需求;而冷數據經過精準采樣后數據總量大幅下降,通常只有原始數據量的 1% ~10%,并可以滿足大多數場景的診斷訴求。兩相結合,實現了成本與體驗的平衡最優解。國內外領先的 APM 產品,如 ARMS、Datadog、Lightstep 均采用了冷熱數據分離的存儲方案。

熱數據實時全量分析
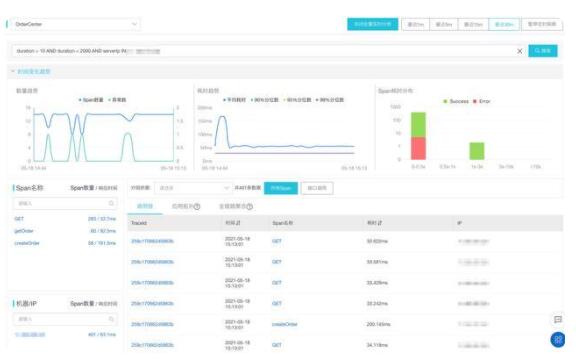
鏈路明細數據包含了最完整最豐富的的調用信息,APM 領域最常用的服務面板、上下游依賴、應用拓撲等視圖均是基于鏈路明細數據統計得出。基于鏈路明細數據的后聚合分析可以根據用戶個性化需求更有效的定位問題。但是,后聚合分析的最大挑戰是要基于全量數據進行統計,否則會出現樣本傾斜導致最終結論離實際相差甚遠。
阿里云 ARMS 作為 2021 年 Gartner APM 魔力象限中國唯一入選云廠商,提供了 30分鐘內熱數據全量分析的能力,可以實現各種條件組合下的過濾與聚合,如下圖所示:
冷數據持久化采樣分析
全量調用鏈的持久化存儲成本非常高,而前文提到 30分鐘后調用鏈的實際查詢率不足百萬分之一,并且大多數的查詢集中在錯慢調用鏈,或滿足特定業務特征的鏈路,相信經常排查鏈路問題的同學會有同感。因此,我們應該只保留少量滿足精準采樣規則的調用鏈,從而極大的節省冷數據持久化存儲成本。
那么精準采樣應該如何實現呢?業界常用的方法主要分為頭部采樣(Head-based Sampling)和尾部采樣(Tail-based Sampling)兩種。頭部采樣一般在客戶端 Agent 等邊緣節點進行,例如根據接口服務進行限流采樣或固定比例采樣;而尾部采樣通常基于全量熱數據進行過濾,如錯慢全采等。
最理想的采樣策略應該只存儲真正需要查詢的數據,APM 產品需要提供靈活的采樣策略配置能力與最佳實踐,用戶結合自身業務場景進行自適應的調整。
結語
當越來越多的企業和應用上云,公有云集群規模爆發式增長,“成本”將是企業用云的關鍵衡量因素。而在云原生時代,充分利用邊緣節點的計算和存儲能力,結合冷熱數據分離實現高性價比的數據價值探索已經逐漸成為 APM 領域的主流。全量數據上報、存儲、再分析這種傳統方案將面臨越來越大的挑戰。未來會如何,讓我們拭目以待。
推薦產品
阿里云 ARMS —— 2021 年 Gartner APM 魔力象限中國唯一入選云廠商
Tracing Analysis —— 兼容 OpenTelemetry 規范,支持 7 種開發語言




















