













作者 | 汪昊
審校 | 重樓
推薦系統自誕生以來廣受關注,尤其是互聯網領域,推薦系統已經成為了給企業下金蛋的白鵝。我們來算一筆賬,假設我們公司推薦產品的日 PV 是500 萬,推薦系統讓用戶點擊率提升了1%, 也就是一天增加了5 萬 PV。Google Ads 的CPC 均價是2 美元。這樣算來,推薦系統每天給該網站節省了10 萬美元的獲客費用,一年下來就是3650 萬美元。這真的是一筆非常龐大的數字,可見大型網站/ App 對推薦系統趨之若鶩是有原因的。

推薦系統自引入國內之后,許多工程師喜歡把推薦系統劃分為召回-排序等階段。其實所謂的召回,指的就是利用算法或規則先給執行推薦算法的數據篩選出一個子集合,然后再進入算法執行的下一個階段。作者在互聯網大廠的時候,曾經先用協同過濾做召回,然后用排序學習(Bayesian Personalized Ranking / Collaborative Less is More Filtering)做排序,取得了不錯的結果。
召回的策略千千萬,也許有人要問:有沒有什么召回策略是最優的?我們有沒有辦法通過最優化理論計算出最優的召回策略?答案是肯定的。Ratidar Technologies LLC 在國際學術會議 CAIBDA 2022 上宣讀了一篇題為Kernel-CF: Collaborative filtering done right with social network analysis and kernel smoothing 的論文,介紹了如何利用數據可視化算法和非參數統計方法計算推薦系統最優召回策略。我們下面詳細的介紹相關內容:
首先,我們介紹一下什么是 ForceAtlas-2 算法。ForceAtlas-2 發表于 PLoS 的2014 年的論文。論文題目是ForceAtlas2, a Continuous Graph Layout Algorithm for Handy Network Visualization Designed for the Gephi Software. 這篇論文講述了如何借用物理學中的概念,實現對于復雜網絡的可視化。相關算法已經集成在了常用的社交網絡分析軟件Gephi 中。
ForceAtlas-2 認為一個社交網絡中,點與點之間的相互作用有兩種:吸引力和排斥力。其中吸引力定義如下:
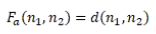
而排斥力定義如下:
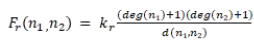
其中 d 是距離函數,而deg 是視圖中節點的度。通過觀察,我們得知,距離越近,吸引力越小;距離越遠,吸引力越大。節點的度越大,排斥力越大;節點之間的距離越遠,排斥力越小。ForceAtlas-2 通過在社交網絡中模擬這兩種力的相互作用,把復雜的社交網絡在二維空間簡單漂亮的展現了出來。
下面我們進入正題。我們來討論怎樣給協同過濾算法設計最優召回策略。我們這里拿基于用戶的協同過濾做例子。基于物品的協同過濾算法模型的分析與此類似。基于用戶的協同過濾算法的公式如下:
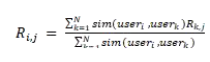
基于用戶的協同過濾的基本思想是根據與用戶相似的用戶的喜好列表給當前用戶推薦他所沒有見過的物品。這里面存在一個問題:我們該選擇哪些與用戶相似的用戶進行計算?是所有用戶嗎?還是有個最優的召回策略?這就是 Kernel-CF 算法將要討論的問題。Kernel-CF 算法的論文下載地址在這里:https://arxiv.org/ftp/arxiv/papers/2303/2303.04561.pdf 。下面我們針對這個算法展開介紹。
我們首先計算出所用用戶對之間的相似性,然后把相似矩陣轉換為距離矩陣,利用ForceAtlas-2 將距離矩陣映射到二維空間。我們發現,在新的社交網絡中,基于用戶的協同過濾其實就是非參數統計學中的 Nadaraya-Watson 核回歸問題,而我們要做的就是計算最優核半徑。而這是一個學者已經通過 plug-in 方法解決了的問題。在一維Nadaraya-Watson 核回歸中,最優核半徑的計算方法如下:
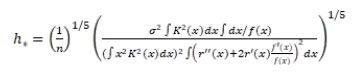
現在我們考慮二維的情況(我們有X 軸和 Y 軸兩個方向上的變量):
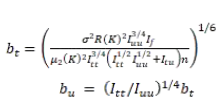
其中:
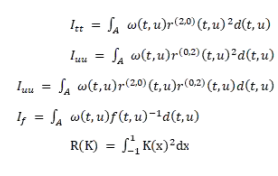
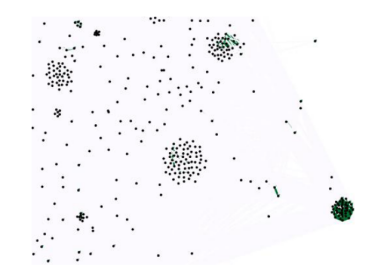
我們看到,我們利用 plug-in 方法,完美的解決了協同過濾中的最優召回問題。下圖是一張基于 ForceAtlas-2 降維之后的協同過濾輸入數據(LDOS-CoMoDa 數據集)的部分展示,可以看到最優召回策略可以節省大量的計算資源:
現在還剩下一個問題,那就是在上述利用 Plug-in 方法求解協同過濾算法最優召回的過程中存在著一些未知量,需要通過統計的方式進行近似,比如r 和 f。r 函數的定義如下:
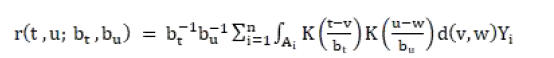
r 可以通過一般形式的最小二乘法進行近似。我們做了如下假定:
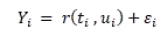
我們定義f 為數據造成的概率分布。我們通過概率密度估計來估計f :
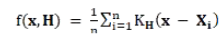
其中 H 通過如下方式進行估計:
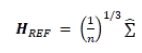
其中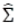 是協方差矩陣。綜合我們在上面討論的結果,我們得到如下算法流程(偽代碼):
是協方差矩陣。綜合我們在上面討論的結果,我們得到如下算法流程(偽代碼):

本文詳細介紹了如何利用信息可視化和非參數統計方法計算協同過濾中最優召回的問題。算法中雖然公式推導復雜,但是整體流程可實現性較強。一旦讀者熟悉了文章中算法的細節,就能很好的完成算法的實現工作。這個算法的名字叫做 Kernel-CF,一方面是因為利用了核回歸的知識,另外一方面是因為問題解決對象是協同過濾。
Kernel-CF 算法告訴我們在解決實際的機器學習問題中,應該集思廣益,博覽群書,充分利用其他領域的學科知識,就可以綜合起來解決推薦系統中的老大難問題。非參數統計是統計學專業高年級學生或者統計學研究生所學的內容。作為算法工程師,相關的知識平日里可能接觸不到,但是這不妨礙我們經常去圖書館借閱(中國國家圖書館有數百萬持卡用戶)或者購買書籍閱讀。扎實的數學功底,能夠給我們的算法工作插上騰飛的翅膀,翻越一座又一座的高山峻嶺。
作者簡介
汪昊,前 Funplus 人工智能實驗室負責人/創業公司CTO。曾在 ThoughtWorks、豆瓣、百度、新浪等公司擔任技術和技術高管職務。在互聯網公司和金融科技、游戲等公司任職 13 年,對于人工智能、計算機圖形學和區塊鏈等領域有著深刻的見解和豐富的經驗。在國際學術會議和期刊發表論文 42 篇,獲得IEEE SMI 2008 最佳論文獎、ICBDT 2020 / IEEE ICISCAE 2021 / AIBT 2023 / ICSIM 2024最佳論文報告獎。


















