一文看懂什么是頁緩存(Page Cache)
本文轉載自微信公眾號「Linux內核那些事」,作者songsong001 。轉載本文請聯系Linux內核那些事公眾號。
我們知道文件一般存放在硬盤(機械硬盤或固態硬盤)中,CPU 并不能直接訪問硬盤中的數據,而是需要先將硬盤中的數據讀入到內存中,然后才能被 CPU 訪問。
由于讀寫硬盤的速度比讀寫內存要慢很多(DDR4 內存讀寫速度是機械硬盤500倍,是固態硬盤的200倍),所以為了避免每次讀寫文件時,都需要對硬盤進行讀寫操作,Linux 內核使用 頁緩存(Page Cache) 機制來對文件中的數據進行緩存。
本文使用的 Linux 內核版本為:Linux-2.6.23
什么是頁緩存
為了提升對文件的讀寫效率,Linux 內核會以頁大小(4KB)為單位,將文件劃分為多數據塊。當用戶對文件中的某個數據塊進行讀寫操作時,內核首先會申請一個內存頁(稱為 頁緩存)與文件中的數據塊進行綁定。如下圖所示:
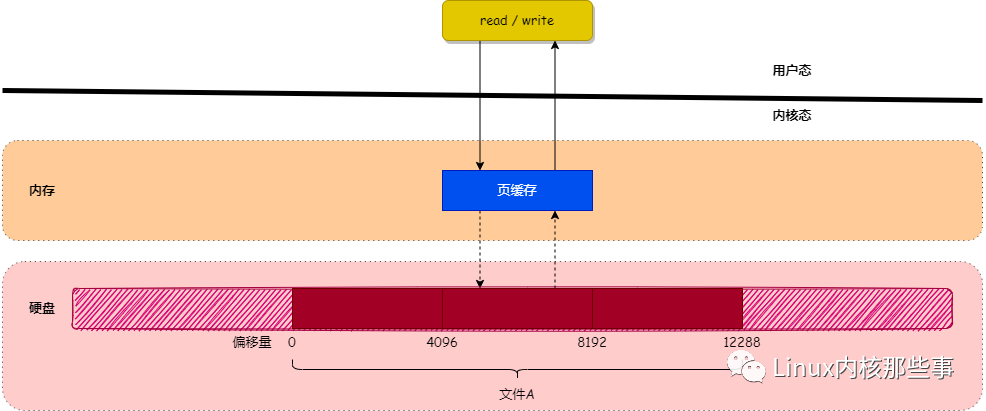
如上圖所示,當用戶對文件進行讀寫時,實際上是對文件的 頁緩存 進行讀寫。所以對文件進行讀寫操作時,會分以下兩種情況進行處理:
- 當從文件中讀取數據時,如果要讀取的數據所在的頁緩存已經存在,那么就直接把頁緩存的數據拷貝給用戶即可。否則,內核首先會申請一個空閑的內存頁(頁緩存),然后從文件中讀取數據到頁緩存,并且把頁緩存的數據拷貝給用戶。
- 當向文件中寫入數據時,如果要寫入的數據所在的頁緩存已經存在,那么直接把新數據寫入到頁緩存即可。否則,內核首先會申請一個空閑的內存頁(頁緩存),然后從文件中讀取數據到頁緩存,并且把新數據寫入到頁緩存中。對于被修改的頁緩存,內核會定時把這些頁緩存刷新到文件中。
頁緩存的實現
前面主要介紹了頁緩存的作用和原理,接下來我們將會分析 Linux 內核是怎么實現頁緩存機制的。
1. address_space
在 Linux 內核中,使用 file 對象來描述一個被打開的文件,其中有個名為 f_mapping 的字段,定義如下:
- struct file {
- ...
- struct address_space *f_mapping;
- };
從上面代碼可以看出,f_mapping 字段的類型為 address_space 結構,其定義如下:
- struct address_space {
- struct inode *host; /* owner: inode, block_device */
- struct radix_tree_root page_tree; /* radix tree of all pages */
- rwlock_t tree_lock; /* and rwlock protecting it */
- ...
- };
address_space 結構其中的一個作用就是用于存儲文件的 頁緩存,下面介紹一下各個字段的作用:
- host:指向當前 address_space 對象所屬的文件 inode 對象(每個文件都使用一個 inode 對象表示)。
- page_tree:用于存儲當前文件的 頁緩存。
- tree_lock:用于防止并發訪問 page_tree 導致的資源競爭問題。
從 address_space 對象的定義可以看出,文件的 頁緩存 使用了 radix樹 來存儲。
radix樹:又名基數樹,它使用鍵值(key-value)對的形式來保存數據,并且可以通過鍵快速查找到其對應的值。內核以文件讀寫操作中的數據 偏移量 作為鍵,以數據偏移量所在的 頁緩存 作為值,存儲在 address_space 結構的 page_tree 字段中。
下圖展示了上述各個結構之間的關系:
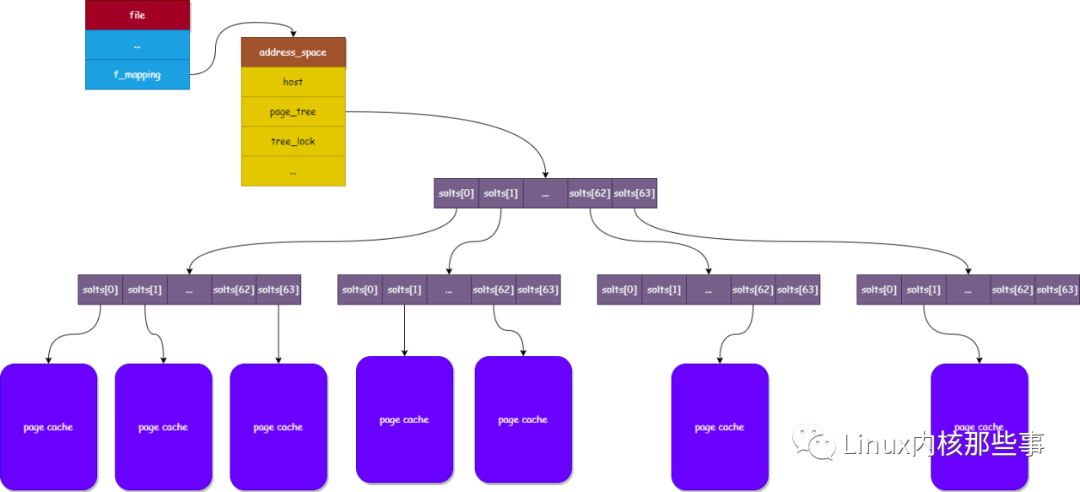
如果對 radix樹 不太了解,可以簡單將其看成可以通過文件偏移量快速找到其所在 頁緩存 的結構,有機會我會另外寫一篇關于 radix樹 的文章。
2. 讀文件操作
現在我們來分析一下讀取文件數據的過程,用戶可以通過調用 read 系統調用來讀取文件中的數據,其調用鏈如下:
- read()
- └→ sys_read()
- └→ vfs_read()
- └→ do_sync_read()
- └→ generic_file_aio_read()
- └→ do_generic_file_read()
- └→ do_generic_mapping_read()
從上面的調用鏈可以看出,read 系統調用最終會調用 do_generic_mapping_read 函數來讀取文件中的數據,其實現如下:
- void
- do_generic_mapping_read(struct address_space *mapping,
- struct file_ra_state *_ra,
- struct file *filp,
- loff_t *ppos,
- read_descriptor_t *desc,
- read_actor_t actor)
- {
- struct inode *inode = mapping->host;
- unsigned long index;
- struct page *cached_page;
- ...
- cached_page = NULL;
- index = *ppos >> PAGE_CACHE_SHIFT;
- ...
- for (;;) {
- struct page *page;
- ...
- find_page:
- // 1. 查找文件偏移量所在的頁緩存是否存在
- page = find_get_page(mapping, index);
- if (!page) {
- ...
- // 2. 如果頁緩存不存在, 那么跳到 no_cached_page 進行處理
- goto no_cached_page;
- }
- ...
- page_ok:
- ...
- // 3. 如果頁緩存存在, 那么把頁緩存的數據拷貝到用戶應用程序的內存中
- ret = actor(desc, page, offset, nr);
- ...
- if (ret == nr && desc->count)
- continue;
- goto out;
- ...
- readpage:
- // 4. 從文件讀取數據到頁緩存中
- error = mapping->a_ops->readpage(filp, page);
- ...
- goto page_ok;
- ...
- no_cached_page:
- if (!cached_page) {
- // 5. 申請一個內存頁作為頁緩存
- cached_page = page_cache_alloc_cold(mapping);
- ...
- }
- // 6. 把新申請的頁緩存添加到文件頁緩存中
- error = add_to_page_cache_lru(cached_page, mapping, index, GFP_KERNEL);
- ...
- page = cached_page;
- cached_page = NULL;
- goto readpage;
- }
- out:
- ...
- }
do_generic_mapping_read 函數的實現比較復雜,經過精簡后,上面代碼只留下最重要的邏輯,可以歸納為以下幾個步驟:
- 通過調用 find_get_page 函數查找要讀取的文件偏移量所對應的頁緩存是否存在,如果存在就把頁緩存中的數據拷貝到應用程序的內存中。
- 否則調用 page_cache_alloc_cold 函數申請一個空閑的內存頁作為新的頁緩存,并且通過調用 add_to_page_cache_lru 函數把新申請的頁緩存添加到文件頁緩存和 LRU 隊列中(后面會介紹)。
- 通過調用 readpage 接口從文件中讀取數據到頁緩存中,并且把頁緩存的數據拷貝到應用程序的內存中。
從上面代碼可以看出,當頁緩存不存在時會申請一塊空閑的內存頁作為頁緩存,并且通過調用 add_to_page_cache_lru 函數把其添加到文件的頁緩存和 LRU 隊列中。我們來看看 add_to_page_cache_lru 函數的實現:
- int add_to_page_cache_lru(struct page *page, struct address_space *mapping,
- pgoff_t offset, gfp_t gfp_mask)
- {
- // 1. 把頁緩存添加到文件頁緩存中
- int ret = add_to_page_cache(page, mapping, offset, gfp_mask);
- if (ret == 0)
- lru_cache_add(page); // 2. 把頁緩存添加到 LRU 隊列中
- return ret;
- }
add_to_page_cache_lru 函數主要完成兩個工作:
- 通過調用 add_to_page_cache 函數把頁緩存添加到文件頁緩存中,也就是添加到 address_space 結構的 page_tree 字段中。
- 通過調用 lru_cache_add 函數把頁緩存添加到 LRU 隊列中。LRU 隊列用于當系統內存不足時,對頁緩存進行清理時使用。
總結
本文主要介紹了 頁緩存 的作用和原理,并且介紹了在讀取文件數據時對頁緩存的處理過程。本文并沒有介紹寫文件操作對應的頁緩存處理和當系統內存不足時怎么釋放頁緩存,有興趣的話可以自行閱讀相關的代碼實現。