推薦系統(tǒng)-協(xié)同過濾在Spark中的實現(xiàn)
作者 | vivo 互聯(lián)網(wǎng)服務(wù)器團隊-Tang Shutao
現(xiàn)如今推薦無處不在,例如抖音、淘寶、京東App均能見到推薦系統(tǒng)的身影,其背后涉及許多的技術(shù)。
本文以經(jīng)典的協(xié)同過濾為切入點,重點介紹了被工業(yè)界廣泛使用的矩陣分解算法,從理論與實踐兩個維度介紹了該算法的原理,通俗易懂,希望能夠給大家?guī)硪恍﹩l(fā)。
筆者認(rèn)為要徹底搞懂一篇論文,最好的方式就是動手復(fù)現(xiàn)它,復(fù)現(xiàn)的過程你會遇到各種各樣的疑惑、理論細(xì)節(jié)。
一、 背景
1.1 引言
在信息爆炸的二十一世紀(jì),人們很容易淹沒在知識的海洋中,在該場景下搜索引擎可以幫助我們迅速找到我們想要查找的內(nèi)容。
在電商場景,如今的社會物質(zhì)極大豐富,商品琳瑯滿目,種類繁多。消費者很容易挑花眼,即用戶將會面臨信息過載的問題。
為了解決該問題,推薦引擎應(yīng)運而生。例如我們打開淘寶App,JD app,B站視頻app,每一個場景下都有推薦的模塊。
那么此時有一個幼兒園小朋友突然問你,為什么JD給你推薦這本《程序員頸椎康復(fù)指南》?你可能會回答,因為我的職業(yè)是程序員。
接著小朋友又問,為什么《Spark大數(shù)據(jù)分析》這本書排在第6個推薦位,而《Scala編程》排在第2位?這時你可能無法回答這個問題。
為了回答該問題,我們設(shè)想下面的場景:
在JD的電商系統(tǒng)中,存在著用戶和商品兩種角色,并且我們假設(shè)用戶都會對自己購買的商品打一個0-5之間的分?jǐn)?shù),分?jǐn)?shù)越高代表越喜歡該商品。
基于此假設(shè),我們將上面的問題轉(zhuǎn)化為用戶對《程序員頸椎康復(fù)指南》,《Spark大數(shù)據(jù)分析》,《Scala編程》這三本書打分的話,用戶會打多少分(用戶之前未購買過這3本書)。因此物品在頁面的先后順序就等價于預(yù)測用戶對這些物品的評分,并且根據(jù)這些評分進行排序的問題。
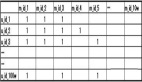
為了便于預(yù)測用戶對物品的評分問題,我們將所有三元組(User, Item, Rating),即用戶User給自己購買的商品Item的評分為Rating,組織為如下的矩陣形式:

其中,表格包含 m 個用戶和n個物品,將表格定義為評分矩陣 Rm×nRm×n ,其中的元素 ru,iru,i 表示第u個用戶對第i個物品的評分。
例如,在上面的表格中,用戶user-1購買了物品 item-1, item-3, item-4,并且分別給出了4,2,5的評分。最終,我們將原問題轉(zhuǎn)化為預(yù)測白色空格處的數(shù)值。
1.2 協(xié)同過濾
協(xié)同過濾,簡單來說是利用與用戶興趣相投、擁有共同經(jīng)驗之群體的喜好來推薦給用戶感興趣的物品。興趣相投使用數(shù)學(xué)語言來表達(dá)就是相似度 (人與人,物與物)。因此,根據(jù)相似度的對象,協(xié)同過濾可以分為基于用戶的協(xié)同過濾和基于物品的協(xié)同過濾。
以評分矩陣為例,以行方向觀測評分矩陣,每一行代表每個用戶的向量表示,例如用戶user-1的向量為 [4, 0, 2, 5, 0, 0]。以列方向觀測評分矩陣,每一列表示每個物品的向量表示,例如物品item-1的向量為[4, 3, 0, 0, 5]。
基于向量表示,相似度的計算有多種公式,例如余弦相似度,歐氏距離,皮爾森。這里我們以余弦相似度為例,它是我們中學(xué)學(xué)過的向量夾角 (中學(xué)只涉及2維和3維) 的高維推廣,余弦相似度公式很容易理解和使用。給定兩個向量 A={a1,?,an}A={a1,?,an} 和?B={b1,?,bn}B={b1,?,bn} ,其夾角定義如下:

例如,我們計算user-3和user-4的余弦相似度,二者對應(yīng)的向量分別為 [0, 2, 0, 3, 0, 4],[0, 3, 3, 5, 4, 0]

向量夾角的余弦值越接近1代表兩個物品方向越接近平行,也就是越相似,反之越接近-1代表兩個物品方向越接近反向,表示兩個物品相似度接近相反,接近0,表示向量接近垂直/正交,兩個物品幾乎無關(guān)聯(lián)。顯然,這和人的直覺完全一致。
例如,我們在視頻App中經(jīng)常能看到"相關(guān)推薦"模塊,其背后用到的原理之一就是相似度計算,下圖展示了一個具體的例子。
我們用《血族第一部》在向量庫 (存儲向量的數(shù)據(jù)庫,該系統(tǒng)能夠根據(jù)輸入向量,用相似度公式在庫中進行檢索,找出TopN的候選向量) 里面進行相似度檢索,找到了前7部高相似度的影片,值得注意的是第一部是自己本身,相似度為1.0,其他三部是《血族》的其他3部同系列作品。

1.2.1 基于用戶的協(xié)同過濾 (UserCF)
基于用戶的協(xié)同過濾分為兩步
- 找出用戶相似度TopN的若干用戶。
- 根據(jù)TopN用戶評分的物品,形成候選物品集合,利用加權(quán)平均預(yù)估用戶u對每個候選物品的評分。

例如,由用戶u的相似用戶{u1, u3, u5, u9}可得候選物品為

我們現(xiàn)在預(yù)測用戶u對物品i1的評分,由于物品在兩個用戶{u1, u5}的購買記錄里,因此用戶u對物品i1的預(yù)測評分為:

其中sim(u,u1)sim(u,u1) 表示用戶 u與用戶 u1u1的相似度。
在推薦時,根據(jù)用戶u對所有候選物品的預(yù)測分進行排序,取TopM的候選物品推薦給用戶u即可。
1.2.2 基于物品的協(xié)同過濾 (ItemCF)

基于物品的協(xié)同過濾分為兩步
- 在用戶u購買的物品集合中,選取與每一個物品TopN相似的物品。
- TopN相似物品形成候選物品集合,利用加權(quán)平均預(yù)估用戶u對每個候選物品的評分。
例如,我們預(yù)測用戶u對物品i3的評分,由于物品i3與物品{i6, i1, i9}均相似,因此用戶u對物品i3的預(yù)測評分為:

其中 sim(i6,i3)sim(i6,i3) 表示物品 i6i6 與物品 i3的相似度,其他符號同理。

1.2.3 UserCF與ItemCF的比較
我們對ItemCF和UserCF做如下總結(jié):
UserCF主要用于給用戶推薦那些與之有共同興趣愛好的用戶喜歡的物品,其推薦結(jié)果著重于反映和用戶興趣相似的小群體的熱點,更社會化一些,反映了用戶所在的小型興趣群體中物品的熱門程度。在實際應(yīng)用中,UserCF通常被應(yīng)用于用于新聞推薦。
ItemCF給用戶推薦那些和他之前喜歡的物品類似的物品,即ItemCF的推薦結(jié)果著重于維系用戶的歷史興趣,推薦更加個性化,反應(yīng)用戶自己的興趣。在實際應(yīng)用中,圖書、電影平臺使用ItemCF,比如豆瓣、亞馬遜、Netflix等。
除了基于用戶和基于物品的協(xié)同過濾,還有一類基于模型的協(xié)同過濾算法,如上圖所示。此外基于用戶和基于物品的協(xié)同過濾又可以歸類為基于鄰域 (K-Nearest Neighbor, KNN) 的算法,本質(zhì)都是在找"TopN鄰居",然后利用鄰居和相似度進行預(yù)測。
二、矩陣分解
經(jīng)典的協(xié)同過濾算法本身存在一些缺點,其中最明顯的就是稀疏性問題。我們知道評分矩陣是一個大型稀疏矩陣,導(dǎo)致在計算相似度時,兩個向量的點積等于0 (以余弦相似度為例)。為了更直觀的理解這一點,我們舉例如下:
rom sklearn.metrics.pairwise import cosine_similarity
a = [
[ 0, 0, 0, 3, 2, 0, 3.5, 0, 1 ],
[ 0, 1, 0, 0, 0, 0, 0, 0, 0 ],
[ 0, 0, 1, 0, 0, 0, 0, 0, 0 ],
[4.1, 3.8, 4.6, 3.8, 4.4, 3, 4, 0, 3.6]
]
cosine_similarity(a)
# array([[1. , 0. , 0. , 0.66209271],
# [0. , 1. , 0. , 0.34101639],
# [0. , 0. , 1. , 0.41280932],
# [0.66209271, 0.34101639, 0.41280932, 1. ]])

我們從評分矩陣中抽取item1 - item4的向量,并且利用余弦相似度計算它們之間的相似度。
通過相似度矩陣,我們可以看到物品item-1, item-2, item-3的之間的相似度均為0,而且與item-1, item-2, item-3最相似的物品都是item-4,因此在以ItemCF為基礎(chǔ)的推薦場景中item-4將會被推薦給用戶。
但是,物品item-4與物品item-1, item-2, item-3最相似的原因是item-4是一件熱門商品,購買的用戶多,而物品item-1, item-2, item-3的相似度均為0的原因僅僅是它們的特征向量非常稀疏,缺乏相似度計算的直接數(shù)據(jù)。
綜上,我們可以看到經(jīng)典的基于用戶/物品的協(xié)同過濾算法有天然的缺陷,無法處理稀疏場景。為了解決該問題,矩陣分解被提出。
2.1 顯示反饋
我們將用戶對物品的評分行為定義為顯示反饋。基于顯示反饋的矩陣分解是將評分矩陣Rm×n 用兩個矩陣 Xm×k和Yn×k的乘積近似表示,其數(shù)學(xué)表示如下:

其中, k?m/nk?m/n 表示隱性因子,以用戶側(cè)來理解,?k=2k=2 表示的就是用戶的年齡和性別兩個屬性。此外有個很好的比喻就是物理學(xué)的三棱鏡,白光在三棱鏡的作用下被分解為7種顏色的光,在矩陣分解算法中,分解的作用就類似于"三棱鏡",如下圖所示,因此,矩陣分解也被稱為隱語義模型。矩陣分解將系統(tǒng)的自由度從 O(mn) 降到了O((m+n)k,從而實現(xiàn)了降維的目的。

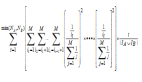
為了求解矩陣?Xm×kXm×k 和Yn×k,需要最小化平方誤差損失函數(shù),來盡可能地使得兩個矩陣的乘積逼近評分矩陣 Rm×nRm×n ,即

其中, λ(∑uxTuxu+∑iyTiyi)λ(∑uxuTxu+∑iyiTyi) 為懲罰項,λ為懲罰系數(shù)/正則化系數(shù),xu表示第u個用戶的k維特征向量,yiyi 表示第 i 個物品的k維特征向量。

全體用戶的特征向量構(gòu)成了用戶矩陣 ?Xm×kXm×k ,全體物品的特征向量構(gòu)成了物品矩陣 Yn×k。

我們訓(xùn)練模型的時候,就只需要訓(xùn)練用戶矩陣中的m×k個參數(shù)和物品矩陣中的n×k個參數(shù)。因此,協(xié)同過濾就成功轉(zhuǎn)化成了一個優(yōu)化問題。
2.2 預(yù)測評分
通過模型訓(xùn)練 (即求解模型系數(shù)的過程),我們得到用戶矩陣Xm×k 和物品矩陣 Yn×kYn×k,全部用戶對全部物品的評分預(yù)測可以通過 Xm×k(Yn×k)TXm×k(Yn×k)T 獲得。如下圖所示。

得到全部的評分預(yù)測后,我們就可以對每個物品進行擇優(yōu)推薦。需要注意的是,用戶矩陣和物品矩陣的乘積,得到的評分預(yù)估值,與用戶的實際評分不是全等關(guān)系,而是近似相等的關(guān)系。如上圖中兩個矩陣粉色部分,用戶實際評分和預(yù)估評分都是近似的,有一定的誤差。
2.3 理論推導(dǎo)
矩陣分解ALS的理論推導(dǎo)網(wǎng)上也有不少,但是很多推導(dǎo)不是那么嚴(yán)謹(jǐn),在操作向量導(dǎo)數(shù)時有的步驟甚至是錯誤的。有的博主對損失函數(shù)的求和項理解解出現(xiàn)錯誤,例如

但是評分矩陣是稀疏的,求和并不會貫穿整個用戶集和物品集。正確的寫法應(yīng)該是

其中,(u,i) is known(u,i) is known表示已知的評分項。
我們在本節(jié)給出詳細(xì)的、正確的推導(dǎo)過程,一是當(dāng)做數(shù)學(xué)小練習(xí),其次也是對算法有更深層的理解,便于閱讀Spark ALS的源碼。
將?(u,i) is known(u,i) is known 使用數(shù)學(xué)語言描述,矩陣分解的損失函數(shù)定義如下:

其中 K 為評分矩陣中已知的(u,i) 集合。例如下面的評分矩陣對應(yīng)的 K為

求解上述損失函數(shù)存在兩種典型的優(yōu)化方法,分別為
- 交替最小二乘 (Alternating Least Squares, ALS)
- 隨機梯度下降 (Stochastic Gradient Descent, SGD)
交替最小二乘,指的是固定其中一個變量,利用最小二乘求解另一個變量,以此交替進行,直至收斂或者到達(dá)最大迭代次數(shù),這也是“交替”一詞的由來。
隨機梯度下降,是優(yōu)化理論中最常用的一種方式,通過計算梯度,然后更新待求的變量。
在矩陣分解算法中,Spark最終選擇了ALS作為官方的唯一實現(xiàn),原因是ALS很容易實現(xiàn)并行化,任務(wù)之間沒有依賴。
下面我們動手推導(dǎo)一下整個計算過程,在機器學(xué)習(xí)理論中,微分的單位一般在向量維度,很少去對向量的分量為偏微分推導(dǎo)。
首先我們固定物品矩陣 Y,將物品矩陣 Y看成常量。不失一般性,我們定義用戶u 評分過的物品集合為 IuIu,利用損失函數(shù)對向量?xuxu 求偏導(dǎo),并且令導(dǎo)數(shù)等于0可得:

因為向量 xuxu與求和符號 ∑i∈Iu∑i∈Iu無關(guān),所有將其移出求和符號,因為 ?xTuyiyTixuTyiyiT 是矩陣相乘 (不滿足交換性),因此 xuxu 在左邊

等式兩邊取轉(zhuǎn)置,我們有

為了化簡 ∑i∈IuyiyTi∑i∈IuyiyiT 與 ∑i∈Iuru,iyi∑i∈Iuru,iyi,我們將 ?Iu 展開。
假設(shè)Iu={ic1,?,icN} , 其中N表示用戶u評分過的物品數(shù)量,iciici表示第 cici個物品對應(yīng)的索引/序號,借助于 Iu ,我們有

其中,
YIuYIu 為以?Iu={ic1,?icN}Iu={ic1,?icN} 為行號在物品矩陣 Y 中選取的N個行向量形成的子矩陣
Ru,Iu為以Iu={ic1,?icN} 為索引,在評分矩陣 R的第u 行的行向量中選取的N 個元素,形成的子行向量
因此,我們有

網(wǎng)上的博客,許多博主給出類似下面形式的結(jié)論不是很嚴(yán)謹(jǐn),主要是損失函數(shù)的理解不到位導(dǎo)致的。

同理,我們定義物品 i 被評分的用戶集合為 Ui={ud1,?udM}Ui={ud1,?udM}
根據(jù)對稱性可得

其中,
?XUiXUi 為以 ?Ui={ud1,?,udM}Ui={ud1,?,udM} 為行號在用戶矩陣X中選取的M個行向量形成的子矩陣
Ri,UiRi,Ui 為以 Ui={ud1,?,udM}Ui={ud1,?,udM} 為索引,在評分矩陣 R的第i列的列向量中選取的 M個元素,形成的子列向量
此外,IkIk 為單位矩陣?
如果讀者感覺上述的推導(dǎo)還是很抽象,我們也給一個具體實例來體會一下中間過程

注意到損失函數(shù)是一個標(biāo)量,這里我們只展開涉及到x1,1,x1,2x1,1,x1,2的項,如下所示

讓損失函數(shù)對 x1,1,x1,2x1,1,x1,2 分別求偏導(dǎo)數(shù)可以得到

寫成矩陣形式可得

利用我們上述的規(guī)則,很容易檢驗我們導(dǎo)出的結(jié)論。
總結(jié)來說,ALS的整個算法過程只有兩步,涉及2個循環(huán),如下圖所示:

算法使用RMSE(root-mean-square error)評估誤差。

當(dāng)RMSE值變化很小時或者到達(dá)最大迭代步驟時,滿足收斂條件,停止迭代。
“Talk is cheap. Show me the code.” 作為小練習(xí),我們給出上述偽代碼的Python實現(xiàn)。
import numpy as np
from scipy.linalg import solve as linear_solve
# 評分矩陣 5 x 6
R = np.array([[4, 0, 2, 5, 0, 0], [3, 2, 1, 0, 0, 3], [0, 2, 0, 3, 0, 4], [0, 3, 3,5, 4, 0], [5, 0, 3, 4, 0, 0]])
m = 5 # 用戶數(shù)
n = 6 # 物品數(shù)
k = 3 # 隱向量的維度
_lambda = 0.01 # 正則化系數(shù)
# 隨機初始化用戶矩陣, 物品矩陣
X = np.random.rand(m, k)
Y = np.random.rand(n, k)
# 每個用戶打分的物品集合
X_idx_dict = {1: [1, 3, 4], 2: [1, 2, 3, 6], 3: [2, 4, 6], 4: [2, 3, 4, 5], 5: [1, 3, 4]}
# 每個物品被打分的用戶集合
Y_idx_dict = {1: [1, 2, 5], 2: [2, 3, 4], 3: [1, 2, 4, 5], 4: [1, 3, 4, 5], 5: [4], 6: [2, 3]}
# 迭代10次
for iter in range(10):
for u in range(1, m+1):
Iu = np.array(X_idx_dict[u])
YIu = Y[Iu-1]
YIuT = YIu.T
RuIu = R[u-1, Iu-1]
xu = linear_solve(YIuT.dot(YIu) + _lambda * np.eye(k), YIuT.dot(RuIu))
X[u-1] = xu
for i in range(1, n+1):
Ui = np.array(Y_idx_dict[i])
XUi = X[Ui-1]
XUiT = XUi.T
RiUi = R.T[i-1, Ui-1]
yi = linear_solve(XUiT.dot(XUi) + _lambda * np.eye(k), XUiT.dot(RiUi))
Y[i-1] = yi
最終,我們打印用戶矩陣,物品矩陣,預(yù)測的評分矩陣如下,可以看到預(yù)測的評分矩陣非常逼近原始評分矩陣。
# X
array([[1.30678487, 2.03300876, 3.70447639],
[4.96150381, 1.03500693, 1.62261161],
[6.37691007, 2.4290095 , 1.03465981],
[0.41680155, 3.31805612, 3.24755801],
[1.26803845, 3.57580564, 2.08450113]])
# Y
array([[ 0.24891282, 1.07434519, 0.40258993],
[ 0.12832662, 0.17923216, 0.72376732],
[-0.00149517, 0.77412863, 0.12191856],
[ 0.12398438, 0.46163336, 1.05188691],
[ 0.07668894, 0.61050204, 0.59753081],
[ 0.53437855, 0.20862131, 0.08185176]])
# X.dot(Y.T) 預(yù)測評分
array([[4.00081359, 3.2132548 , 2.02350084, 4.9972158 , 3.55491072, 1.42566466],
[3.00018371, 1.99659282, 0.99163666, 2.79974661, 1.98192672, 3.00005934],
[4.61343295, 2.00253692, 1.99697545, 3.00029418, 2.59019481, 3.99911584],
[4.97591903, 2.99866546, 2.96391664, 4.99946603, 3.99816006, 1.18076534],
[4.99647978, 2.31231627, 3.02037696, 4.0005876 , 3.5258348 , 1.59422188]])
# 原始評分矩陣
array([[4, 0, 2, 5, 0, 0],
[3, 2, 1, 0, 0, 3],
[0, 2, 0, 3, 0, 4],
[0, 3, 3, 5, 4, 0],
[5, 0, 3, 4, 0, 0]])
三、Spark ALS應(yīng)用
Spark的內(nèi)部實現(xiàn)并不是我們上面所列的算法,但是核心原理是完全一樣的,Spark實現(xiàn)的是上述偽代碼的分布式版本,具體算法參考Large-scale Parallel Collaborative Filtering for the Netflix Prize。其次,查閱Spark的官方文檔,我們也注意到,Spark使用的懲罰函數(shù)與我們上文的有細(xì)微的差別。

其中 nu,ninu,ni分別表示用戶u打分的物品數(shù)量和物品 i 被打分的用戶數(shù)量。即

本小節(jié)通過兩個案例來了解Spark ALS的具體使用,以及在面對互聯(lián)網(wǎng)實際工程場景下的應(yīng)用。
3.1 Demo案例
以第一節(jié)給出的數(shù)據(jù)為例,將三元組(User, Item, Rating)組織為als-demo-data.csv,該demo數(shù)據(jù)集涉及5個用戶和6個物品。
userId,itemId,rating
1,1,4
1,3,2
1,4,5
2,1,3
2,2,2
2,3,1
2,6,3
3,2,2
3,4,3
3,6,4
4,2,3
4,3,3
4,4,5
4,5,4
5,1,5
5,3,3
5,4,4
使用Spark的ALS類使用非常簡單,只需將三元組(User, Item, Rating)數(shù)據(jù)輸入模型進行訓(xùn)練。
import org.apache.spark.sql.SparkSession
import org.apache.spark.ml.recommendation.ALS
val spark = SparkSession.builder().appName("als-demo").master("local[*]").getOrCreate()
val rating = spark.read
.options(Map("inferSchema" -> "true", "delimiter" -> ",", "header" -> "true"))
.csv("./data/als-demo-data.csv")
// 展示前5條評分記錄
rating.show(5)
val als = new ALS()
.setMaxIter(10) // 迭代次數(shù),用于最小二乘交替迭代的次數(shù)
.setRank(3) // 隱向量的維度
.setRegParam(0.01) // 懲罰系數(shù)
.setUserCol("userId") // user_id
.setItemCol("itemId") // item_id
.setRatingCol("rating") // 評分列
val model = als.fit(rating) // 訓(xùn)練模型
// 打印用戶向量和物品向量
model.userFactors.show(truncate = false)
model.itemFactors.show(truncate = false)
// 給所有用戶推薦2個物品
model.recommendForAllUsers(2).show()
上述代碼在控制臺輸出結(jié)果如下:
+------+------+------+
|userId|itemId|rating|
+------+------+------+
| 1| 1| 4|
| 1| 3| 2|
| 1| 4| 5|
| 2| 1| 3|
| 2| 2| 2|
+------+------+------+
only showing top 5 rows
+---+------------------------------------+
|id |features |
+---+------------------------------------+
|1 |[-0.17339179, 1.3144133, 0.04453602]|
|2 |[-0.3189066, 1.0291641, 0.12700711] |
|3 |[-0.6425665, 1.2283803, 0.26179287] |
|4 |[0.5160747, 0.81320006, -0.57953185]|
|5 |[0.645193, 0.26639006, 0.68648624] |
+---+------------------------------------+
+---+-----------------------------------+
|id |features |
+---+-----------------------------------+
|1 |[2.609607, 3.2668495, 3.554771] |
|2 |[0.85432494, 2.3137972, -1.1198239]|
|3 |[3.280517, 1.9563107, 0.51483333] |
|4 |[3.7446978, 4.259611, 0.6640027] |
|5 |[1.6036265, 2.5602736, -1.8897828] |
|6 |[-1.2651576, 2.4723763, 0.51556784]|
+---+-----------------------------------+
+------+--------------------------------+
|userId|recommendations |
+------+--------------------------------+
|1 |[[4, 4.9791617], [1, 3.9998217]]| // 對應(yīng)物品的序號和預(yù)測評分
|2 |[[4, 3.273963], [6, 3.0134287]] |
|3 |[[6, 3.9849386], [1, 3.2667015]]|
|4 |[[4, 5.011649], [5, 4.004795]] |
|5 |[[1, 4.994258], [4, 4.0065994]] |
+------+--------------------------------+
我們使用numpy來驗證Spark的結(jié)果,并且用Excel可視化評分矩陣。
import numpy as np
X = np.array([[-0.17339179, 1.3144133, 0.04453602],
[-0.3189066, 1.0291641, 0.12700711],
[-0.6425665, 1.2283803, 0.26179287],
[0.5160747, 0.81320006, -0.57953185],
[0.645193, 0.26639006, 0.68648624]])
Y = np.array([[2.609607, 3.2668495, 3.554771],
[0.85432494, 2.3137972, -1.1198239],
[3.280517, 1.9563107, 0.51483333],
[3.7446978, 4.259611, 0.6640027],
[1.6036265, 2.5602736, -1.8897828],
[-1.2651576, 2.4723763, 0.51556784]])
R_predict = X.dot(Y.T)
R_predict
輸出預(yù)測的評分矩陣如下:
array([[3.99982136, 2.84328038, 2.02551472, 4.97916153, 3.0030386, 3.49205357],
[2.98138452, 1.96660155, 1.03257371, 3.27396294, 1.88351875, 3.01342882],
[3.26670123, 2.0001004 , 0.42992289, 3.00003605, 1.61982132, 3.98493822],
[1.94325135, 2.97144913, 2.98550149, 5.011649 , 4.00479503, 1.05883274],
[4.99425778, 0.39883335, 2.99113433, 4.00659955, 0.41937014, 0.19627587]])
從Excel可視化的評分矩陣可以觀察到預(yù)測的評分矩陣非常逼近原始的評分矩陣,以user-3為例,Spark推薦的物品是item-6和item-1, [[6, 3.9849386], [1, 3.2667015]],這和Excel展示的預(yù)測評分矩陣完全一致。
從Spark函數(shù)recommendForAllUsers()給出的結(jié)果來看,Spark內(nèi)部并沒有去除用戶已經(jīng)購買的物品。

3.2 工程應(yīng)用
在互聯(lián)網(wǎng)場景,用戶數(shù) m(千萬~億級別) 和物品數(shù) n (10萬~100萬級別) 規(guī)模很大,App的埋點數(shù)據(jù)一般會保存在HDFS中,以互聯(lián)網(wǎng)的長視頻場景為例,用戶的埋點信息最終聚合為用戶行為表 t_user_behavior。
行為表包含用戶的imei,物品的content-id,但是沒有直接的用戶評分,實踐中我們的解決方案是利用用戶的其他行為進行加權(quán)得出用戶對物品的評分。即
rating = w1 * play_time (播放時長) + w2 * finsh_play_cnt (完成的播放次數(shù)) + w3 * praise_cnt (點贊次數(shù)) + w4 * share_cnt (分享次數(shù)) + 其他適合于你業(yè)務(wù)邏輯的指標(biāo)
其中, wi為每個指標(biāo)對應(yīng)的權(quán)重。

如下的代碼塊演示了工程實踐中對大規(guī)模用戶和商品場景進行推薦的流程。
import org.apache.spark.ml.feature.{IndexToString, StringIndexer}
// 從hive加載數(shù)據(jù),并利用權(quán)重公式計算用戶對物品的評分
val rating_df = spark.sql("select imei, content_id, 權(quán)重公式計算評分 as rating from t_user_behavior group by imei, content_id")
// 將imei和content_id轉(zhuǎn)換為序號,Spark ALS入?yún)⒁髐serId, itemId為整數(shù)
// 使用org.apache.spark.ml.feature.StringIndexer
val imeiIndexer = new StringIndexer().setInputCol("imei").setOutputCol("userId").fit(rating_df)
val contentIndexer = new StringIndexer().setInputCol("content_id").setOutputCol("itemId").fit(rating_df)
val ratings = contentIndexer.transform(imeiIndexer.transform(rating_df))
// 其他code,類似于上述demo
val model = als.fit(ratings)
// 給每個用戶推薦100個物品
val _userRecs = model.recommendForAllUsers(100)
// 將userId, itemId轉(zhuǎn)換為原來的imei和content_id
val imeiConverter = new IndexToString().setInputCol("userId").setOutputCol("imei").setLabels(imeiIndexer.labels)
val contentConverter = new IndexToString().setInputCol("itemId").setOutputCol("content_id").setLabels(contentIndexer.labels)
val userRecs = imeiConverter.transform(_userRecs)
// 離線保存供線上調(diào)用
userRecs.foreachPartition {
// contentConverter 將itemId轉(zhuǎn)換為content_id
// 保存redis邏輯
}值得注意的是,上述的工程場景還有一種解決方案,即隱式反饋。用戶給商品評分很單一,在實際的場景中,用戶未必會給物品打分,但是大量的用戶行為,同樣能夠間接反映用戶的喜好,比如用戶的購買記錄、搜索關(guān)鍵字,加入購物車,單曲循環(huán)播放同一首歌。我們將這些間接用戶行為稱之為隱式反饋,以區(qū)別于評分對應(yīng)的顯式反饋。胡一凡等人在論文Collaborative filtering for implicit feedback datasets中針對隱式反饋場景提出了ALS-WR模型 (ALS with Weighted-λ-Regularization),并且Spark官方也實現(xiàn)了該模型,我們將在以后的文章中介紹該模型。
四、總結(jié)
本文從推薦的場景出發(fā),引出了協(xié)同過濾這一經(jīng)典的推薦算法,并且由此講解了被Spark唯一實現(xiàn)和維護的矩陣分解算法,詳細(xì)推導(dǎo)了顯示反饋下矩陣分解的理論原理,并且給出了Python版本的單機實現(xiàn),能夠讓讀者更好的理解矩陣這一算法,最后我們以demo和工程實踐兩個實例講解了Spark ALS的使用,能夠讓沒有接觸過推薦算法的同學(xué)有個直觀的理解,用理論與實踐的形式明白矩陣分解這一推薦算法背后的原理。
參考文獻:
- 王喆, 深度學(xué)習(xí)推薦系統(tǒng)
- Hu, Yifan, Yehuda Koren, and Chris Volinsky. "Collaborative filtering for implicit feedback datasets." 2008 Eighth IEEE International Conference on Data Mining. IEEE, 2008.
- Zhou, Yunhong, et al. "Large-scale parallel collaborative filtering for the Netflix prize." International conference on algorithmic applications in management. Springer, Berlin, Heidelberg, 2008.