明明加了唯一索引,為什么還是產生重復數據?

前言
前段時間我踩過一個坑:在mysql8?的一張innodb?引擎的表?中,加了唯一索引?,但最后發現數據?竟然還是重復了。
到底怎么回事呢?
本文通過一次踩坑經歷,聊聊唯一索引,一些有意思的知識點。

一、還原問題現場
前段時間,為了防止商品組產生重復的數據,我專門加了一張防重表。
如果大家對防重表,比較感興趣,可以看看我的另一篇文章 《??高并發下如何防重???》,里面有詳細的介紹。
問題就出在商品組的防重表上。
具體表結構如下:
CREATE TABLE `product_group_unique` (
`id` bigint NOT NULL,
`category_id` bigint NOT NULL,
`unit_id` bigint NOT NULL,
`model_hash` varchar(255) COLLATE utf8mb4_bin DEFAULT NULL,
`in_date` datetime NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin;
為了保證數據的唯一性,我給那種商品組防重表,建了唯一索引:
alter table product_group_unique add unique index
ux_category_unit_model(category_id,unit_id,model_hash);
根據分類編號、單位編號和商品組屬性的hash值,可以唯一確定一個商品組。
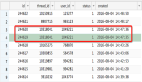
給商品組防重表創建了唯一索引?之后,第二天查看數據,發現該表中竟然產生了重復的數據:

表中第二條數據和第三條數據重復了。
這是為什么呢?
二、索引字段包含null
如果你仔細查看表中的數據,會發現其中一個比較特殊地方:商品組屬性的hash值(model_hash字段)可能為??null??,即商品組允許不配置任何屬性。
在product_group_unique表中插入了一條model_hash字段等于100的重復數據: 執行結果:
執行結果: 從上圖中看出,mysql的唯一性約束生效了,重復數據被攔截了。
從上圖中看出,mysql的唯一性約束生效了,重復數據被攔截了。
接下來,我們再插入兩條model_hash為null的數據,其中第三條數據跟第二條數據中category_id、unit_id和model_hash字段值都一樣。 從圖中看出,竟然執行成功了。
從圖中看出,竟然執行成功了。
換句話說,如果唯一索引的字段中,出現了null值,則唯一性約束不會生效。
最終插入的數據情況是這樣的:
- 當model_hash字段不為空時,不會產生重復的數據。
- 當model_hash字段為空時,會生成重復的數據。
我們需要特別注意:創建唯一索引的字段,都不能允許為null,否則mysql的唯一性約束可能會失效。
三、邏輯刪除表加唯一索引
我們都知道唯一索引非常簡單好用,但有時候,在表中它并不好加。
不信,我們一起往下看。
通常情況下,要刪除表的某條記錄的話,如果用??delete??語句操作的話。
例如:
delete from product where id=123;
這種delete操作是物理刪除,即該記錄被刪除之后,后續通過sql語句基本查不出來。(不過通過其他技術手段可以找回,那是后話了)
還有另外一種是邏輯刪除?,主要是通過update語句操作的。
例如:
update product set delete_status=1,edit_time=now(3)
where id=123;
邏輯刪除需要在表中額外增加一個刪除狀態字段,用于記錄數據是否被刪除。在所有的業務查詢的地方,都需要過濾掉已經刪除的數據。
通過這種方式刪除數據之后,數據任然還在表中,只是從邏輯上過濾了刪除狀態的數據而已。
其實對于這種邏輯刪除的表,是沒法加唯一索引的。
為什么呢?
假設之前給商品表中的name和model加了唯一索引,如果用戶把某條記錄刪除了,delete_status設置成1了。后來,該用戶發現不對,又重新添加了一模一樣的商品。
由于唯一索引的存在,該用戶第二次添加商品會失敗,即使該商品已經被刪除了,也沒法再添加了。
這個問題顯然有點嚴重。
有人可能會說:把name、model和delete_status?三個字段同時做成唯一索引不就行了?
答:這樣做確實可以解決用戶邏輯刪除了某個商品,后來又重新添加相同的商品時,添加不了的問題。但如果第二次添加的商品,又被刪除了。該用戶第三次添加相同的商品,不也出現問題了?
由此可見,如果表中有邏輯刪除功能,是不方便創建唯一索引的。
但如果真的想給包含邏輯刪除的表,增加唯一索引,該怎么辦呢?
1、刪除狀態+1
通過前面知道,如果表中有邏輯刪除功能,是不方便創建唯一索引的。
其根本原因是,記錄被刪除之后,delete_status會被設置成1,默認是0。相同的記錄第二次刪除的時候,delete_status被設置成1,但由于創建了唯一索引(把name、model和delete_status三個字段同時做成唯一索引),數據庫中已存在delete_status為1的記錄,所以這次會操作失敗。
我們為啥不換一種思考:不要糾結于delete_status為1,表示刪除,當delete_status為1、2、3等等,只要大于1都表示刪除。
這樣的話,每次刪除都獲取那條相同記錄的最大刪除狀態,然后加1。
這樣數據操作過程變成:
- 添加記錄a,delete_status=0。
- 刪除記錄a,delete_status=1。
- 添加記錄a,delete_status=0。
- 刪除記錄a,delete_status=2。
- 添加記錄a,delete_status=0。
- 刪除記錄a,delete_status=3。
由于記錄a,每次刪除時,delete_status都不一樣,所以可以保證唯一性。
該方案的優點是:不用調整字段,非常簡單和直接。
缺點是:可能需要修改sql邏輯,特別是有些查詢sql語句,有些使用delete_status=1判斷刪除狀態的,需要改成delete_status>=1。
2、增加時間戳字段
導致邏輯刪除表,不好加唯一索引最根本的地方在邏輯刪除那里。
我們為什么不加個字段,專門處理邏輯刪除的功能呢?
答:可以增加時間戳字段。
把name、model、delete_status和timeStamp,四個字段同時做成唯一索引
在添加數據時,timeStamp字段寫入默認值1。
然后一旦有邏輯刪除操作,則自動往該字段寫入時間戳。
這樣即使是同一條記錄,邏輯刪除多次,每次生成的時間戳也不一樣,也能保證數據的唯一性。
時間戳一般精確到秒。
除非在那種極限并發的場景下,對同一條記錄,兩次不同的邏輯刪除操作,產生了相同的時間戳。
這時可以將時間戳精確到毫秒。
該方案的優點是:可以在不改變已有代碼邏輯的基礎上,通過增加新字段實現了數據的唯一性。
缺點是:在極限的情況下,可能還是會產生重復數據。
3、增加id字段
其實,增加時間戳字段基本可以解決問題。但在在極限的情況下,可能還是會產生重復數據。
有沒有辦法解決這個問題呢?
答:增加主鍵字段:delete_id。
該方案的思路跟增加時間戳字段一致,即在添加數據時給delete_id設置默認值1,然后在邏輯刪除時,給delete_id賦值成當前記錄的主鍵id。
把name、model、delete_status和delete_id,四個字段同時做成唯一索引。
這可能是最優方案,無需修改已有刪除邏輯,也能保證數據的唯一性。
四、重復歷史數據如何加唯一索引?
前面聊過如果表中有邏輯刪除功能,不太好加唯一索引,但通過文中介紹的三種方案,可以順利的加上唯一索引。
但來自靈魂的一問:如果某張表中,已存在歷史重復數據,該如何加索引呢?
最簡單的做法是,增加一張防重表,然后把數據初始化進去。
可以寫一條類似這樣的sql:
insert into product_unqiue(id,name,category_id,unit_id,model)
select max(id), select name,category_id,unit_id,model from product
group by name,category_id,unit_id,model;
這樣做可以是可以,但今天的主題是直接在原表中加唯一索引,不用防重表。
那么,這個唯一索引該怎么加呢?
其實可以借鑒上一節中,增加id字段的思路。
增加一個delete_id字段。
不過在給product表創建唯一索引之前,先要做數據處理。
獲取相同記錄的最大id:
select max(id), select name,category_id,unit_id,model from product
group by name,category_id,unit_id,model;
然后將delete_id字段設置成1。
然后將其他的相同記錄的delete_id字段,設置成當前的主鍵。
這樣就能區分歷史的重復數據了。
當所有的delete_id字段都設置了值之后,就能給name、model、delete_status和delete_id,四個字段加唯一索引了。
完美。
五、給大字段加唯一索引
接下來,我們聊一個有趣的話題:如何給大字段增加唯一索引。
有時候,我們需要給幾個字段同時加一個唯一索引,比如給name、model、delete_status和delete_id等。
但如果model字段很大,這樣就會導致該唯一索引,可能會占用較多存儲空間。
我們都知道唯一索引,也會走索引。
如果在索引的各個節點中存大數據,檢索效率會非常低。
由此,有必要對唯一索引長度做限制。
目前mysql innodb存儲引擎中索引允許的最大長度是3072 bytes,其中unqiue key最大長度是1000 bytes。
如果字段太大了,超過了1000 bytes,顯然是沒法加唯一索引的。
此時,有沒有解決辦法呢?
1、增加hash字段
我們可以增加一個hash字段,取大字段的hash值,生成一個較短的新值。該值可以通過一些hash算法生成,固定長度16位或者32位等。
我們只需要給name、hash、delete_status和delete_id字段,增加唯一索引。
這樣就能避免唯一索引太長的問題。
但它也會帶來一個新問題:
一般hash算法會產生hash沖突,即兩個不同的值,通過hash算法生成值相同。
當然如果還有其他字段可以區分,比如:name,并且業務上允許這種重復的數據,不寫入數據庫,該方案也是可行的。
2、不加唯一索引
如果實在不好加唯一索引,就不加唯一索引,通過其他技術手段保證唯一性。
如果新增數據的入口比較少,比如只有job,或者數據導入,可以單線程順序執行,這樣就能保證表中的數據不重復。
如果新增數據的入口比較多,最終都發mq消息,在mq消費者中單線程處理。
3、redis分布式鎖
由于字段太大了,在mysql中不好加唯一索引,為什么不用redis分布式鎖呢?
但如果直接加給name、model、delete_status和delete_id字段,加redis分布式鎖,顯然沒啥意義,效率也不會高。
我們可以結合5.1章節,用name、model、delete_status和delete_id字段,生成一個hash值,然后給這個新值加鎖。
即使遇到hash沖突也沒關系,在并發的情況下,畢竟是小概率事件。

六、批量插入數據
有些小伙們,可能認為,既然有redis分布式鎖了,就可以不用唯一索引了。
那是你沒遇到,批量插入數據的場景。
假如通過查詢操作之后,發現有一個集合:list的數據,需要批量插入數據庫。
如果使用redis分布式鎖,需要這樣操作:
for(Product product: list) {
try {
String hash = hash(product);
rLock.lock(hash);
//查詢數據
//插入數據
} catch (InterruptedException e) {
log.error(e);
} finally {
rLock.unlock();
}
}
需要在一個循環中,給每條數據都加鎖。
這樣性能肯定不會好。
當然有些小伙伴持反對意見,說使用redis的pipeline批量操作不就可以了?
也就是一次性給500條,或者1000條數據上鎖,最后使用完一次性釋放這些鎖?
想想都有點不靠譜,這個鎖得有多大呀。
極容易造成鎖超時,比如業務代碼都沒有執行完,鎖的過期時間就已經到了。
針對這種批量操作,如果此時使用mysql的唯一索引,直接批量insert即可,一條sql語句就能搞定。
數據庫會自動判斷,如果存在重復的數據,會報錯。如果不存在重復數據,才允許插入數據。