Google開源了其大規模強化學習的框架
深度強化學習(DRL)是深度學習領域研究最快的領域之一。DRL負責AI近年來的一些頂級里程碑,例如AlphaGo,Dota2 Five或Alpha Star,DRL似乎是最接近人類智能的學科。但是,盡管取得了所有進展,但DRL方法在現實世界中的實現仍然受限于大型人工智能(AI)實驗室。部分原因是DRL體系結構依賴不成比例的大量培訓,這使得它們對大多數組織而言在計算上昂貴且不切實際。最近,Google Research發表了一篇論文,提出了SEED RL,這是一種可大規模擴展的DRL模型的新架構。
在現實世界中實現DRL模型的挑戰與它們的體系結構直接相關。 本質上,DRL包含各種任務,例如運行環境,模型推斷,模型訓練或重放緩沖區。 大多數現代DRL體系結構無法有效地分配用于此任務的計算資源,從而使其實施成本不合理。 諸如AI硬件加速器之類的組件已幫助解決了其中一些限制,但它們只能走得那么遠。 近年來,出現了新架構,這些新架構已被市場上許多最成功的DRL實現所采用。
從IMPALA汲取靈感
在當前的DRL體系結構中,IMPALA為該領域樹立了新的標準。IMPALA最初是由DeepMind在2018年的研究論文中提出的,它引入了一種模型,該模型利用專門用于數值計算的加速器,充分利用了監督學習多年來受益的速度和效率。IMPALA的中心是一個基于參與者的模型,該模型通常用于最大化并發和并行化。
基于IMPALA的DRL代理的體系結構分為兩個主要組件:參與者和學習者。在此模型中,參與者通常在CPU上運行,并在環境中采取的步驟與對該模型進行推斷之間進行迭代,以預測下一個動作。參與者經常會更新推理模型的參數,并且在收集到足夠數量的觀察結果之后,會將觀察結果和動作的軌跡發送給學習者,從而對學習者進行優化。在這種體系結構中,學習者使用來自數百臺機器上的分布式推理的輸入在GPU上訓練模型。從計算的角度來看,IMPALA體系結構可以使用GPU加速學習者的學習,而參與者可以在許多機器上進行擴展。
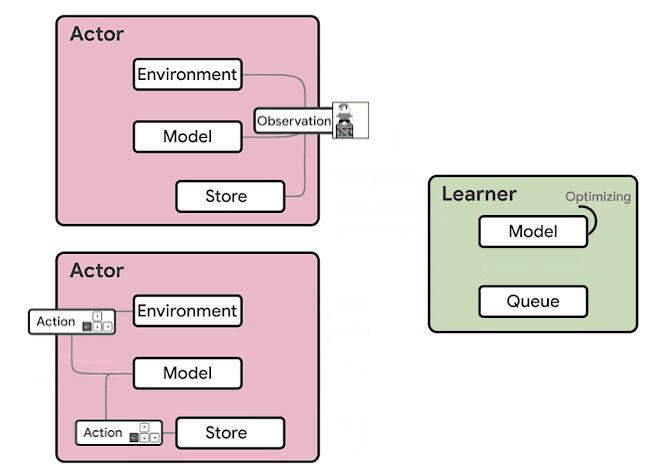
> Source: https://ai.googleblog.com/2020/03/massively-scaling-reinforcement.html
IMPALA在DRL體系結構中建立了新標準。 但是,該模型具有一些固有的局限性。
·使用CPU進行神經網絡推斷:參與者機器通常基于CPU。 當模型的計算需求增加時,推理所花費的時間開始超過環境步長的計算。 解決方案是增加參與者的數量,這會增加成本并影響融合。
·資源利用效率低下:參與者在兩個任務之間交替進行:環境步驟和推斷步驟。這兩個任務的計算要求通常不相似,從而導致利用率低下或參與者行動緩慢。
·帶寬要求:模型參數,循環狀態和觀察值在參與者和學習者之間傳遞。此外,基于內存的模型會發送大狀態,從而增加了帶寬需求。
Google以IMPALA actor模型為靈感,開發了一種新架構,該架構解決了其前身在DRL模型縮放方面的一些局限性。
種子RL
總體而言,Google的SEED RL體系結構與IMPALA極為相似,但它引入了一些變體,解決了DeepMind模型的一些主要限制。 在SEED RL中,神經網絡推理由學習者在專用硬件(GPU或TPU)上集中完成,從而通過確保模型參數和狀態保持局部狀態來加快推理速度并避免數據傳輸瓶頸。 對于每個環境步驟,都會發送觀測值
給學習者,學習者進行推理并將動作發送回參與者。這個聰明的解決方案解決了IMPALA等模型的推理限制,但可能會帶來延遲挑戰。
為了最大程度地減少延遲影響,SEED RL依靠gPRC進行消息傳遞和流傳輸。 具體來說,SEED RL利用流式RPC,從參與者到學習者的連接保持打開狀態,元數據僅發送一次。 此外,該框架包括一個批處理模塊,該模塊可有效地將多個參與者推理調用一起批處理。
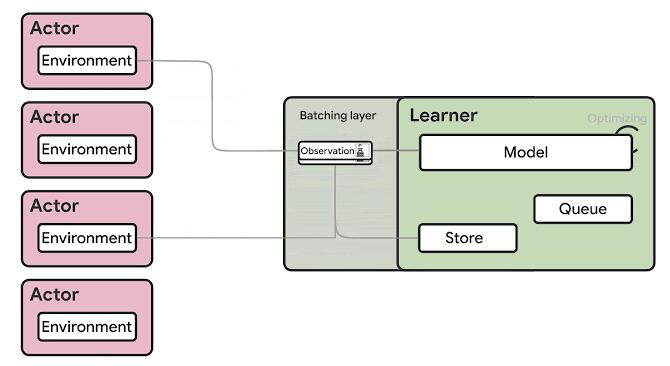
> Source: https://ai.googleblog.com/2020/03/massively-scaling-reinforcement.html
深入研究IMPALA架構,將運行三種基本類型的線程:
1.推論
2.數據預取
3.訓練
推理線程會收到一批觀察,獎勵和情節終止標志。它們加載循環狀態并將數據發送到推理TPU內核。接收采樣的動作和新的重復狀態,并且在存儲最新的重復狀態的同時,將動作發送回參與者。軌跡完全展開后,它將添加到FIFO隊列或重播緩沖區中,然后由數據預取線程進行采樣。最后,將軌跡推入設備緩沖區,以供每個參加訓練的TPU內核使用。訓練線程(Python主線程)采用預取的軌跡,使用訓練的TPU內核計算梯度,并將梯度同步應用于所有TPU內核的模型(推理和訓練)。可以調整推理和訓練核心的比率,以實現最大的吞吐量和利用率。
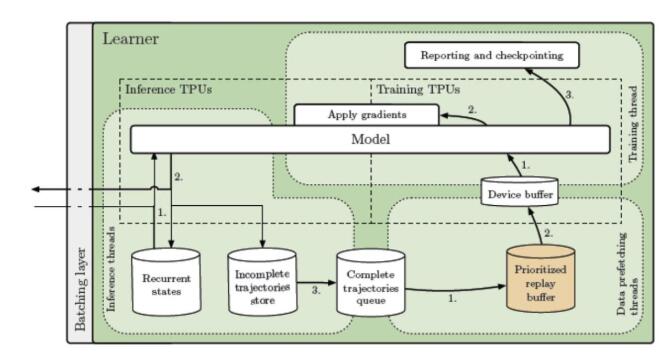
> Source: https://arxiv.org/abs/1910.06591
SEED RL體系結構允許將學習者擴展到成千上萬個內核,而參與者的數量也可以擴展到成千上萬臺機器,以充分利用學習者,從而可以以每秒數百萬幀的速度進行訓練。鑒于SEED RL基于TensorFlow 2 API,并且TPU加速了其性能。
為了評估SEED RL,Google使用了常見的DRL基準測試環境,例如cade學習環境,DeepMind Lab環境以及最近發布的Google Research Football環境。 在所有環境下的結果都是驚人的。 例如,在DeepMind實驗室環境中,SEED RL使用64個Cloud TPU內核達到了每秒240萬幀,這比以前的最新分布式代理IMPALA提高了80倍。 還看到了速度和CPU利用率的提高。
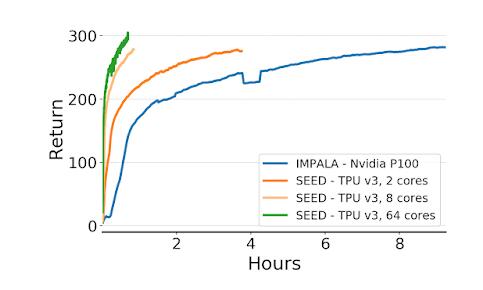
> Source: https://ai.googleblog.com/2020/03/massively-scaling-reinforcement.html
SEED RL代表了可大規模擴展的DRL模型的改進。 Google Research在GitHub上開源了最初的SEED RL體系結構。 我可以想象,在可預見的將來,這將成為許多實際DRL實現的基礎模型。