數(shù)據(jù)流中的中位數(shù),確實(shí)輕敵了
本文轉(zhuǎn)載自微信公眾號「bigsai」,作者大賽 。轉(zhuǎn)載本文請聯(lián)系bigsai公眾號。
前言
大家好,我是bigsai,今天忙到爆炸(暫不透露以后透露),給大家分享一個(gè)巧妙的問題,五分鐘掌握。
今天在刷題時(shí)候,遇到一個(gè)hard問題,也是挺有意思,在劍指offer的第41題和力扣【數(shù)據(jù)流中的中位數(shù)】。
題目描述是這樣的:
中位數(shù)是有序列表中間的數(shù)。如果列表長度是偶數(shù),中位數(shù)則是中間兩個(gè)數(shù)的平均值。
例如,
[2,3,4] 的中位數(shù)是 3
[2,3] 的中位數(shù)是 (2 + 3) / 2 = 2.5
設(shè)計(jì)一個(gè)支持以下兩種操作的數(shù)據(jù)結(jié)構(gòu):
void addNum(int num) - 從數(shù)據(jù)流中添加一個(gè)整數(shù)到數(shù)據(jù)結(jié)構(gòu)中。
double findMedian() - 返回目前所有元素的中位數(shù)。
其實(shí)問題也很簡單,也就是一組數(shù)據(jù),找出它的中位數(shù),然后有所不同的是這組數(shù)據(jù)可能會新增一些其他數(shù)據(jù),也就是要我們自己維護(hù)這么一個(gè)數(shù)據(jù)結(jié)構(gòu)去盡量高效的完成它。
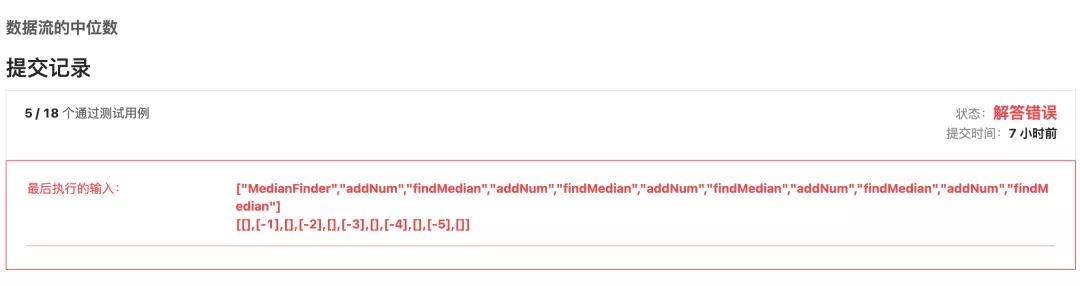
我打開這題力扣上的額描述,它好像就在誘惑我,告訴我什么!

然后我就以為真實(shí)的數(shù)據(jù)就在這個(gè)范圍,然后一頓操作猛如虎,一提交直接GG。不過這個(gè)問題是個(gè)非常好的問題,等到后面講,仔細(xì)先看看!
好了不多說了,我們進(jìn)入正題,看看這個(gè)經(jīng)典問題到底如何分析。
小白級別方法(無腦排序)
這個(gè)問題的解決老少皆宜,小白也有小白的方法,題不在難,能過就行(只對小白有效哇)。
一組數(shù)據(jù)存儲,我用數(shù)組、List都可以,而中位數(shù),其實(shí)就是中間一個(gè)(偶數(shù)兩個(gè)均值)數(shù),這個(gè)也好辦啊,排序啊!
一個(gè)ArrayList()海納百川(不定長數(shù)組可以存儲數(shù)據(jù)),一行Arrays.sort()走天下。用編程語言中已經(jīng)存在的集合和API可以輕松實(shí)現(xiàn)!
分析一下這個(gè)算法的時(shí)間復(fù)雜度,每次插入時(shí)候需要排序 nlogn,查詢時(shí)間近O(1);次數(shù)多的話時(shí)間復(fù)雜度還是蠻高的。
具體代碼為:
- /** initialize your data structure here. */
- public MedianFinder() {
- }
- List<Integer>list=new ArrayList<>();
- public void addNum(int num) {
- list.add(num);
- list.sort(null);
- }
- public double findMedian() {
- if(list.size()%2==1)
- return list.get(list.size()/2);
- else {
- return (double) (list.get((list.size()-1)/2)+list.get(list.size()/2))/2;
- }
- }
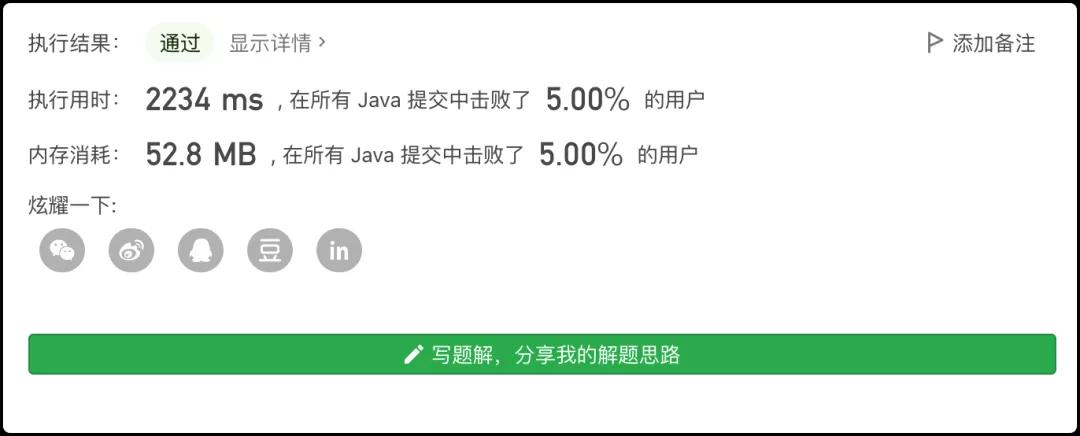
一看結(jié)果,2000+ms,這也是一種極限了,這種方法僅限于小白,只為求過。
大白級別的方法(插入排序)
大白比小白稍微強(qiáng)一點(diǎn),比較它大一點(diǎn)嘛,懂得多一點(diǎn)。
大白看到:這個(gè)序列剛開始沒有!然后一點(diǎn)一點(diǎn)在原有的基礎(chǔ)上增加長度,如果每次都打亂排序那代價(jià)有點(diǎn)高!所以能不能復(fù)用上次已經(jīng)排好序的結(jié)果?
這不就插入排序嘛!
每次新來元素相當(dāng)于插入排序的最后一步使他有序,然后在插入……
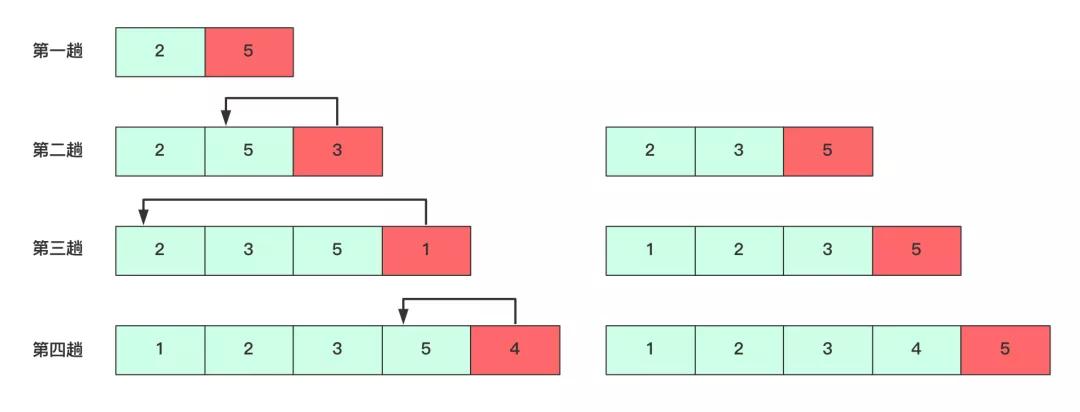
這個(gè)流程每次插入的時(shí)候由兩個(gè)部分組成,查找和移動,其中查找花費(fèi)O(n),插入也是O(n)。時(shí)間復(fù)雜度依然是O(n)。
可以維護(hù)常數(shù)表示數(shù)據(jù)總個(gè)數(shù),查找中位數(shù)時(shí)候可以直接根據(jù)數(shù)量查找,時(shí)間復(fù)雜度為O(1).這樣的時(shí)間復(fù)雜度在插入上優(yōu)化為O(n)相比O(nlogn)有很大的提升。
但是聰明的大白還能發(fā)現(xiàn)一些閃光點(diǎn),數(shù)組前面有序的,只是插入最后一個(gè)元素需要鎖定在有序順序結(jié)構(gòu)中的位置,線性一個(gè)個(gè)查找太耗時(shí)了哇!這明顯就是一個(gè)二分應(yīng)用的場景么!可以使用二分法找到插入的位置,然后插入。
二分+插入的時(shí)間復(fù)雜度是多少呢?
記住,不是O(logn),二分查找每一次的時(shí)間復(fù)雜度確實(shí)是O(logn),但插入操作的時(shí)間復(fù)雜度依舊是O(n),總的時(shí)間復(fù)雜度取最高量級 O(logn)+O(n)=O(n)。
所以這里以后如果遇到某個(gè)面試官問你:插入排序使用二分查找優(yōu)化時(shí)間復(fù)雜度是多少?你一定要堅(jiān)定的回答:是O(n2),從單詞操作來看,雖然查詢變?yōu)镺(logn)但是插入依舊O(n),所以n個(gè)數(shù)時(shí)間復(fù)雜度依舊為O(n2)。
好了既然解釋清楚,一頓操作猛如虎,直接上代碼:
- class MedianFinder {
- /** initialize your data structure here. */
- public MedianFinder() {
- }
- int arr[]=new int[50000];
- int count=0;
- public void addNum(int num) {
- int low=0,high=count-1;
- while (low <= high) {
- int mid = (low + high) / 2;
- int midVal = arr[mid];
- if (midVal < num)
- low = mid + 1;
- else if (midVal > num)
- high = mid-1 ;
- else
- low++;
- }
- for(int i=count-1;i>=low;i--){
- arr[i+1]=arr[i];
- }
- arr[low]=num;
- count++;
- }
- public double findMedian() {
- if(count%2==1)
- return arr[count/2];
- else
- return (double) (arr[count/2-1]+arr[count/2])/2;
- }
- }
提交之后,200+ms,比起前面小白的無腦排序優(yōu)化了很多,但只擊敗了10%用戶,說明方法還是不夠好,還是很白。
大佬的解法(雙堆/優(yōu)先隊(duì)列)
這個(gè)問題的話其實(shí)也能想出來,但是確實(shí)除了這個(gè)問題沒見到兩個(gè)隊(duì)這么玩的,也算是打開眼界一回。
在前面,我們講過堆排序 和優(yōu)先隊(duì)列的原理 ,里面詳細(xì)的講解了 堆這種數(shù)據(jù)結(jié)構(gòu),我們簡單回顧一下堆:
堆是一種完全二叉樹(即最后一層從左向右存在節(jié)點(diǎn)連續(xù)),因?yàn)槭峭耆鏄湮覀兘?jīng)常用數(shù)組存儲,可以通過二叉樹下標(biāo)轉(zhuǎn)換很好的鎖定位置進(jìn)行交換。
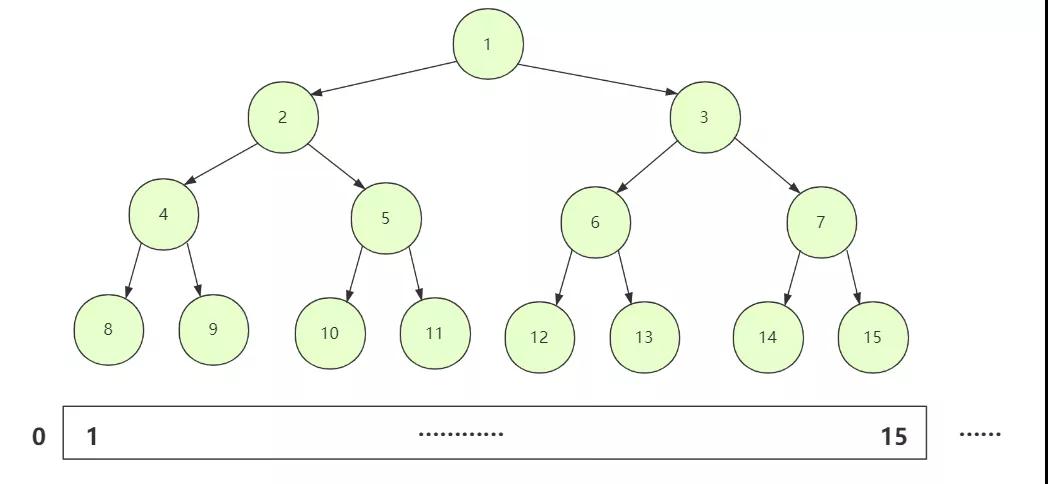
堆分為大根堆和小根堆:
如果所有節(jié)點(diǎn)大于孩子節(jié)點(diǎn)值,那么這個(gè)堆叫做大根堆,堆的最大值在根節(jié)點(diǎn)。
如果所有節(jié)點(diǎn)小于孩子節(jié)點(diǎn)值,那么這個(gè)堆叫做小根堆,堆的最小值在根節(jié)點(diǎn)。
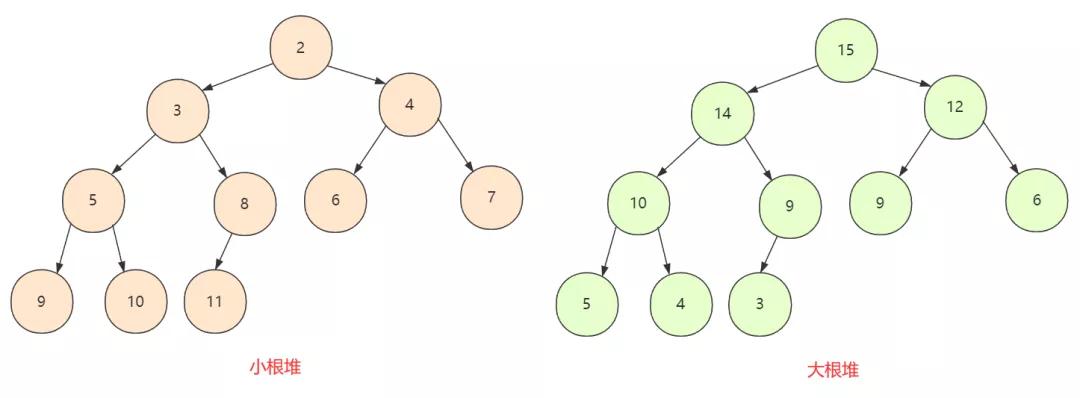
了解完這些基本解決這題就夠了,這里不需要知道堆、優(yōu)先隊(duì)列的具體實(shí)現(xiàn)。但是堆和優(yōu)先隊(duì)列,怎么應(yīng)用到這個(gè)中位數(shù)查找呢?
這個(gè)就很巧妙了,我們將數(shù)據(jù)等半分到兩個(gè)堆中,其中一個(gè)是小根堆,一個(gè)是大根堆,小根堆存最大的一半數(shù)據(jù),大的中最小的在堆頂;大根堆存最小的一半數(shù)據(jù),小的中最大的在堆頂,中位數(shù)就只可能在兩個(gè)堆頂部分產(chǎn)生啦!
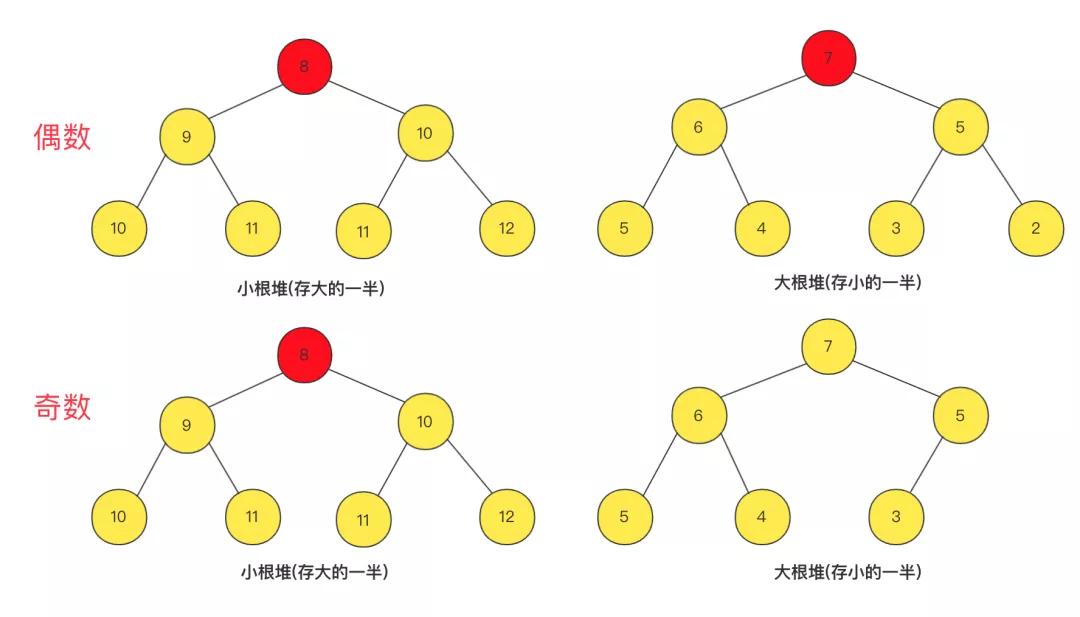
但是在具體實(shí)現(xiàn)過程中,也有很多需要注意的地方,再添加時(shí)候要先判斷和其中一個(gè)堆頂比較大小,應(yīng)該加到哪一個(gè)堆(優(yōu)先隊(duì)列)中,但是添加之后可能數(shù)值一直遞增很大或者數(shù)值一直遞減很小可能造成兩個(gè)堆元素?cái)?shù)量不平衡,那么就要將其中少的加到多的中。
這里我在實(shí)現(xiàn)的時(shí)候約束小根堆的元素個(gè)數(shù)等于大根堆個(gè)數(shù)(偶數(shù))或者等于大根堆個(gè)數(shù)加一(奇數(shù)),在奇數(shù)情況就直接取小根堆頂返回即可。因?yàn)镴ava已經(jīng)實(shí)現(xiàn)優(yōu)先隊(duì)列,你不需要詳細(xì)實(shí)現(xiàn)其中細(xì)節(jié)(大佬可以試試參考以前我寫的優(yōu)先隊(duì)列實(shí)現(xiàn))。
分析這個(gè)時(shí)間復(fù)雜度,每個(gè)堆插入、刪除的時(shí)間復(fù)雜度級別是O(log n/2),即使如果面臨元素平衡可能多操作兩次,但是時(shí)間復(fù)雜度還是O(logn)級別。比起O(n)快了不少,數(shù)據(jù)量越大體現(xiàn)越明顯。
具體代碼為:
- class MedianFinder {
- /** initialize your data structure here. */
- public MedianFinder() {
- }
- Queue<Integer>q1=new PriorityQueue<>();//小根堆 放大的數(shù)據(jù)
- //大根堆
- Queue<Integer>q2=new PriorityQueue<>(new Comparator<Integer>() {
- @Override
- public int compare(Integer o1, Integer o2) {
- return o2-o1;
- }
- });
- public void addNum(int num) {
- if(q1.isEmpty())
- q1.add(num);
- else if(num>q1.peek()){//插入到小根堆
- q1.add(num);
- if (q1.size()>q2.size()+1){
- q2.add(q1.poll());
- }
- }
- else{//插入到大根堆
- q2.add(num);
- if (q2.size()>q1.size()){
- q1.add(q2.poll());
- }
- }
- }
- public double findMedian() {
- if(q1.size()==q2.size())
- return (double)(q1.peek()+q2.peek())/2;
- else
- return q1.peek();
- }
- }
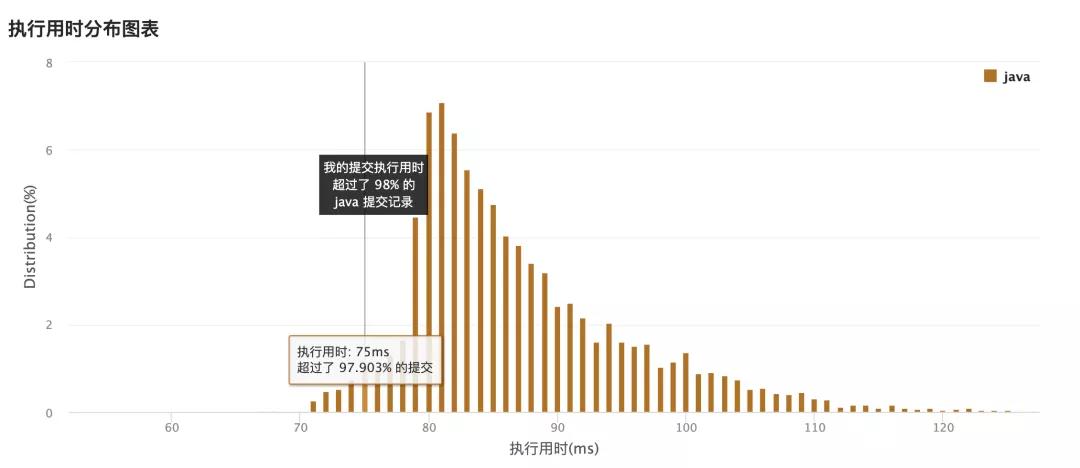
執(zhí)行區(qū)間75ms,比起上一個(gè)大白又好很多,這個(gè)雙堆,真的太妙了!我也是第一次見。
提升
對于這個(gè)問題,還有一些妖魔鬼怪用二叉搜索樹來做,理論上也是可行的,插入效率不一定很穩(wěn)定,查詢效率比較低(二叉樹的中序排序)。
但是文初提到的場景問題還是要仔細(xì)思考一下,面試場景很可能會問到:
1.如果數(shù)據(jù)流中所有整數(shù)都在 0 到 100 范圍內(nèi),你將如何優(yōu)化你的算法?
2.如果數(shù)據(jù)流中 99% 的整數(shù)都在 0 到 100 范圍內(nèi),你將如何優(yōu)化你的算法?
對于第一個(gè)問題,應(yīng)該用什么方法優(yōu)化呢?
如果還是采用傳統(tǒng)的雙堆,如果數(shù)據(jù)量非常大的情況下,效率肯定還是有優(yōu)化空間,當(dāng)數(shù)據(jù)比較集中分布的時(shí)候,肯定要考慮計(jì)數(shù)排序啊!
如果數(shù)據(jù)分布在0-100之間,可以直接開一個(gè)101大小的數(shù)組,遇到一個(gè)數(shù)就將其對應(yīng)位置值加一,不光0-100 可以這樣,在某個(gè)范圍內(nèi)都可以通過移動表示。
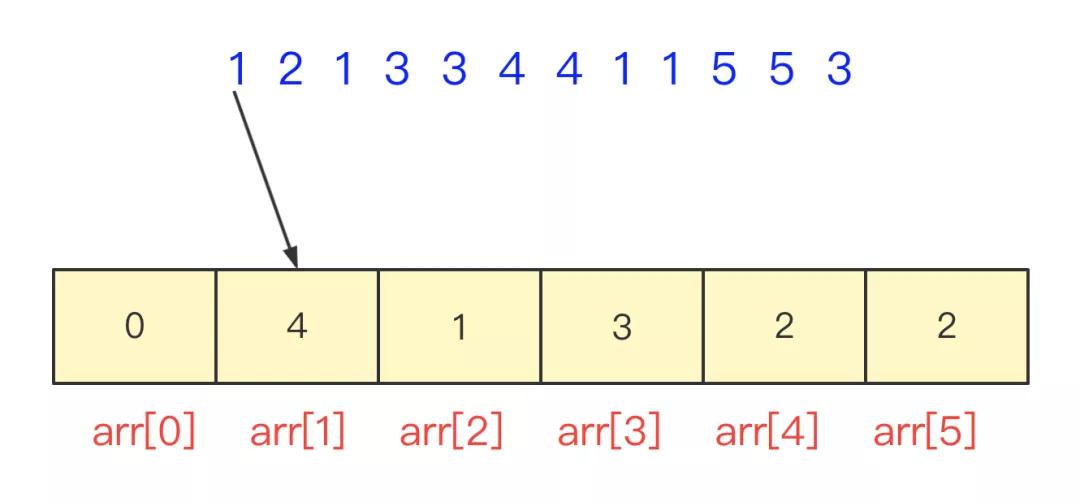
然后你找到中位數(shù),只需要枚舉疊加找到中間位置的數(shù)啦。
不過你可以再進(jìn)行優(yōu)化,將這個(gè)計(jì)數(shù)排序修改一下,用數(shù)組值表示小于當(dāng)前位置值的個(gè)數(shù)。這樣這個(gè)數(shù)組值是連續(xù)遞增的,查找的時(shí)候還可以使用二分優(yōu)化。
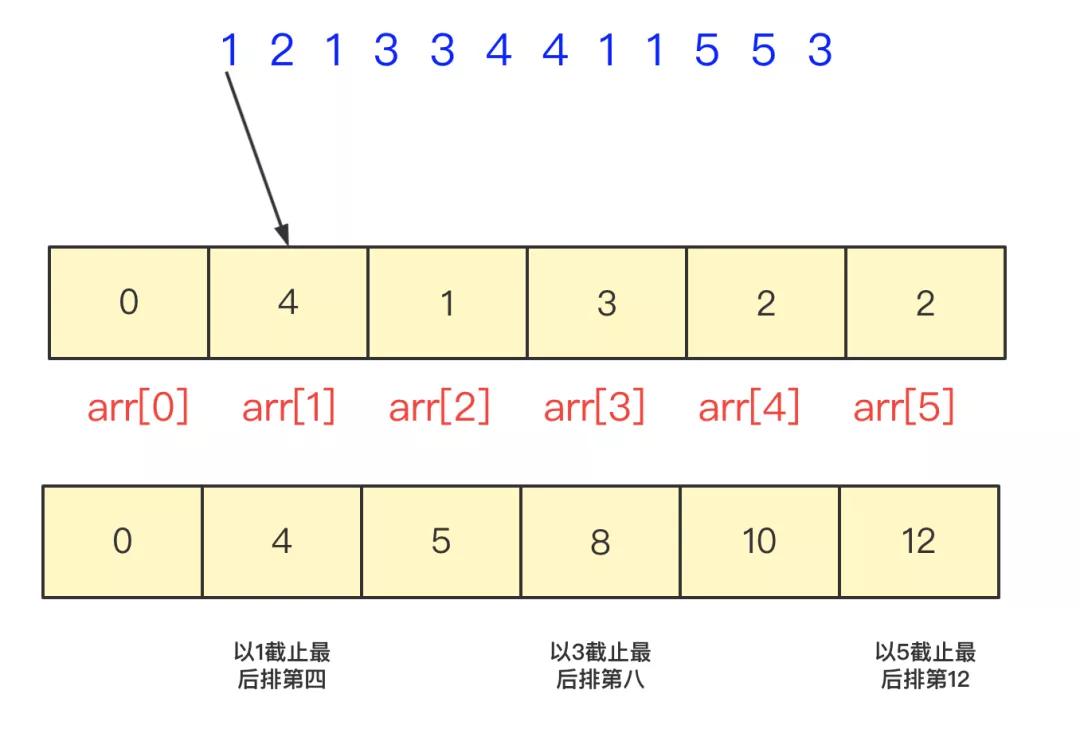
不過具體實(shí)現(xiàn)上,可能還有一些你需要考慮的,分析算法復(fù)雜度,每次插入操作,對應(yīng)小標(biāo)以及之后值都要加一,所以操作次數(shù)不超過50,而查詢操作使用二分法也不超過10次,所以在數(shù)據(jù)比較集中 數(shù)據(jù)個(gè)數(shù)很多有大量重復(fù)情況,使用計(jì)數(shù)排序是非常好的。
另外,如果99%在0-100范圍內(nèi)也很容易哇,就是在前后邊緣特意設(shè)置0和102,超過100的放到102號,小于0的放到0位置,剩下每次來x放x+1位置,因?yàn)橹形粩?shù)肯定出現(xiàn)在0-100所以這個(gè)依舊可行!