Acme框架真香!用過一次后 倫敦博士撰文大贊DeepMind強(qiáng)化學(xué)習(xí)框架
研究強(qiáng)化學(xué)習(xí)的你還在苦于重復(fù)造輪子嗎?苦于尋找運(yùn)行環(huán)境嗎?
DeepMind給你帶來了Acme框架!
Acme是一個(gè)基于 python 的強(qiáng)化學(xué)習(xí)研究框架,2020年由 Google 的 DeepMind 開源。這個(gè)框架簡化了新型 RL 智能體(agent)的開發(fā),加快了 RL 研究的步伐。
DeepMind 是強(qiáng)化學(xué)習(xí)和人工智能研究的先行者,根據(jù)他們自己的研究人員所說,Acme 已經(jīng)成為 DeepMind 的日常使用的框架了。
目前Acme在Git已經(jīng)獲得了超過2.1k個(gè)星星。

Acme的學(xué)習(xí)曲線也是相當(dāng)平緩的。但由于Acme有多個(gè)不同復(fù)雜程度的接口作為切入點(diǎn),也就是說,這個(gè)框架不僅適用于高級研究人員,而且允許初學(xué)者實(shí)現(xiàn)甚至是簡單的算法,類似于 TensorFlow 和 PyTorch 能夠同時(shí)被初學(xué)者和專家所使用。
但這個(gè)框架唯一的缺點(diǎn)就是,由于框架仍然是相當(dāng)新的,沒有真正完整的文檔可用,也沒有任何優(yōu)秀的教程。
針對這個(gè)問題,倫敦政治經(jīng)濟(jì)學(xué)院一個(gè)博士生寫了一篇教學(xué)博客,幫助了解Acme框架,據(jù)作者所說,這篇教程文章并不打算成為或取代一個(gè)完整的文檔,而是對 Acme 的一個(gè)簡潔、實(shí)用的介紹。最重要的是,它應(yīng)該讓讀者了解框架底層的設(shè)計(jì)選擇,以及這對 RL 算法的實(shí)現(xiàn)意味著什么。
Acme的基本架構(gòu)
以21點(diǎn)游戲(BlackJack)作為例子來介紹框架。
Acme 的智能體的運(yùn)行環(huán)境沒有設(shè)計(jì)與Gym運(yùn)行環(huán)境交互,而是采用DeepMind 自己創(chuàng)建的 RL 環(huán)境 API。它們的區(qū)別主要在于時(shí)間步是如何表示的。
幸運(yùn)的是, Acme 的開發(fā)人員已經(jīng)為Gym環(huán)境提供了包裝器函數(shù)。

21點(diǎn)有32 x 11 x 2個(gè)狀態(tài),盡管并不是所有這些狀態(tài)都能在一場比賽中實(shí)際發(fā)生,并且有兩個(gè)action可選,hit或是stick。
三個(gè)重要的角色分別是actor, learner, 智能體agent。
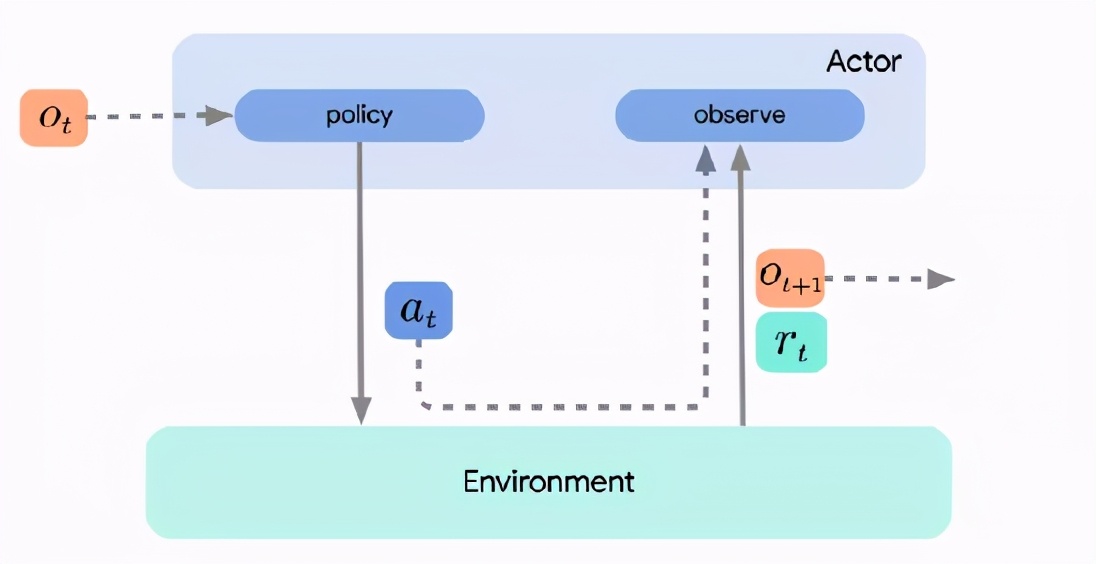
learner使用actor收集的數(shù)據(jù)來學(xué)習(xí)或改進(jìn)策略,通常采用迭代的在線方式。例如,學(xué)習(xí)可能包括更新神經(jīng)網(wǎng)絡(luò)的參數(shù)。新的參數(shù)被傳遞給actor,然后actor根據(jù)更新的策略進(jìn)行操作。
智能體只是簡單地將行為和學(xué)習(xí)組件結(jié)合起來,但是通常不需要實(shí)現(xiàn)額外的強(qiáng)化學(xué)習(xí)邏輯。下面的圖片包含了所有三個(gè)組件。
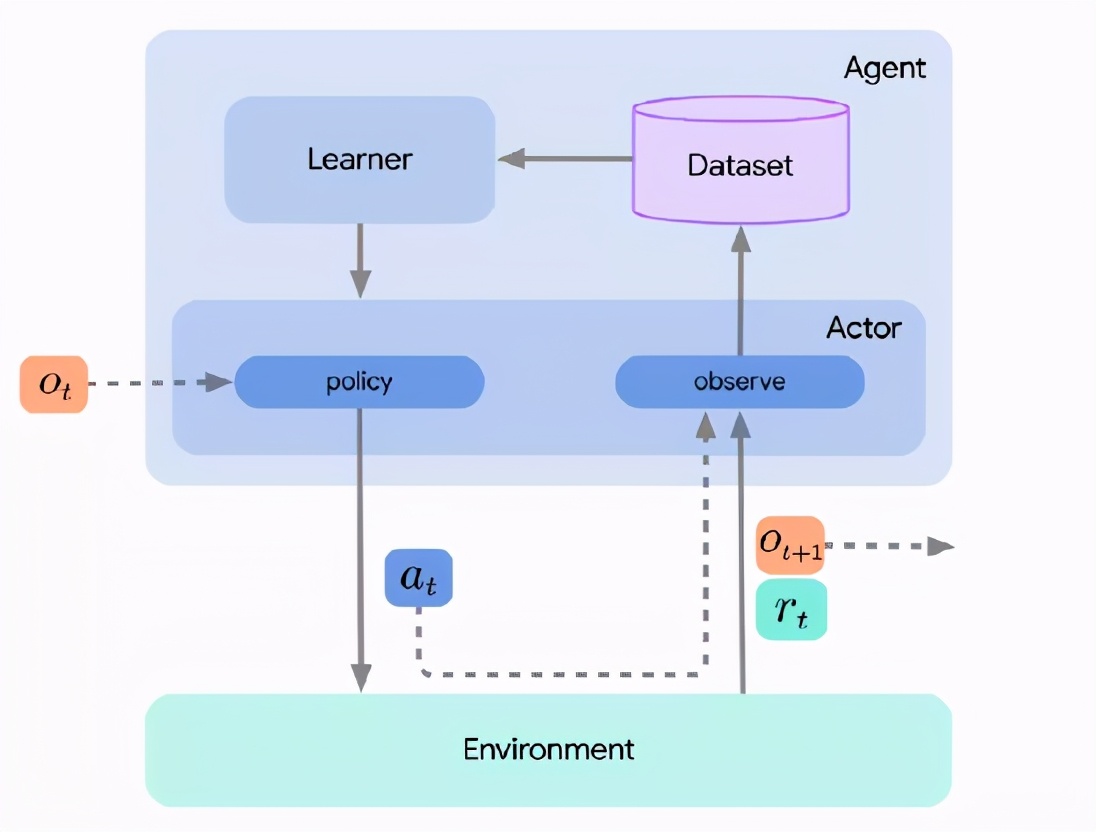
這種將actor、learner和agent分解的主要原因之一是為了促進(jìn)分布式強(qiáng)化學(xué)習(xí)。如果我們不關(guān)心這些,或者算法足夠簡單,那么也可以只實(shí)現(xiàn)actor,并簡單地將學(xué)習(xí)步驟集成到actor的更新方法中。
例如,下面的隨機(jī)智能體繼承自 acme的Actor類。開發(fā)人員必須實(shí)現(xiàn)的方法是 select_action、 observe_first、observe 和 update。正如剛才提到的,后者是沒有額外的learner組成部分的學(xué)習(xí)。
注意,這個(gè)agent將以同樣的方式工作,而不會(huì)子類化 acme.Actor。基類僅確定必須覆蓋的方法。這還確保agent按照預(yù)期的方式與其他 Acme 組件集成,例如環(huán)境循環(huán)(environment loop)。

這個(gè)agent使用一個(gè)隨機(jī)選擇hit或stick的策略,但是通常框架允許您在如何實(shí)現(xiàn)策略方面有很大的靈活性。后面還會(huì)實(shí)現(xiàn)一個(gè)貪婪的政策。
在其他情況下,策略可能包含一個(gè)神經(jīng)網(wǎng)絡(luò),可以使用 TensorFlow、 PyTorch 或 JAX 來實(shí)現(xiàn)它。在這個(gè)意義上,Acme 是框架是不可知的,可以將它與任何機(jī)器學(xué)習(xí)庫結(jié)合起來。
在更新方法中,actor通常只從learner中提取最新的參數(shù)。
但是,如果不使用單獨(dú)的學(xué)習(xí)者,那么 RL 邏輯將進(jìn)入update方法。
一個(gè) 強(qiáng)化學(xué)習(xí)算法通常由一個(gè)循環(huán)組成,每個(gè)循環(huán)由四個(gè)步驟組成,重復(fù)這四個(gè)步驟,直到達(dá)到一個(gè)終止?fàn)顟B(tài)。
1、觀察狀態(tài)
2、根據(jù)行為策略選擇下一步行動(dòng)
3、觀察獎(jiǎng)勵(lì)
4、更新策略

在大多數(shù)情況下,這個(gè)循環(huán)總是完全相同的。
方便的是,在 Acme 中有一個(gè)快捷方式: EnvironmentLoop,它執(zhí)行的步驟幾乎與上面看到的步驟一模一樣。只需傳遞環(huán)境和代理實(shí)例,然后可以使用單行代碼運(yùn)行單個(gè)事件或任意多個(gè)事件。還有一些記錄器可以跟蹤重要的指標(biāo),比如每一個(gè)迭代采取的步驟數(shù)和收集到的獎(jiǎng)勵(lì)。

SARSA 智能體
SARSA 是一個(gè)基于策略的算法,其更新依賴于狀態(tài)(state)、行動(dòng)(action)、獎(jiǎng)勵(lì)(reward)、下一個(gè)狀態(tài)(next state)和下一個(gè)行動(dòng)(next action)而得名。
首先,在智能體的 __init__ 方法中,我們初始化 Q、狀態(tài)動(dòng)作值矩陣和行為策略,這是一個(gè) epsilon 貪婪策略。還要注意,這個(gè)代理必須始終存儲它的上一個(gè) timestep、 action 和下一個(gè) timestep,因?yàn)樗鼈冊诟虏襟E中是必需的。


在observe函數(shù)中,通常沒有什么必須做的事。
在這種情況下,我們只是存儲觀察到的時(shí)間步和所采取的操作,然而,這并不總是必要的。例如,有時(shí)可能希望將時(shí)間步驟(和整個(gè)軌跡)存儲在數(shù)據(jù)集或重播緩沖區(qū)中。
Acme 還為此提供了數(shù)據(jù)集和額外的組件。事實(shí)上,還有一個(gè)由 DeepMind 開發(fā)的Reverb庫用來做這件事。
上面的 transform_state 方法只是一個(gè)輔助函數(shù),用于將狀態(tài)轉(zhuǎn)換為正確的格式,以便正確地對 Q 矩陣進(jìn)行索引。
最后,訓(xùn)練 SARSA 的環(huán)境為500,000步。

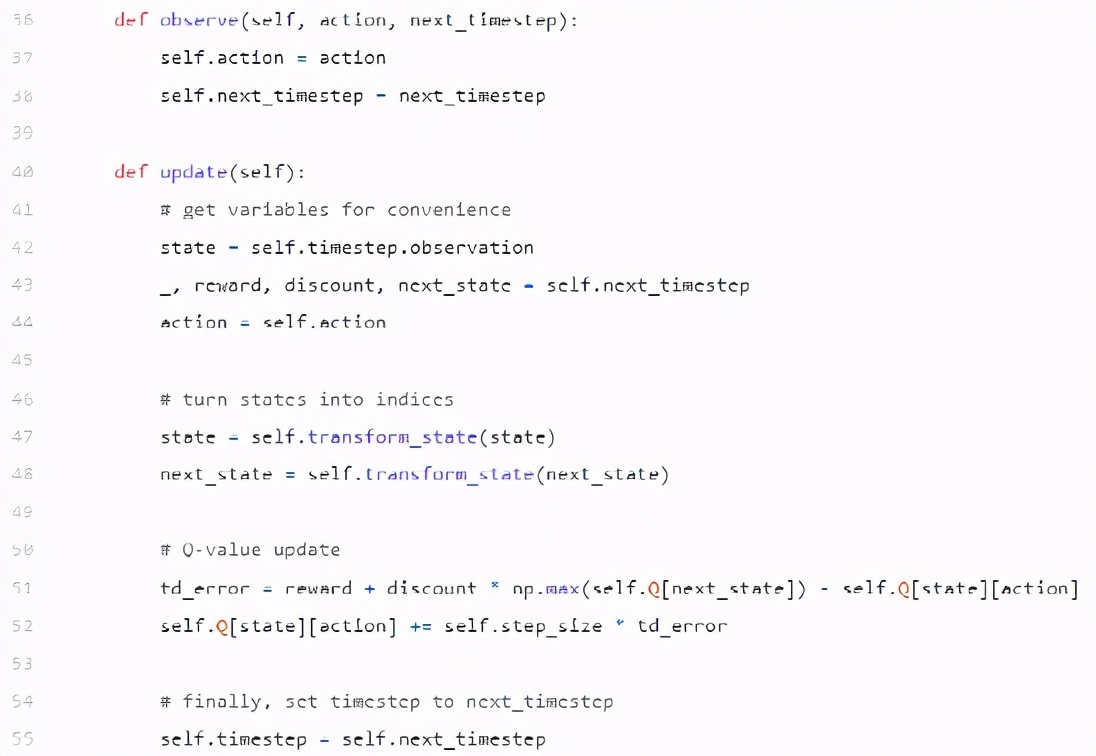
Q learning 智能體
下面的 Q learning 智能體與 SARSA 智能體非常相似。它們的不同之處僅在于如何更新 Q 矩陣。這是因?yàn)?Q 學(xué)習(xí)是一種非策略算法。

博客作者認(rèn)為, Acme 是一個(gè)非常好的強(qiáng)化學(xué)習(xí)框架,因?yàn)槟悴恍枰獜念^開發(fā)你的算法。所以,與其自己琢磨如何編寫可讀和可重復(fù)的 RL 代碼,你可以依靠 DeepMind 的聰明的研究人員和開發(fā)人員,他們已經(jīng)為你做到了。
在他們的倉庫中,Deep Q-Networks (DQN)、Deep Deterministic Policy Gradient(DDPG)、Monte Carlo Tree Search (MCTS)、Behavior Cloning(BC)、 IMPALA 等常用算法的實(shí)現(xiàn)。