













如何采用深度學習進行對象檢測
譯文【51CTO.com快譯】深度神經網絡因其具有的處理視覺信息的強大能力而聞名。在過去幾年中,它們已成為許多計算機視覺應用程序的關鍵組成部分。
神經網絡可以解決的關鍵問題之一是檢測和定位圖像中的對象。對象檢測用于許多不同的領域,其中包括自動駕駛、視頻監控、醫療保健等。

以下簡要回顧幫助計算機檢測對象的深度學習架構:
卷積神經網絡(CNN)
卷積神經網絡(CNN)是基于深度學習的計算機視覺應用的一個關鍵組成部分。卷積神經網絡(CNN) 是由深度學習技術先驅Yann LeCun在上世紀80年代開發的一種神經網絡,可以有效捕捉多維空間中的模式。這使得卷積神經網絡(CNN)特別適用于檢測圖像,盡管它們也用于處理其他類型的數據。為了更簡單地敘述,在本文中考慮的卷積神經網絡是二維的。
每個卷積神經網絡都由一個或多個卷積層組成,這是一個從輸入圖像中提取有意義值的軟件組件。每個卷積層都由多個過濾器和矩陣組成,這些過濾器和矩陣在圖像上滑動,并在不同位置注冊像素值的加權和。每個過濾器具有不同的值,并從輸入圖像中提取不同的特征。而卷積層的輸出是一組“特征圖”。
當堆疊在一起時,卷積層可以檢測視覺模式的層次結構。例如,較低層將為垂直和水平邊、角和其他簡單模式生成特征圖。較高的層可以檢測復雜的圖案,例如網格和圓形。而最高層可以檢測更復雜的對象,例如汽車、房屋、樹木和人員。


神經網絡的每一層都對輸入圖像中的特定特征進行編碼。
大多數卷積神經網絡使用池化層來逐漸減小其特征圖的大小,并保留最突出的部分。最大池化(Max-pooling)是目前卷積神經網絡(CNN)中使用的主要池化層類型,它保持像素塊中的最大值。例如,如果使用大小為2像素的池化層,它將從前一層生成的特征圖中提取2×2像素的塊并保留最大值。這一操作將其特征圖的大小減半,并保留最相關的特征。池化層使卷積神經網絡(CNN)能夠泛化其能力,并且對跨圖像的對象位移不那么敏感。
最后,卷積層的輸出被展平為一個一維矩陣,該矩陣是圖像中包含的特征的數值表示。然后將該矩陣輸入到一系列“完全連接”的人工神經元層中,這些層將特征映射到網絡預期的輸出類型。

卷積神經網絡(CNN)的架構
卷積神經網絡最基本的任務是圖像分類,其中網絡將圖像作為輸入并返回一系列值,這些值表示圖像屬于多個類別之一的概率。例如,假設你要訓練一個神經網絡來檢測流行的開源數據集ImageNet中包含的所有1,000類對象。在這種情況下,輸出層將有1,000個數字輸出,每個輸出都包含圖像屬于這些類別之一的概率。
你可以從頭開始創建和測試自己的卷積神經網絡。但大多數機器學習研究人員和開發人員使用幾種主流的卷積神經網絡,例如AlexNet、VGG16和ResNet-50。
對象檢測數據集
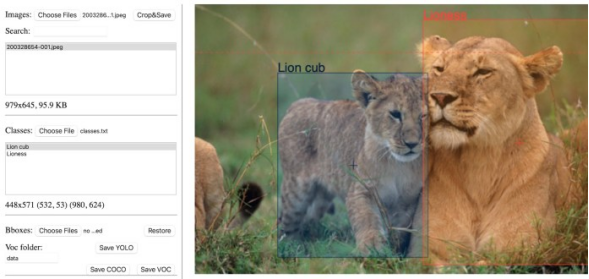
對象檢測網絡需要在精確標注的圖像上進行訓練
雖然圖像分類網絡可以判斷圖像是否包含某個對象,但它不會說明對象在圖像中的位置。對象檢測網絡提供圖像中包含的對象類別,并提供該對象坐標的邊界框。
對象檢測網絡與圖像分類網絡非常相似,并使用卷積層來檢測視覺特征。事實上,大多數對象檢測網絡使用圖像分類的卷積神經網絡(CNN)并將其重新用于對象檢測。
對象檢測是一個有監督的機器學習問題,這意味著必須在標記的示例上訓練模型。訓練數據集中的每張圖像都必須附有一個文件,其中包含其包含的對象的邊界和類別。有幾個開源工具可以創建對象檢測注釋。
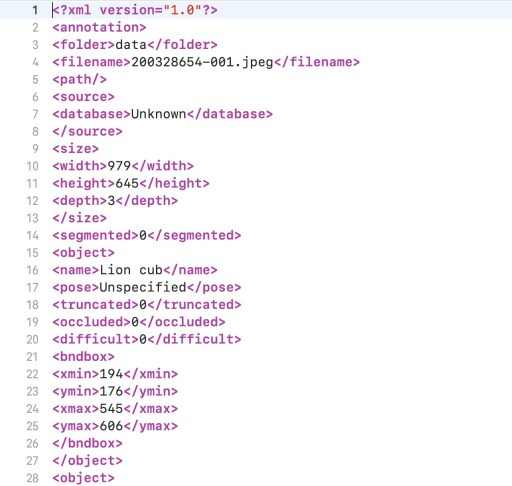
對象檢測訓練數據的注釋文件示例
對象檢測網絡在注釋數據上進行訓練,直到它可以在圖像中找到與每種對象對應的區域。
以下了解一些對象檢測神經網絡架構。
R-CNN深度學習模型

R-CNN架構
基于區域的卷積神經網絡(R-CNN)由加州大學伯克利分校的人工智能研究人員于2014年提出。R-CNN由三個關鍵組件組成:
首先,區域選擇器使用“選擇性搜索”算法,在圖像中查找可能代表對象的像素區域,也稱為“感興趣區域”(RoI)。區域選擇器為每個圖像生成大約2,000個感興趣區域(RoI)。
其次,感興趣區域(RoI)被壓縮成預定義的大小,并傳遞給卷積神經網絡。卷積神經網絡(CNN)對每個區域進行處理,通過一系列卷積操作分別提取特征,卷積神經網絡(CNN)使用全連接層將特征圖編碼為一維數值向量。
最后,分類器機器學習模型將從卷積神經網絡(CNN)獲得的編碼特征映射到輸出類。分類器有一個單獨的“背景”輸出類,它對應于任何不是對象的東西。

使用R-CNN進行對象檢測
最初有關R-CNN的一篇論文建議研究人員使用AlexNet卷積神經網絡進行特征提取,并使用支持向量機(SVM)進行分類。但在這篇論文發表后的幾年后,研究人員使用更新的網絡架構和分類模型來提高R-CNN的性能。
R-CNN存在一些問題。首先,模型必須為每張圖像生成和裁剪2,000個單獨的區域,這可能需要很長時間。其次,模型必須分別計算2,000個區域的特征。這需要大量計算并減慢了過程,使得R-CNN不適合實時對象檢測。最后,該模型由三個獨立的組件組成,這使得集成計算和提高速度變得困難。
Fast R-CNN

Fast R-CNN架構
2015年,這篇R-CNN論文的第一作者提出了一種名為Fast R-CNN的新架構,解決了其前身的一些問題。FastR-CNN將特征提取和區域選擇集成到單個機器學習模型中。
Fast R-CNN接收圖像和一組感興趣區域(RoI),并返回圖像中檢測到的對象的邊界框和類的列表。
Fast R-CNN的關鍵創新之一是“RoI池化層”,該操作采用卷積神經網絡(CNN)特征圖和圖像的感興趣區域,并為每個區域提供相應的特征。這使得Fast R-CNN能夠在一次性提取圖像中所有感興趣區域的特征,而R-CNN則分別處理每個區域。這顯著提高了處理速度。
然而還有一個問題仍未解決。Fast R-CNN仍然需要提取圖像區域并將其作為輸入提供給模型。FastR-CNN還沒有準備好進行實時對象檢測。
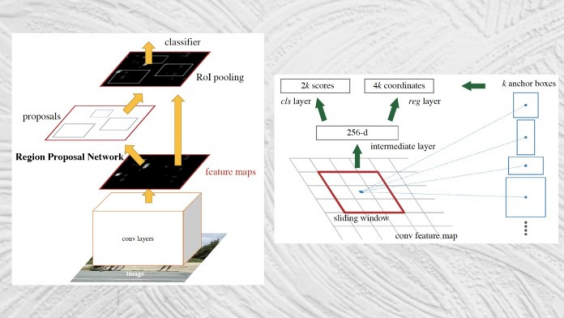
Faster R-CNN

Faster R-CNN架構
Faster R-CNN于2016年推出,通過將區域提取機制集成到對象檢測網絡中,解決了對象檢測最后的難題。
Faster R-CNN將圖像作為輸入,并返回對象類及其相應邊界框的列表。
Faster R-CNN的架構在很大程度上類似于FastR-CNN的架構。它的主要創新是“區域提議網絡”(RPN),該組件采用卷積神經網絡生成的特征圖,并提出一組可能定位對象的邊界框。然后將提議的區域傳遞給RoI池化層。其余的過程類似于Fast R-CNN。
通過將區域檢測集成到主要的神經網絡架構中,Faster R-CNN實現了接近實時的目標檢測速度。
YOLO

YOLO架構
2016年,華盛頓大學、艾倫人工智能研究所和Facebook人工智能研究所的研究人員推出了“YOLO”,這是一個神經網絡家族,通過深度學習提高了對象檢測的速度和準確性。
YOLO的主要改進是將整個對象檢測和分類過程集成在一個網絡中。YOLO不是分別提取特征和區域,而是通過一個個網絡在一次傳遞中執行所有操作,因此被稱之為“你只看一次” (YOLO)。
YOLO能夠以視頻流幀率執行對象檢測,適用于需要實時推理的應用程序。
在過去的幾年中,深度學習對象檢測取得了長足的進步,從一個由不同組件拼湊而成的單一神經網絡發展成為功能強大并且更加高效的神經網絡。如今,許多應用程序使用對象檢測網絡作為其主要組件,這一技術存在于人們的手機、計算機、相機、汽車等設備中。而人們如果了解更加先進的神經網絡能夠實現什么功能,這將是有趣的事情,可能也會令人毛骨悚然。
原文標題:An introduction to object detection with deep learning,作者:Ben Dickson
【51CTO譯稿,合作站點轉載請注明原文譯者和出處為51CTO.com】




















