深度學習檢測小目標常用方法
引言
在深度學習目標檢測中,特別是人臉檢測中,小目標、小人臉的檢測由于 分辨率低,圖片模糊,信息少,噪音多 ,所以一直是一個實際且常見的困難問題。 不過在這幾年的發展中,也涌現了一些提高小目標檢測性能的解決手段,本文對這些手段做一個分析、整理和總結。
歡迎探討,本文持續維護。
實驗平臺
N/A
傳統的圖像金字塔和多尺度滑動窗口檢測
最開始在深度學習方法流行之前,對于不同尺度的目標,大家普遍使用將原圖build出 不同分辨率的圖像金字塔 ,再對每層金字塔用固定輸入分辨率的分類器在該層滑動來檢測目標,以求在金字塔底部檢測出小目標; 或者只用一個原圖,在原圖上,用 不同分辨率的分類器 來檢測目標,以求在比較小的窗口分類器中檢測到小目標。
在著名的人臉檢測器 MTCNN (https://arxiv.org/abs/1604.02878) 中,就使用了圖像金字塔的方法來檢測不同分辨率的人臉目標。
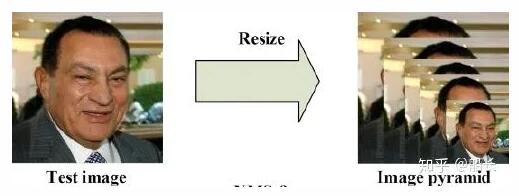
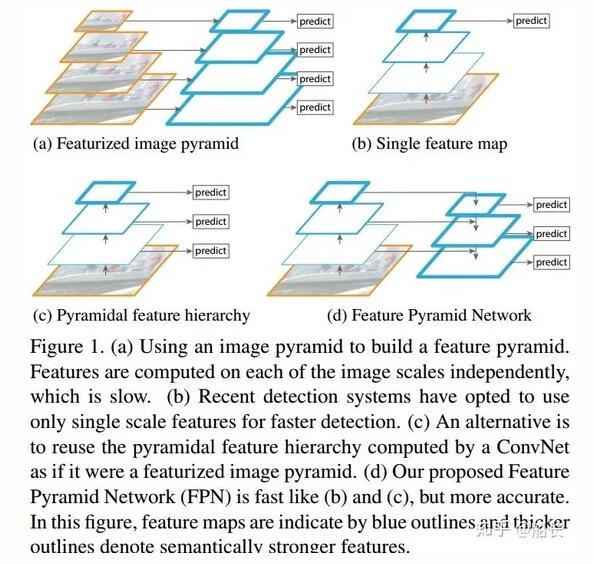
不過這種方式速度慢(雖然通常build圖像金字塔可以使用卷積核分離加速或者直接簡單粗暴地resize,但是還是需要做多次的特征提取呀),后面有人借鑒它的思想搞出了特征金字塔網絡FPN,它在不同層取特征進行融合,只需要一次前向計算,不需要縮放圖片,也在小目標檢測中得到了應用,在本文后面會講到。
簡單粗暴又可靠的Data Augmentation
深度學習的效果在某種意義上是靠大量數據喂出來的,小目標檢測的性能同樣也可以通過增加訓練集中小目標樣本的種類和數量來提升。在《深度學習中不平衡樣本的處理》[2]一文中已經介紹了許多數據增強的方案,這些方案雖然主要是解決不同類別樣本之間數量不均衡的問題的,但是有時候小目標檢測之難其中也有數據集中小樣本相對于大樣本來說數量很少的因素,所以其中很多方案都可以用在小樣本數據的增強上,這里不贅述。另外,在19年的論文 Augmentation for small object detection (https://arxiv.org/abs/1902.07296) 中,也提出了兩個簡單粗暴的方法:
1. 針對COCO數據集中包含小目標的圖片數量少的問題,使用過采樣OverSampling策略;

2. 針對同一張圖片里面包含小目標數量少的問題,在圖片內用分割的Mask摳出小目標圖片再使用復制粘貼的方法(當然,也加上了一些旋轉和縮放,另外要注意不要遮擋到別的目標)。

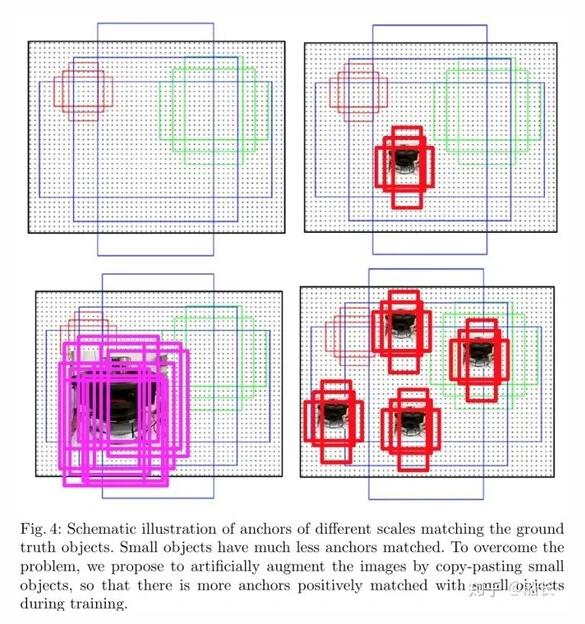
在同一張圖中有更多的小目標,在Anchor策略的方法中就會匹配出更多的正樣本。
特征融合的FPN
不同階段的特征圖對應的感受野不同,它們表達的信息抽象程度也不一樣。 淺層的特征圖感受野小,比較適合檢測小目標(要檢測大目標,則其只“看”到了大目標的一部分,有效信息不夠);深層的特征圖感受野大,適合檢測大目標(要檢測小目標,則其”看“到了太多的背景噪音,冗余噪音太多) 。所以,有人就提出了將不同階段的特征圖,都融合起來,來提升目標檢測的性能,這就是特征金字塔網絡 FPN (https://arxiv.org/abs/1612.03144) 。
在人臉領域,基本上性能好一點的方法都是用了FPN的思想,其中比較有代表性的有 RetinaFace : Single-stage Dense Face Localisation in the Wild (https://arxiv.org/pdf/1905.00641.pdf)
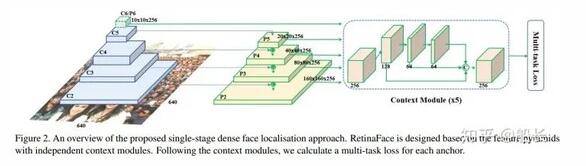
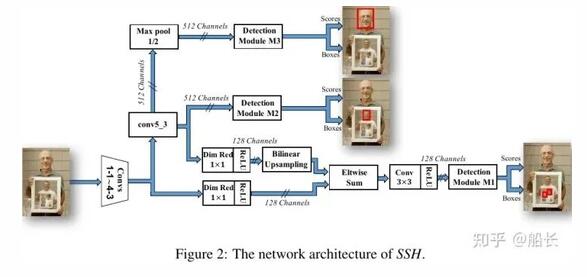
另外一個思路:既然可以在不同分辨率特征圖做融合來提升特征的豐富度和信息含量來檢測不同大小的目標,那么自然也有人會進一步地猜想,如果只用高分辨率的特征圖(淺層特征)去檢測小臉;用中間分辨率的特征圖(中層特征)去檢測大臉;最后用地分辨率的特征圖(深層特征)去檢測小臉。比如人臉檢測中的 SSH (https://arxiv.org/pdf/1708.03979.pdf) 。
合適的訓練方法SNIP,SNIPER,SAN
機器學習里面有個重要的觀點, 模型預訓練的分布要盡可能地接近測試輸入的分布 。所以,在大分辨率(比如常見的224 x 224)下訓練出來的模型,不適合檢測本身是小分辨率再經放大送入模型的圖片。如果是小分辨率的圖片做輸入,應該在小分辨率的圖片上訓練模型;再不行,應該用大分辨率的圖片訓練的模型上用小分辨率的圖片來微調fine-tune;最差的就是直接用大分辨率的圖片來預測小分辨率的圖(通過上采樣放大)。但是這是在理想的情況下的(訓練樣本數量、豐富程度都一樣的前提下,但實際上,很多數據集都是小樣本嚴重缺乏的),所以 放大輸入圖像+使用高分率圖像預訓練再在小圖上微調,在實踐中要優于專門針對小目標訓練一個分類器 。

在下圖中示意的是SNIP訓練方法, 訓練時只訓練合適尺寸的目標樣本,只有真值的尺度和Anchor的尺度接近時來用來訓練檢測器,太小太大的都不要,預測時輸入圖像多尺度,總有一個尺寸的Anchor是合適的,選擇那個最合適的尺度來預測 。對 R-FCN (https://arxiv.org/abs/1605.06409) 提出的改進主要有兩個地方,一是多尺寸圖像輸入,針對不同大小的輸入,在經過RPN網絡時需要判斷valid GT和invalid GT,以及valid anchor和invalid anchor,通過這一分類,使得得到的預選框更加的準確;二是在RCN階段,根據預選框的大小,只選取在一定范圍內的預選框,最后使用NMS來得到最終結果。
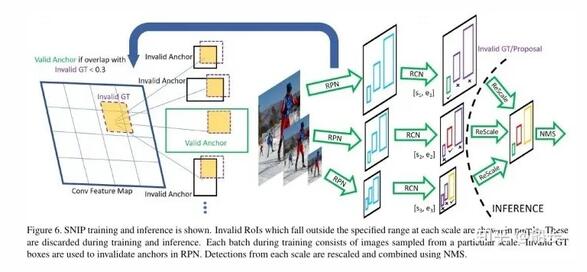
SNIPER是SNIP的實用升級版本,這里不做詳細介紹了。
更稠密的Anchor采樣和匹配策略S3FD,FaceBoxes
在前面Data Augmentation部分已經講了,復制小目標到一張圖的多個地方可以增加小目標匹配的Anchor框的個數,增加小目標的訓練權重,減少網絡對大目標的bias。同樣,反過來想,如果在數據集已經確定的情況下,我們也可以增加負責小目標的Anchor的設置策略來讓訓練時對小目標的學習更加充分。例如人臉檢測中的 FaceBoxes (https://arxiv.org/abs/1708.05234) 其中一個Contribution就是Anchor densification strategy,Inception3的anchors有三個scales(32,64,128),而32 scales是稀疏的,所以需要密集化4倍,而64 scales則需要密集化2倍。在 S3FD (http://openaccess.thecvf.com/content_ICCV_2017/papers/Zhang_S3FD_Single_Shot_ICCV_2017_paper.pdf) 人臉檢測方法中,則用了Equal-proportion interval principle來保證不同大小的Anchor在圖中的密度大致相等,這樣大臉和小臉匹配到的Anchor的數量也大致相等了。
另外,對小目標的Anchor使用比較寬松的匹配策略(比如IoU > 0.4)也是一個比較常用的手段。

先生成放大特征再檢測的GAN
Perceptual GAN 使用了GAN對小目標生成一個和大目標很相似的Super-resolved Feature(如下圖所示),然后把這個Super-resolved Feature疊加在原來的小目標的特征圖(如下下圖所示)上,以此增強對小目標特征表達來提升小目標(在論文中是指交通燈)的檢測性能。

利用Context信息的Relation Network和PyramidBox
小目標,特別是像人臉這樣的目標,不會單獨地出現在圖片中(想想單獨一個臉出現在圖片中,而沒有頭、肩膀和身體也是很恐怖的)。像 PyramidBox (https://arxiv.org/abs/1803.07737) 方法,加上一些頭、肩膀這樣的上下文Context信息,那么目標就相當于變大了一些,上下文信息加上檢測也就更容易了。

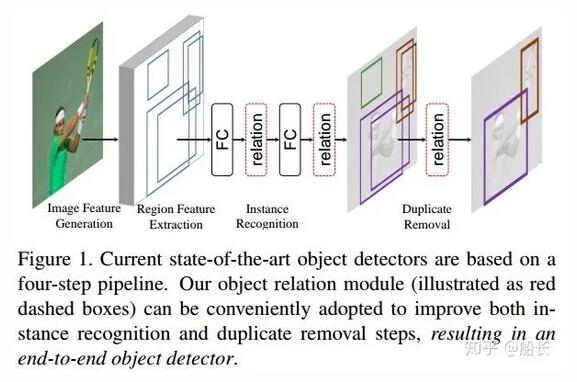
這里順便再提一下通用目標檢測中另外一種加入Context信息的思路, Relation Networks (https://arxiv.org/abs/1711.11575) 雖然主要是解決提升識別性能和過濾重復檢測而不是專門針對小目標檢測的,但是也和上面的PyramidBox思想很像的,都是利用上下文信息來提升檢測性能,可以歸類為Context一類。
總結
本文比較詳細地總結了一些在通用目標檢測和專門人臉檢測領域常見的小目標檢測的解決方案 ,后面有時間會再寫一些專門在人臉領域的困難點(比如ROP的側臉,RIP的360度人臉)及現在學術界的解決方案。