KDD Cup 2021 | 微軟亞洲研究院Graphormer模型榮登OGB-LSC圖預測賽道榜首
KDD Cup 全稱為國際知識發現和數據挖掘競賽,自1997年開始,由 ACM 協會 SIGKDD 分會每年舉辦一次,目前是全球數據挖掘領域最有影響力的賽事,其所設比賽題目具有相當高的實際意義和商業價值。多年來,該賽事每年都吸引著眾多世界頂級的 AI 研究機構與企業的參與,并且催生了大量的經典比賽和經典算法。
今年,KDD Cup 2021 首次與斯坦福大學圖神經網絡權威 Jure Leskovec 教授領導 Open Graph Benchmark(OGB)團隊合作,聯合舉辦第一屆 OGB Large-Scale Challenge,共有500余個來自全球各地的隊伍參賽。大賽于本周剛剛結束,由微軟亞洲研究院的研究員和大連理工大學等高校的實習生組成的團隊在圖預測賽道摘得桂冠(官方競賽結果網頁鏈接:https://ogb.stanford.edu/kddcup2021/results/)。
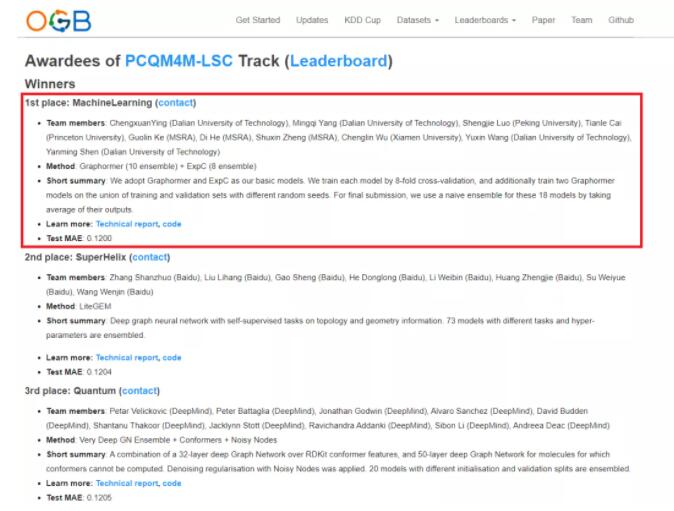
圖1:微軟亞洲研究院的研究員和實習生組成的團隊在 OGB-LSC 圖預測賽道摘得桂冠,團隊成員包括:應承軒(大連理工大學)、楊明奇(大連理工大學)、羅勝杰(北京大學)、蔡天樂(普林斯頓大學)、柯國霖(微軟亞洲研究院)、賀笛(微軟亞洲研究院)、鄭書新(微軟亞洲研究院)、吳承霖(廈門大學)、王宇新(大連理工大學)、申彥明(大連理工大學)
針對圖預測任務,大賽給出的賽題為“根據給定的 2D 分子化學結構圖預測分子性質”。由于近年來人工智能在生物醫學、材料發現等領域的探索持續受到關注,因此該賽道競爭激烈異常,“高手”云集。只有主動求變,才能在眾多高手中脫穎而出。為此,微軟亞洲研究院的研究員們通過借鑒 Transformer 模型的思路,提出了可應用于圖結構數據的 Graphormer 模型,展現了跨領域研究的創新成果,并希望借此為各個領域的技術變革帶來一些啟發。團隊現已將論文和代碼公開發表在 arXiv 和 GitHub 上。
論文鏈接:
https://arxiv.org/abs/2106.05234
代碼鏈接:
https://github.com/microsoft/Graphormer
將Transformer應用于圖數據,核心在于如何正確編碼“圖結構”
為了得到更精確的分子性質,計算化學家們常使用基于量子力學力場的密度泛函理論 DFT (Density Functional Theory)預測,然而該方法非常耗時。若直接使用圖神經網絡 GNN 模型,輸入分子的 2D 結構,則可以快速而準確地預測分子性質,并且在幾秒鐘內就能夠完成。因此,目前圖預測領域的主流算法主要是圖神經網絡(GNN)模型及其變種,比如圖卷積網絡(Graph Convolutional Net)、圖注意力網絡(Graph Attention Net)、圖同構網絡(Graph isomorphic Net)等。
但是,這些圖神經網絡的結構相對簡單,表達能力有限,且經常會出現過度平滑(Over-Smoothing)的問題,即無法通過堆深網絡而增加 GNN 的表達能力。為此,微軟亞洲研究院的研究員們轉變思路,希望可以在圖預測學習任務中從圖表達能力著手,來提升圖預測性能。
研究員們看到,Transformer 模型具有很強的模型表達能力,沒有其他圖神經網絡所存在的上述弱點。微軟亞洲研究院機器學習組對 Transformer 模型結構有著深刻的理解,近幾年在頂級國際學術會議如 ICML、NeurIPS、ICLR 上發表了許多關于如何改進 Transformer 的論文,基于這些對模型本質的認識,研究員們相信 Transformer 的不少優勢在圖數據上也可以發揮巨大的作用。
經典的 Transformer 模型是處理序列類型數據的,如自然語言、語音等等,那么如何讓這個模型處理圖類型數據呢?研究員們認為最重要的是讓 Transformer 學會編碼圖的結構信息。Transformer 的核心在于其自注意力機制,通過在計算中輸入不同位置語義信息的相關性,可以捕捉到信息之間的關系,并且可基于這些關系得到對整個輸入完整的表達(representation)。然而,自注意力機制無法捕捉到結構信息。對于自然語言序列而言,輸入序列的結構信息可以簡單認為是詞與詞的相對順序,以及每個詞在句子中的位置。對于圖數據而言,這種結構信息更加復雜、多元,例如在圖上的每個節點都有不同數量的鄰居節點,兩個節點之間可以有多種路徑,每個邊上都可能包含重要的信息。如何在圖數據中成功應用 Transformer 的核心優勢,最關鍵的難題是要確保模型可以正確利用這些圖結構信息。
圖結構數據上的Transformer變種Graphormer
為了把 Transformer 模型強大的表達能力引入圖結構數據中,研究員們提出了 Graphormer 模型。Graphormer 模型引入了三種結構編碼,以幫助 Transformer 模型捕捉圖的結構信息。這些結構編碼讓 Graphormer 模型的自注意力層可以成功捕捉到更“重要”的節點或節點對,從而令后續的注意力權重分配更準確。
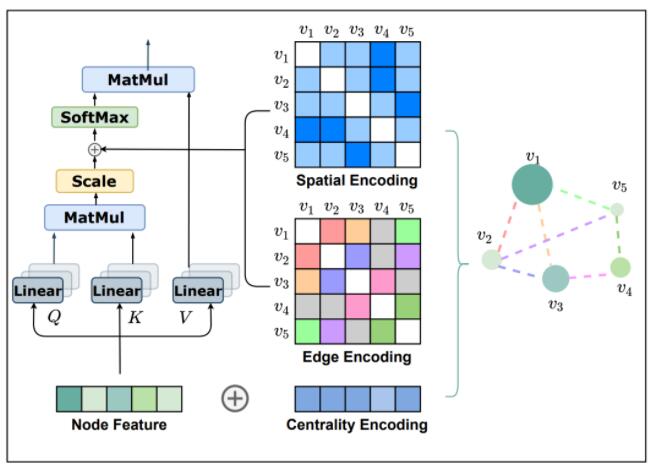
圖2:Graphormer 模型的三種結構編碼
第一種編碼,Centrality Encoding(中心性編碼)。Centrality(中心性)是描述圖中節點重要性的一個關鍵衡量指標。圖的中心性有多種衡量方法,例如一個節點的“度”(degree)越大,代表這個節點與其他節點相連接的邊越多,那么往往這樣的節點就會更重要,如在疾病傳播路線中的超級傳播者,或社交網絡上的大V、明星等。Centrality 還可以使用其他方法進行度量,如 Closeness、Betweenness、Page Rank 等。在 Graphormer 中,研究員們采用了最簡單的度信息作為中心性編碼,為模型引入節點重要性的信息。
第二種編碼,Spatial Encoding(空間編碼)。實際上圖結構信息不僅包含了每個節點上的重要性,也包含了節點之間的重要性。例如:鄰居節點或距離相近的節點之間往往相關性比距離較遠的節點相關性高。因此,研究員們為 Graphormer 設計了空間編碼:給定一個合理的距離度量 ϕ(v_i, v_j), 根據兩個節點(v_i, v_j)之間的距離,為其分配相應的編碼向量。距離度量 ϕ(⋅) 的選擇多種多樣,對于一般性的圖數據可以選擇無權或帶權的最短路徑,而對于特別的圖數據則可以有針對性的選擇距離度量,例如物流節點之間的最大流量,化學分子 3D 結構中原子之間的歐氏距離等等。為了不失一般性,Graphormer 在實驗中采取了無權的最短路徑作為空間編碼的距離度量。
第三種編碼,Edge Encoding(邊信息編碼)。對于很多的圖任務,連邊上的信息有非常重要的作用,例如連邊上的距離、流量等等。然而為處理序列數據而設計的 Transformer 模型并不具備捕捉連邊上的信息的能力,因為序列數據中并不存在“連邊”的概念。因此,研究員們設計了邊信息編碼,將連邊上的信息作為權重偏置(Bias)引入注意力機制中。具體來說,在計算兩個節點之間的相關性時,研究員們對這兩個節點最短路徑上的連邊特征進行加權求和作為注意力偏置,其中權重是可學習的。
與此同時,研究員們還從理論角度證明了當前流行的 GNN 網絡如 GCN、GIN、GraphSage 等,都是 Graphormer 的特例:在為 Graphormer 設定特殊的參數時,這些 GNN 中的操作可以被 Graphormer 所覆蓋。例如,當兩個節點為鄰居節點時,將空間編碼設為0,或將空間編碼設為-∞,并且令 W_Q=W_K=0, W_V=I,則自注意力層即成為 GCN、GraphSage 等網絡中的 MEAN Aggregation 操作。因此,Graphormer 能夠取得比 GNN 模型更好的效果也是理所應當的。
此外,研究員們還在多個主流圖預測任務排行榜上驗證了 Graphormer 的效果。例如,OGB 數據集中的 ogbg-molhiv 任務(預測是否被 HIV 病毒感染),ogbg-molpcba 任務(預測分子的64種性質)以及 Benchmarking-GNN 數據集中的 ZINC 任務(對真實世界中存在的分子的受限溶解度 Constrained Solubility 進行預測)。Graphormer 均取得了優異的成績,具體測試結果如下圖:
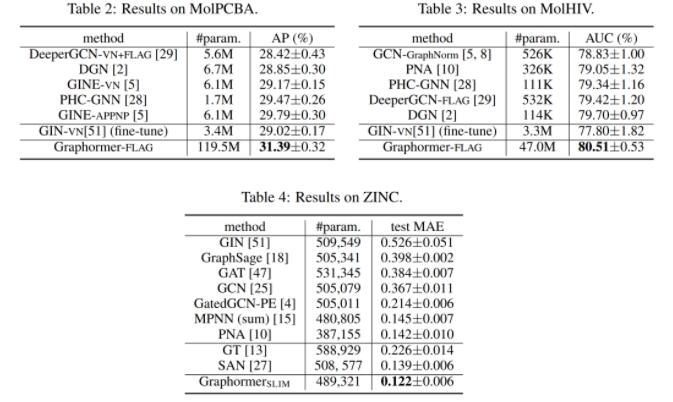
圖3:Graphormer 模型在 ogbg-molhiv、 ogbg-molpcba 和 ZINC 數據集上的測試結果
不止于分子性質預測
近年來,微軟亞洲研究院一直在探索如何利用 AI 的技術手段與不同基礎科學領域進行跨界研究合作,如生物學、環境科學、物理學等等,并產生了大量的創新研究成果。
Graphormer 在設計之初并非只針對分子性質預測場景,其采用的三種編碼具有通用性,可以應用于更廣泛的圖數據場景中,例如,社交網絡的推薦和廣告、知識圖譜、自動駕駛的雷達點云數據、對交通物流運輸等的時空預測和優化、程序理解和生成等等,還包括分子性質預測所涉及的行業,比如藥物發掘、材料發現、分子動力學模擬、蛋白質結構預測等等。研究員們表示,下一步將在更多的任務中探索 Graphormer 模型的潛能。相信未來,各個科學領域與 AI 的密切結合將為領域的發展帶來更為非常廣闊的空間。
歡迎大家使用 Graphormer 模型,為模型的提升提出寶貴建議,與我們共同推進相關領域的技術進展。
論文鏈接:
https://arxiv.org/abs/2106.05234
代碼鏈接:
https://github.com/microsoft/Graphormer