













聊聊召回和NLP在推薦系統(tǒng)中的作用
本文轉載自微信公眾號「虞大膽的嘰嘰喳喳」,作者虞大膽。轉載本文請聯系虞大膽的嘰嘰喳喳公眾號。
推薦系統(tǒng)是有技術壁壘的,涉及到各類算法和機器學習,工程實現就更難了。所以我們選擇了神策智能推薦服務,但感覺效果不太好,通過他們提供的幾個pdf,有了個大概的概念,發(fā)現召回是推薦系統(tǒng)中的重點。
推薦系統(tǒng)的作用:降低信息過載,那如果本身每天可推薦的內容不多呢;發(fā)掘長尾,這個是核心,能讓好文章有更多的曝光機會;提高轉化率,是提升dau?還是用戶粘性?
如何衡量推薦系統(tǒng)的好壞?可能人的感受更重要,但無法量化;如果利用CTR,一定程度上能反應好壞(點擊后不看估計也沒啥用),點擊后的反饋可能更精準,比如瀏覽時長,做出準確的評論等等。
推薦系統(tǒng)整個過程主要包括兩點,首先就是召回,也就是粗排,篩選出相對較小的候選集;其次就是排序,也就是精排,對物品進行打分。
推薦系統(tǒng)就是建立任何物品之間的關系,核心就是數據,包括三個部分:首先就是用戶行為,看文章、點收藏都是;其次就是物品信息;最后通過行為和物品信息,形成用戶畫像,這個畫像可能就是常規(guī)意義上的畫像、標簽化,但在機器學習中,它是隱式的,是向量化的,人無法直接理解。
接下去說說神策推薦系統(tǒng)提到的四種召回方法,見下圖:
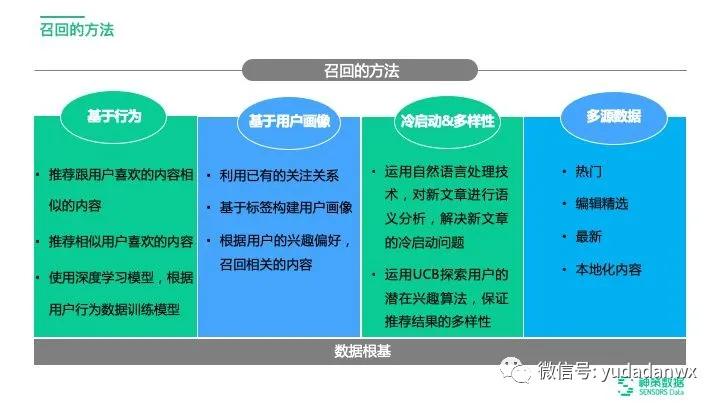
首先強調基于深度用戶行為分析的召回,由于是向量化,所以很難向人解釋它的優(yōu)劣,太黑盒了;主要分為兩個分支,協同過濾(基于矩陣分解)很常見了,缺點就是無法解決新內容冷啟動問題,以及時效性不足;
其次就是深度學習召回模型(HMF),借鑒了facebook論文,主要提到四點好處,更全面的行為表達,比如結合點擊、收藏、搜索等多種行為,能更全面地表示用戶行為偏好;能夠加入一些用戶畫像放到模型中;考慮用戶行為順序(感覺挺牛逼的);組合各類復雜特征。
其次就是自然語言技術,神策解釋是為了解決新內容的冷啟動問題,開始我有點疑惑,后來才明白,一篇新內容出來,立刻通過NLP技術,從中找到一些標簽化(比如關鍵詞)的內容,這樣結合用戶畫像,快速推薦給用戶。
但可惜的是神策推薦在我們業(yè)務場景中,居然沒有用到NLP技術。最近也看一些文章,純粹介于內容推薦也能弄出一個好的推薦系統(tǒng)。
比如通過分詞、主題分析、word2vec(詞向量隱式關系的分析),有了這些關鍵“元素”,可以用在相關性計算、召回、排序等過程。
如果沒有NLP技術,哪怕人為(編輯或用戶)打分類和標簽(更細分的分類)也行,雖然不智能,也不精準,但也能代表一些民意。
不過圖片和視頻進行語義分析就難了,要引入一些其他解決方案。
最后神策提到了NLP技術的三個好處:
利用自然語言技術,得到能表示每篇文章主題內容的語義向量
根據語義向量,推薦用戶喜歡的主題的文章
只需要分析文章內容,不需要用戶行為,能很好的推薦新文章,解決性能內容冷啟動問題
接著就是基于用戶畫像的召回,首先就是利用已有的關注(不是好友之間的關注)關系,你在APP上的每個行為都隱藏了用戶偏好,比如搜索某個關鍵詞(是不是表明想看某些相關的文章?所以文章NLP的分析多么重要),再比如點擊某個標簽(比如軍事標簽,是不是說明想看軍事相關的文章),或者收藏了某篇文章(是不是可以推薦類似的文章)。
其次就是基于標簽構建用戶畫像,用戶有很多常規(guī)意義上的畫像,可解釋的,也能表明他的一些興趣偏好,比如性別、經常發(fā)的文章、站內提供的可選擇性標簽,反過來,通過推薦系統(tǒng)不斷完善用戶畫像,從而進一步做精準推薦。
最后就是多源數據,比如入門數據,編輯推薦文章,KOL文章,官方文章等等,這些在召回的時候很有用,在神策中是以權重體現,是否說明這用于排序?而非召回?
為什么說神策智能推薦還不成熟,比如沒有來自于用戶的負反饋(我不喜歡),沒有使用NLP技術(對于我們這樣的內容APP,這個太重要了),不理解業(yè)務型態(tài)(無法針對性的調優(yōu),這可能是垂直sass解決方案的弊端,太機器化了),結合它們的控制臺,只能看到熱門召回和基于行為的召回,都是默認策略。既然是個性化推薦,它怎么證明做到了個性化推薦,也擔心最后的推薦效果退化到了編輯推薦。
最后好好理解這句話,數據和特征決定了機器學習的上限,而模型和算法只是逼近這個上限而已























