













華人博士用強化學習回收了SpaceX火箭
本文經AI新媒體量子位(公眾號ID:QbitAI)授權轉載,轉載請聯系出處。
馬斯克旗下的SpaceX可以說帶火了“火箭回收”這一話題。
這不,連粉絲們都已經開始摩拳擦掌,用自己的方式挑戰起了這個技術難題。
例如一位來自密歇根大學的華人博士,就用強化學習試了一把回收火箭!
他根據現實中的星艦10號一通進行模擬,還真在虛擬環境中穩穩地完成了懸停和著陸!

這個項目迅速在Reddit上引發了大批網友們的關注:

那么,他是如何實現的呢?
給火箭回收設立“獎勵機制”
要在模擬環境中回收火箭,那么大一只構造復雜的火箭肯定是不能直接抱來用的。
于是,這位SpaceX的鐵桿粉絲首先基于氣缸動力學,將火箭簡化為一個二維平面上的剛體:
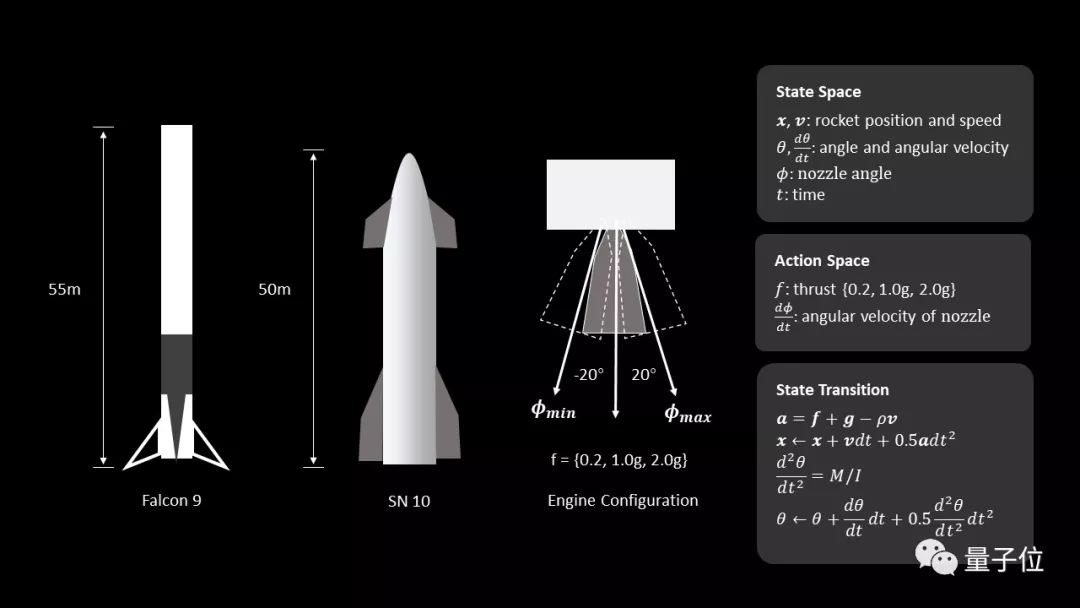
這個火箭的底部安裝有推力矢量發動機,能夠提供不同方向的可調的推力值(0.2g,1.0g和2.0g);同時,火箭噴嘴上還增加了一個角速度約束,最大轉速為30°/秒。
火箭模型所受到的空氣阻力則設定為與速度成正比。
現在,這個模型的一些基本屬性就能夠以下面兩個集合來表示:
- 動作空間:發動機離散控制信號的集合,包括推力加速度和噴嘴角速度
- 狀態空間:由火箭位置、速度、角度、角速度、噴管角度和仿真時間組成的集合
而“火箭回收”這一流程,則被分為了懸停和著陸兩個任務。
在懸停任務中,火箭模型需要遵循這樣一種獎勵機制:
- 火箭與預定目標點的距離:距離越近,獎勵越大;
- 火箭體的角度:火箭應該盡可能保持豎直
著陸任務則基于星艦10號的基本參數,將火箭模型的初始速度設置為-50米/秒,方向設置為90°(水平方向),著陸燃燒高度設置為離地面500米。

△星艦10號發射和著陸的合成圖像
火箭模型在著陸時同樣需要遵循這樣一種“獎勵機制”:
當著陸速度小于安全閾值,并且角度接近豎直0°時,就會受到最大的“獎勵”,也會被認為是一次成功的著陸。
總體而言,這是一個基于策略的參與者-評判者的模型。
接下來就是進行訓練:
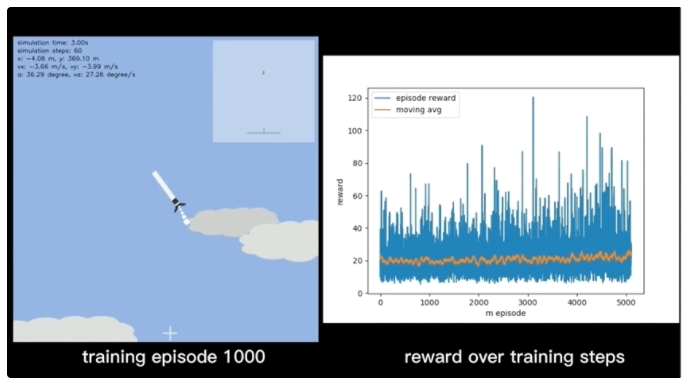
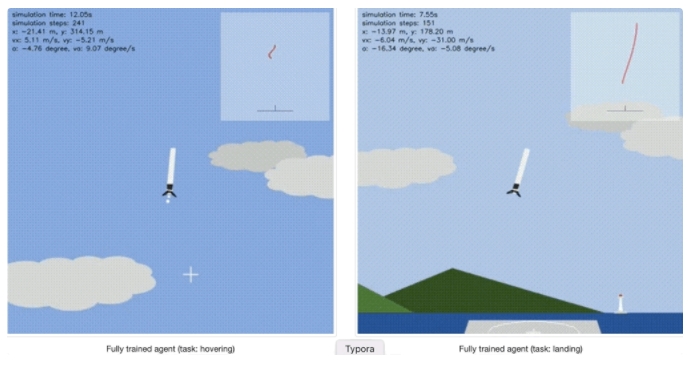
最終,在經歷了20000次的訓練后,火箭模型在懸停和著陸兩個任務上都實現了較好的效果:
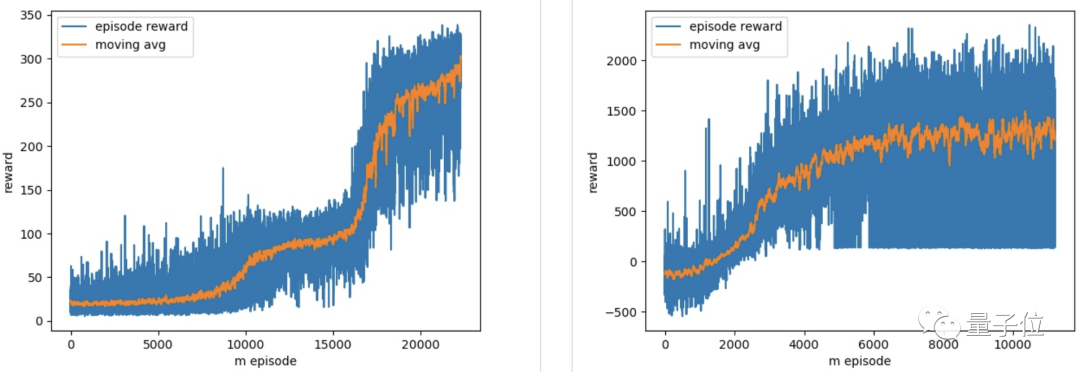
最終,模型得到了很好的收斂效果:
而這枚模擬環境中的偽·星艦10號,也就像開頭展示的那張動圖一樣,學會了腹部著陸,穩穩地落地了。
下一步:增加燃料變量
這一項目一經發出,就引來了紅迪眾多網友的圍觀和稱贊。
有人覺得用強化學習來解決傳統任務非常有趣,因為它具有更好的魯棒性。
作者也在下方回復表示:現實中惡劣的環境條件可以成為環境制約因素,而強化學習則能在一個統一的框架內解決這些問題。
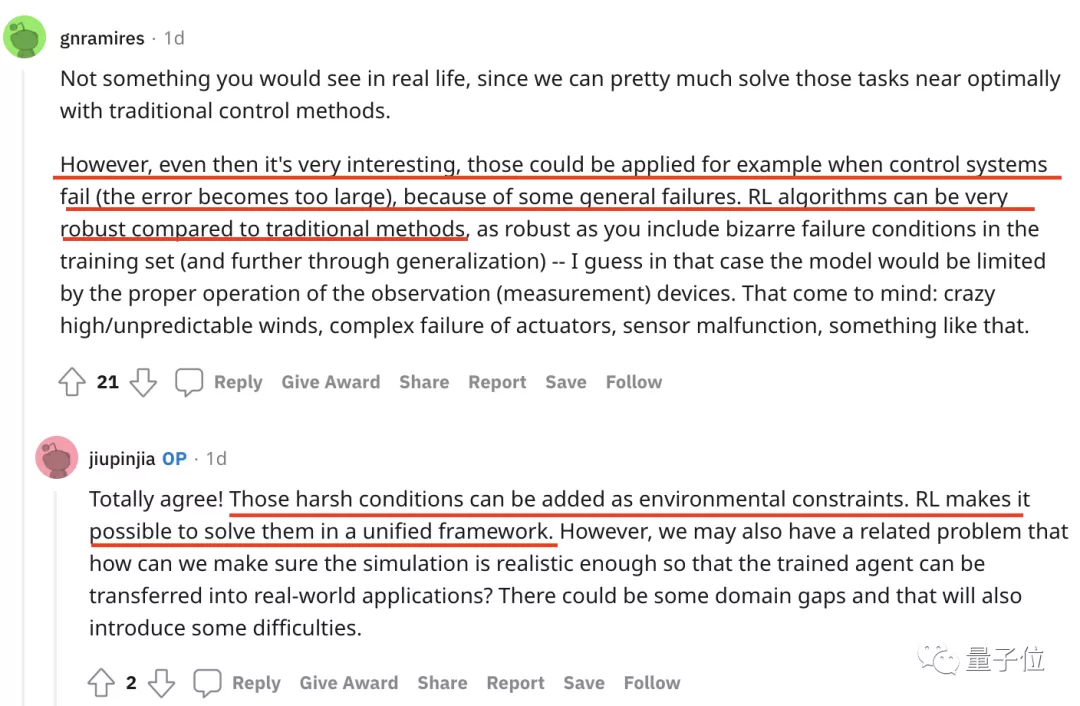
不過在稱贊之余,也有網友提出了最直接的這樣一個問題:
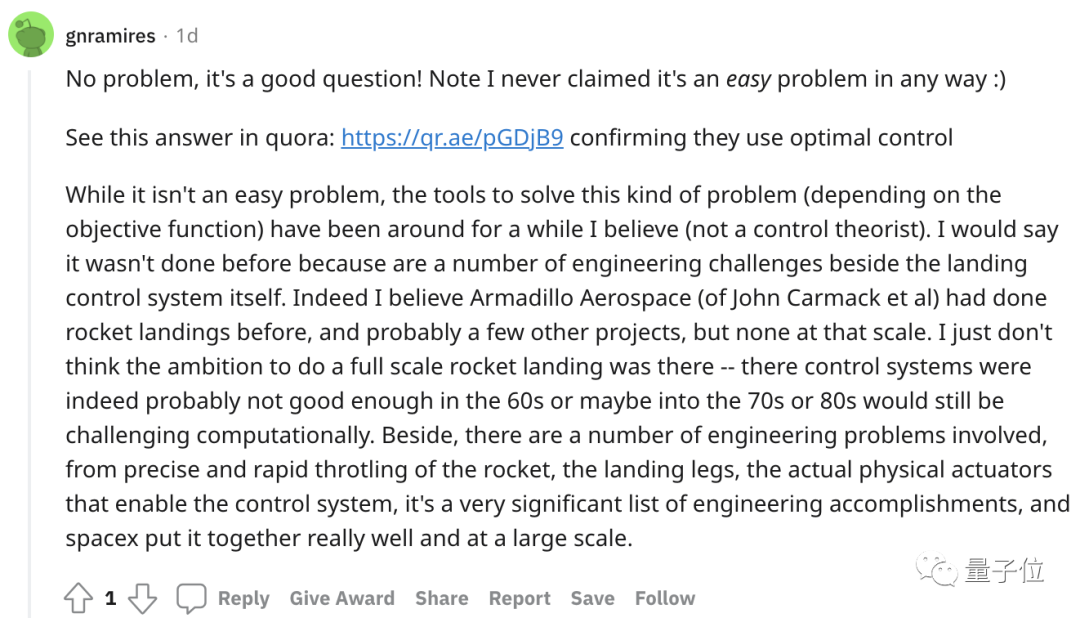
既然我們已經可以使用經典控制方法找到這些任務的最優解,那為啥SpaceX之前沒人做?

下方有人解答到:這或許是因為之前的數字控制系統、傳感器等技術并不成熟,采用新方法就意味著要重新設計火箭的關鍵部分。
這也就是控制系統層面之外的“工程類的問題”,而SpaceX正是在這些相關領域中做了改進。
而那些較為傳統保守的航天航空工業則會使用使用凸優化(Convexification)來解決火箭著陸問題。
也就是評論區有人貼出的這篇論文中提到的方法:

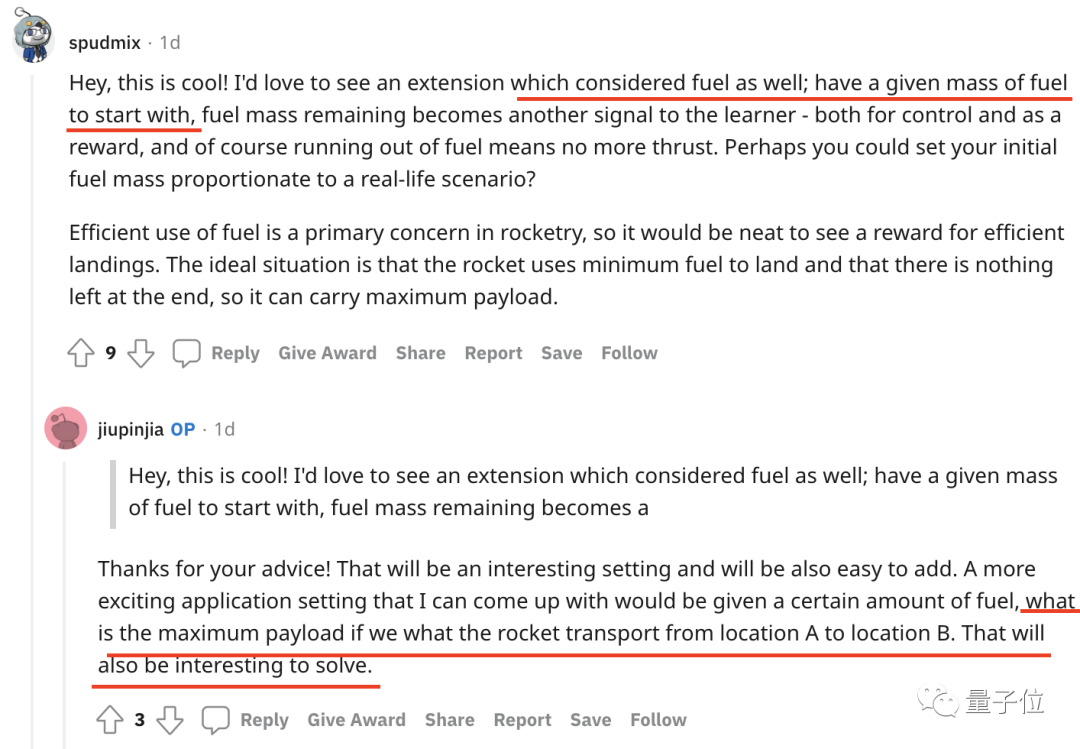
不少評論也為開發者提供了下一步開發的新思路,比如這條評論建議將“剩余燃料”也作為一個變量,模型燃料的減少或耗盡也是現實中的一個重要影響因素。
作者欣然接受了這一建議:是很容易添加的有趣設置,安排!
密歇根大學華人博士
開發者已經為這一項目建立了一個網站,在主頁他這樣介紹到:
這是我的第一個強化學習項目,所以,我希望通過這些“低水平代碼”盡可能地從頭實現包括環境、火箭動力學和強化學習agent在內的所有內容。

作者叫Zhengxia Zou,是一位來自密歇根大學博士,主要研究計算機視覺、遙感、自動駕駛等領域。
他的論文曾被 ICCV 2021、CVPR 2021等多個頂會收錄:

下載鏈接:
https://github.com/jiupinjia/rocket-recycling
項目主頁:
https://jiupinjia.github.io/rocket-recycling/

























