一個 Redis 的雪崩和穿透問題,小學妹畫了個圖,結果入職了
本文轉載自微信公眾號「Java極客技術」,作者鴨血粉絲。轉載本文請聯系Java極客技術公眾號。
阿粉的一個小學妹最近剛從某個小互聯網公司跳槽,然后最近面試的挺多的,一個不善言語的小姑娘,技術還是 OK 的,本來之前是做 UI 的,但是時間長了,感覺沒太大意思,所以就開始學了后端,然后從原有公司慢慢的轉為了后端開發人,也就是我們所說的 “程序猿”,最近面試給阿粉談了談她的面試經驗。阿粉比較印象深刻的一句話就是,我給你畫個圖,你看一下,這是對面試官說的,事情是什么樣子的呢?
你了解 Redis 穿透和雪崩么?
為什么這么說,因為面試官當你說到 Redis 的時候,面試官問的現在已經不是 "你說一下 Redis 的幾種數據結構" ,現在面試問的時候,很多都是對 Redis 的實際使用開始問了,比如說,
- Redis 都有哪些架構模式?單機版,主從復制,哨兵機制,集群(proxy 型),集群(直連型)
- 使用過 Redis 分布式鎖么,它是怎么實現的?
- 使用過 Redis 做異步隊列么,你是怎么用的?有什么缺點?
- 什么是緩存穿透?如何避免?什么是緩存雪崩?何如避免?
而阿粉的小學妹遇到的就是關于 Redis 的緩存穿透和雪崩問題了。這個問題學妹配合了一波自己的 UI 功底圖加上口頭的解釋,于是成功的拿到了這個 Offer,也可能是因為小學妹比較美麗并且技術還過的去。所以,就準備入職了。
我們來看看小學妹到底畫了什么圖,讓面試官問了一波之后就入職了。
緩存穿透
如圖:圖是阿粉找小學妹專門畫出來的,大家看一下
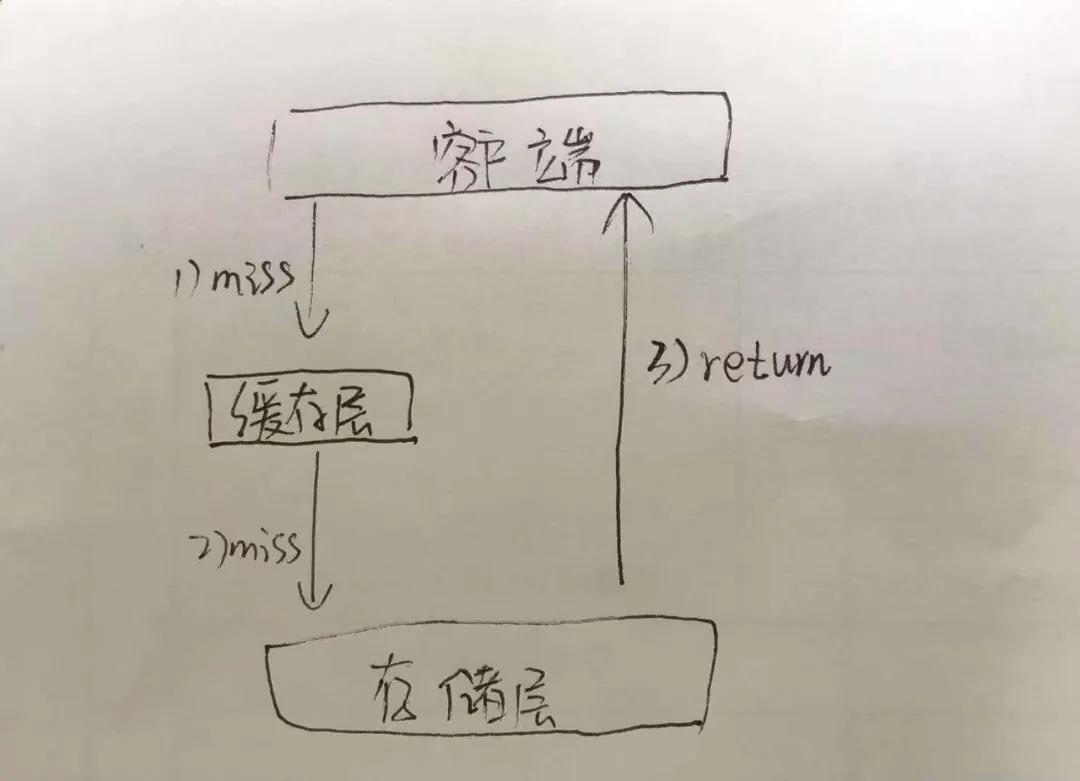
既然我們看完圖了,相信大家也都看到了什么是緩存穿透了,也就是說,在我們的緩存系統中,也就是 Redis 中,我們都是拿著我們的 Key 去 Redis 中去尋找 Value 中,如果說我們在 Redis 中找不到我們的數據之后,我們就會去數據庫中去尋找我們的數據,如果只是單一請求的話,也不能算是個太大的問題,只能稱之為擊穿而已,但是如果說要是請求并發量很大的話,就會對我們的數據庫造成很大的壓力,這其實就稱之為緩存穿透,而穿透出現的嚴重后果,就會是緩存的雪崩了,我們先說穿透,一會再說雪崩。
那么都會有什么情況會造成緩存被穿透呢?
- 自身代碼問題
- 一些惡意攻擊、爬蟲造成大量空的命中。
如果有個黑客對你們公司的項目和數據庫比較感興趣,他就可能會給你整出巨多的一些不存在的ID,然后就瘋狂的去調用你們的某項接口,這些本身不存在的 ID 去查詢緩存的數據的時候,那就是壓根沒有的,這時候就會有大量的請求去訪問數據庫,雖然可能數據能支撐一段時間,但是早晚會讓人家給你整的涼了。
那么應該怎么去解決緩存穿透的問題呢?
- 利用互斥鎖,緩存失效的時候,先去獲得鎖,得到鎖了,再去請求數據庫。沒得到鎖,則休眠一段時間重試。
- 采用異步更新策略,無論 Key 是否取到值,都直接返回。Value 值中維護一個緩存失效時間,緩存如果過期,異步起一個線程去讀數據庫,更新緩存。需要做緩存預熱(項目啟動前,先加載緩存)操作。
- 提供一個能迅速判斷請求是否有效的攔截機制,比如,利用布隆過濾器,內部維護一系列合法有效的 Key。迅速判斷出,請求所攜帶的 Key 是否合法有效。如果不合法,則直接返回。
- 布隆過濾器實際上是一種比較推薦的方式。
布隆過濾器的實現原理則是這樣的:
當一個變量被加入集合時,通過 K 個映射函數將這個變量映射成位圖中的 K 個點,把它們置為 1。查詢某個變量的時候我們只要看看這些點是不是都是 1 就可以大概率知道集合中有沒有它了,如果這些點有任何一個 0,則被查詢變量一定不在;如果都是 1,則被查詢變量很可能在。注意,這里是可能存在,不一定一定存在!這就是布隆過濾器的基本思想。
而當你說出布隆過濾器的時候,可能這才是面試官想要問你的內容,這時候你就得好好的和面試官開始聊聊什么事布隆過濾器了。
我們還是繼續用大眾都想看到的圖解來解釋布隆過濾器。
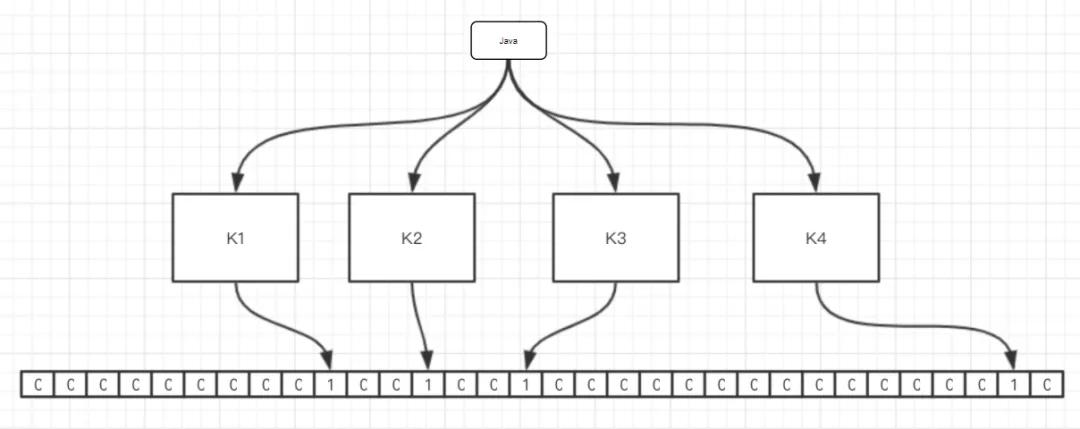
字符串 "Java" 在經過四個映射函數操作后在位圖上有四個點被設置成了 1。當我們需要判斷 “ziyou” 字符串是否存在的時候只要在一次對字符串進行映射函數的操作,得到四個 1 就說明 “Java” 是可能存在的。
注意語言,是可能存在,而不是一定存在,
那是因為映射函數本身就是散列函數,散列函數是會有碰撞的,意思也就是說會存在一個字符串可能是 “Java1” 經過相同的四個映射函數運算得到的四個點跟 “Java” 可能是一樣的,這種情況下我們就說出現了誤算。
另外還有可能這四個點位上的 1 是四個不同的變量經過運算后得到的,這也不能證明字符串 “Java” 是一定存在的。
而我們使用布隆過濾器其實就是提供一個能迅速判斷請求是否有效的攔截機制,判斷出請求所攜帶的 Key 是否合法有效。如果不合法,則直接返回。
而阿粉的小學妹給面試官解釋了一波這操作之后,看樣子,面試官對這個“程序猿”開始有點印象了,接下來就順著問了,那什么事緩存的雪崩呢?
緩存雪崩
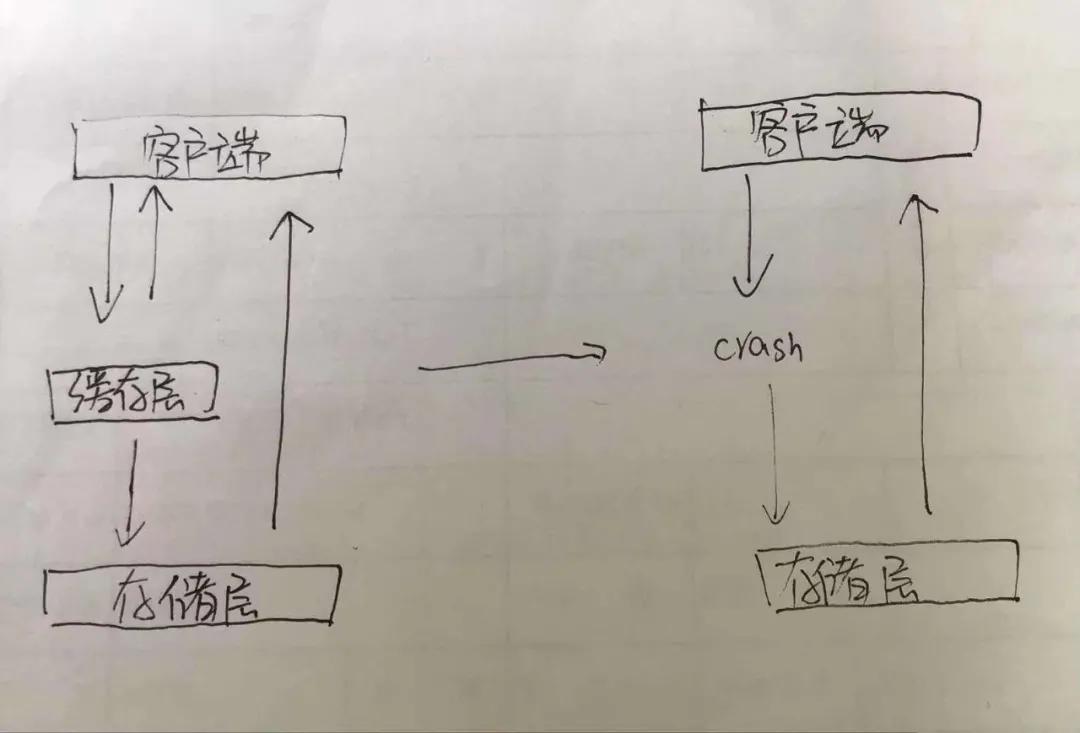
這時候也就是說,當我們有多個請求訪問緩存的時候,這時候,緩存中的數據是沒有的,也就是說緩存同一時間大面積的失效,這個時候又來了一波請求,結果請求都懟到數據庫上,從而導致數據庫連接異常
他和穿透實際上相似但是又有所不同,相似的地方是都是搞數據庫,不同的是緩存穿透是指并發查同一條數據,緩存雪崩是不同數據都過期了,很多數據都查不到從而查數據庫
而解決緩存雪崩的策略也是比較多的,而且都是比較實用的。比如:
- 給緩存的失效時間,加上一個隨機值,避免集體失效。
- 雙緩存。我們有兩個緩存,緩存 A 和緩存 B。緩存 A 的失效時間為 20 分鐘,緩存 B 不設失效時間
雙緩存策略比較有意思,當請求來臨的時候,我們先從 A 緩存中獲取,如果 A 緩存有數據,那么直接給他返回,如果 A 中沒有數據,那么就直接從 B 中獲取數據,直接返回,與此同時,我們啟動一個更新的線程,更新 A 緩存和 B 緩存,這就是雙緩存的策略。
上述的處理緩存雪崩的情況實際上都是從代碼上來進行實現,而我們換個思路考慮呢,也就是從架構的方向去考慮的話,解決方案就是以下的幾種了。
- 限流
- 降級
- 熔斷
那么怎么實現限流呢?
說到限流降級了,那就不能單純的去針對 Redis 出現的問題而進行處理了,而實際上是為了保證用戶保護服務的穩定性來進行的。
那么為什么要去限流呢?你要單純的說是為了保證系統的穩定性,那面試官估計得崩潰,這和沒說有啥區別,你得舉個簡單的例子才能正兒八經的忽悠住面試官,比如:
假設,我們當前的程序能夠處理10個請求,結果第二天,忽然有200多請求一起過來,整整翻了20倍,這時候,程序就涼了,但是如果第一天晚上的時候,領導給你說,明天你寫的那個程序大約會有200多個請求要處理,你這時候是不是得想辦法,比如說,能不能再寫出另外的一段程序來進行分擔請求,這時候其實就相當于需要我們去限流了。
限流算法之漏桶算法
同樣的,我們整個圖來理解一下這個算法到底是怎么實現的。
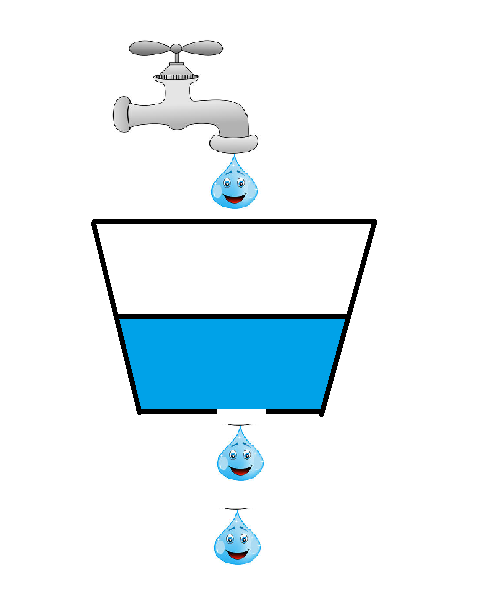
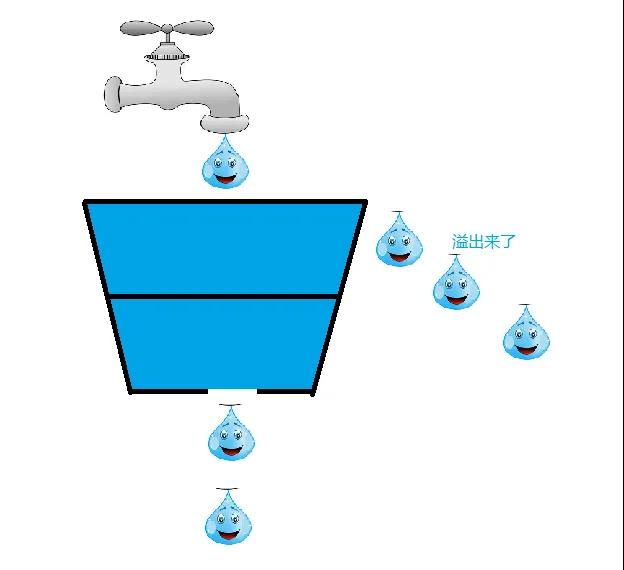
如果一桶有一個細眼,我們往里面裝水,可以看到水是一滴一滴勻速的下落的,如果桶滿了就拒絕水滴繼續滴入,沒滿的話就繼續裝水,實際上就是這樣的水滴實際上就相當于是請求,如果水桶沒滿的時候,還能繼續處理我們進來的請求,當水桶滿了的時候,就拒絕處理,讓他溢出。
前提是我們的這個桶是個固定的容器,不能隨著水的增多桶會變大,要不然那還用什么限流算法。
簡單的漏桶算法的實現:
- public class LeakyBucket {
- public long timeStamp = System.currentTimeMillis(); // 當前時間
- public long capacity; // 桶的容量
- public long rate; // 水漏出的速度
- public long water; // 當前水量(當前累積請求數)
- public boolean grant() {
- long now = System.currentTimeMillis();
- // 先執行漏水,計算剩余水量
- water = Math.max(0, water - (now - timeStamp) * rate);
- timeStamp = now;
- if ((water + 1) < capacity) {
- // 嘗試加水,并且水還未滿
- water += 1;
- return true;
- } else {
- // 水滿,拒絕加水
- return false;
- }
- }
- }
上面的代碼是來自悟空,不得不說,這個簡單的例子雖然簡單,但是把這個漏桶算法的簡單原理描述的還是差不多的,而在這里最需要注意的,就是桶的容量,還有就是水桶漏洞的出水的速度。
既然我們了解了漏桶算法是如何實現限流的,那么必然也會有他處理不來的情況,因為我們已經定義了水漏出的速度,而這時候如果應對突發的流量忽然涌進來,他處理起來效率就不夠高了,因為水桶滿了之后,請求都拒絕了,都不處理了。
其實我們所說的漏桶算法還可以看作是一個帶有常量服務時間的單服務器隊列,如果漏桶(包緩存)溢出,那么數據包會被丟棄。
而我們的漏桶算法主要是能夠強行限制數據的傳輸速率。
那么又有什么算法能夠不進行強制限制傳輸速率,并且實現限流呢?
令牌桶算法
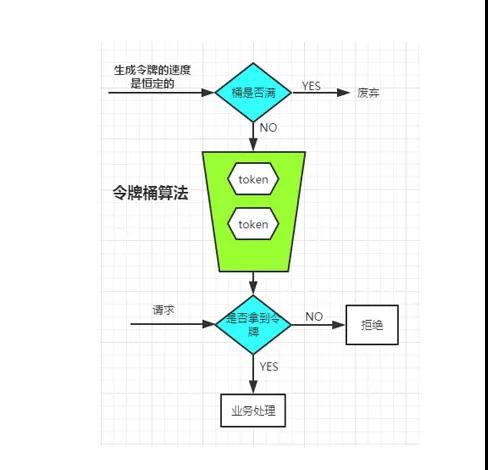
我們感謝百度,我從百度圖片中找了個一個比較給力的圖來描述令牌桶的算法。
令牌桶算法的基本過程是這個樣子的:
- 用戶配置的平均發送速率為r,則每隔1/r秒一個令牌被加入到桶中
- 假設桶最多可以存發b個令牌。如果令牌到達時令牌桶已經滿了,那么這個令牌會被丟棄
- 當一個n個字節的數據包到達時,就從令牌桶中刪除n個令牌,并且數據包被發送到網絡
- 如果令牌桶中少于n個令牌,那么不會刪除令牌,并且認為這個數據包在流量限制之外
乍一看,怎么感覺這個令牌桶和漏桶這么像,一個是水滴,一個是令牌,實際上不是。
令牌桶這種控制機制基于令牌桶中是否存在令牌來指示什么時候可以發送流量。令牌桶中的每一個令牌都代表一個字節。如果令牌桶中存在令牌,則允許發送流量;而如果令牌桶中不存在令牌,則不允許發送流量。
而且他是能夠應對突發限制的,雖然傳輸的速率受到了限制.所以它適合于具有突發特性的流量的一種算法。
而在 Google 開源工具包中的限流工具類RateLimiter ,這個類就是根據令牌桶算法來完成限流。大家有興趣的可以去看看呀。
漏桶算法和令牌桶算法的區別
漏桶算法與令牌桶算法實際上看起來有點相似,但是不能混淆哈,這就是阿粉在上面說的:
漏桶算法能夠強行限制數據的傳輸速率。
令牌桶算法能夠在限制數據的平均傳輸速率的同時還允許某種程度的突發傳輸