













同事問我,SQL 語句明明命中了索引,為什么執行很慢?
本文轉載自微信公眾號「微觀技術」,作者Tom哥 。轉載本文請聯系微觀技術公眾號。
大家好,我是Tom哥~
我們都知道,業務開發涉及到數據庫的SQL操作時,一定要 review 是否命中索引。否則,會走 全表掃描,如果表數據量很大時,會慢的要死。
假如命中了索引呢?是不是就不會有慢查詢?
殊不知,我們習以為常的常識有時也會誤導我們!
人生好難!
聊這個話題,要有一定技術基礎,需了解 B+ 樹的存儲結構
如果不是很清楚的話,先看下之前一篇文章,有詳細介紹
面試題:mysql 一棵 B+ 樹可以存多少條數據?
1、工作準備:建表,造數據
首先創建一張 user 表,并創建一個 id的主鍵索引,和一個 user_name 的普通索引。
- CREATE TABLE `user` (
- `id` bigint(20) NOT NULL AUTO_INCREMENT,
- `user_name` varchar(128) NOT NULL DEFAULT '' COMMENT '用戶名',
- `age` int(11) NOT NULL COMMENT '年齡',
- `address` varchar(128) COMMENT '地址',
- PRIMARY KEY (`id`),
- key `idx_user_name` (user_name),
- ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='用戶表';
啟動程序,往 user 表中插入 10000 條數據。
- @GetMapping("/insert_batch")
- public Object insertBatch(@RequestParam("batch") int batch) {
- for (int j = 1; j <= batch; j++) {
- List<User> userList = new ArrayList<>();
- for (int i = 1; i <= 100; i++) {
- User user = User.builder().userName("Tom哥-" + ((j - 1) * 100 + i)).age(29).address("上海").build();
- userList.add(user);
- }
- userMapper.insertBatch(userList);
- }
- return "success";
- }
2、慢查詢
在分析原因前,我們先來了解 mysql 慢查詢是什么?如何定義的?
慢查詢定義:
MySQL的慢查詢日志是MySQL提供的一種日志記錄,用來記錄在MySQL中響應時間超過閥值的語句,具體指運行時間超過long_query_time值的SQL,則會被記錄到慢查詢日志中。
慢查詢相關參數:
- slow_query_log:是否開啟慢查詢日志,1表示開啟,0表示關閉。
- log-slow-queries:舊版(5.6以下版本)MySQL數據庫慢查詢日志存儲路徑。可以不設置該參數,系統則會默認給一個缺省的文件host_name-slow.log
- slow-query-log-file:新版(5.6及以上版本)MySQL數據庫慢查詢日志存儲路徑。可以不設置該參數,系統則會默認給一個缺省的文件host_name-slow.log
- long_query_time:慢查詢閾值,當查詢時間高于設定的閾值時,記錄到日志
- log_queries_not_using_indexes:未使用索引的查詢也被記錄到慢查詢日志中(可選項)
默認情況下slow_query_log的值為OFF,表示慢查詢日志是禁用的,可以通過設置slow_query_log的值來開啟,如下所示:
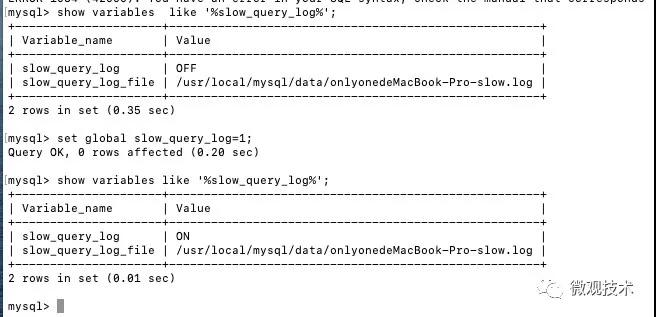
使用set global slow_query_log=1 開啟了慢查詢日志只對當前數據庫生效,如果MySQL重啟后則會失效。如果要永久生效,必須修改配置文件 my.cnf
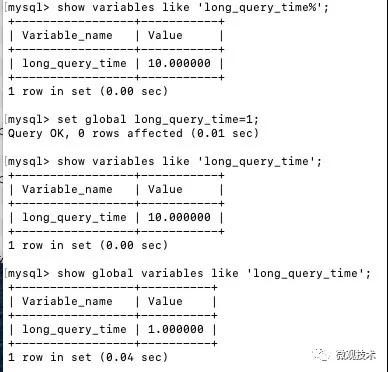
long_query_time的默認值為10 秒,支持二次修改。線上我們一般會設置成1秒,如果業務對延遲敏感的話,我們根據需要設置一個更低的值。
3、開始實驗
首先看下以下幾種場景的SQL語句執行時,索引的命中情況。
1、執行explain select * from user;,發現 key 這列為NULL,說明了沒有命中索引,走了全表掃描。

2、執行 explain select * from user where id=10;,發現 key 這列為 PRIMARY,說明使用了主鍵索引。

3、執行 explain select user_name from user;,發現 key 這列為 idx_user_name,說明使用了二級普通索引。

但是,實驗發現,雖然走了二級索引,但是 rows 掃描行為 9968,說明走了全表掃描。性能很差。
本文測試只造了 1W 條數據,如果線上環境有個千萬級數據量,那估計要好幾秒才能響應結果。
如果請求并發量很高,很容易引發數據庫連接無法及時釋放,導致客戶端無法獲取數據庫連接而報錯。
4、命中索引,依然很慢
我們知道所有的數據都是存儲在 B+ 索引樹上,當執行 explain select * from user where id>0; 時,發現使用了主鍵索引。

mysql 優化器根據主鍵索引找到第一個 id>0 的值,雖然走了索引但其實還是全表掃描。
沒命中索引會走全表掃描,命中了索引也可能走全表掃描。
看來是否命中索引,并不是評判 SQL 性能好壞的唯一標準。
其實,還有一個重要指標,那就是 掃描行數。
當一個表很大時,不僅要關注是否有索引,還要關注索引的過濾性是否足夠好。
5、回表優化
首先為user表 增加一個 user_name 和 age 的聯合索引。
- ALTER TABLE `user` ADD INDEX idx_user_name_age ( `user_name`,`age` );
執行 explain select * from user where user_name like 'Tom哥-1%' and age =29;

執行流程:
- ① 首先在 idx_user_name_age 索引樹,查找第一個以 Tom哥-1 開頭的記錄對應的主鍵id
- ② 根據主鍵id從主鍵索引樹找到整行記錄,并根據age做判斷過濾,等于29則留下,否則丟棄。這個過程也稱為回表
- ③ 然后,在 idx_user_name_age 聯合索引樹上向右遍歷,找到下一個主鍵id
- ④ 再執行第二步
- ⑤ 后面重復執行第三步、第四步,直到user_name不是以 Tom哥-1 開頭,則結束
- ⑥ 返回所有查詢結果
分析:
由于按user_name 的前綴匹配,idx_user_name_age二級索引中的 age 部分并沒有發揮作用。導致了大量回表查詢,性能較差。
有什么優化策略:
MySQL 5.6 版本引入一個 Index Condition Pushdown Optimization

https://dev.mysql.com/doc/refman/5.6/en/index-condition-pushdown-optimization.html
優化后,執行流程:
- ① 首先在 idx_user_name_age 索引樹,查找第一個以 Tom哥-1 開頭的索引記錄
- ② 然后,判斷這個索引記錄中的 age 是否等于 29。如果是,回表 取出整行數據,作為后面的結果返回;如果不是,則丟棄
- ③ 在 idx_user_name_age 聯合索引樹上向右遍歷,重復第二步,直到user_name不是以 Tom哥-1 開頭,則結束
- ④ 返回所有查詢結果
跟上面的過程差別,在于判斷 age 是否等于 29 放在了遍歷聯合索引過程中進行,不需要回表判斷,大大降低了回表的次數,提升性能。
當然這個優化依然沒有繞開最左前綴原則,索引的過濾性仍然有提升空間。
這時,我們需要引入一個叫 虛擬列 的概念。
修改表結構:
- ALTER TABLE `user` add user_name_first varchar(12) generated always as
- (left(user_name,6)) , add index(user_name_first,age);

執行 explain select * from user where user_name_first like 'Tom哥-1%' and age =29;

比較發現,掃描行數 row 變小了,證明優化有效果。
6、寫在最后
slow_query_log 收集到的慢 SQL ,結合 explain 分析是否命中索引,結合掃描行數,有針對性的優化慢 SQL。
但是要注意一點,慢 SQL 日志中也可能有正常的 SQL,可能只是當時CPU等系統資源過載,影響到正常 SQL 的執行速度。
簡單來講,慢查詢和索引沒有必然聯系,一個SQL語句的執行效率最終要看的是掃描行數。另外可以使用虛擬列和聯合索引來提升復雜查詢的執行效率。






















