高可用的升級-RocketMQ知識體系7
一直以來,在多地多中心的消息發送場景下,如何保障數據的完整性和一致性是一個技術難點。在 RocketMQ 4.5 版本之前,RocketMQ 只有 Master/Slave 一種部署方式,一組 broker 中有一個 Master ,有零到多個
Slave,Slave 通過同步復制或異步復制的方式去同步 Master 數據。Master/Slave 部署模式,提供了一定的高可用性。
但這樣的部署模式,有一定缺陷。比如故障轉移方面,如果主節點掛了,還需要人為手動進行重啟或者切換,無法自動將一個從節點轉換為主節點。那么什么樣的多副本架構可以來解決這個問題呢?首先我們來看看多副本技術的演進。
多副本技術的演進
Master/Slave
多副本最早的是 Master/Slave 架構,即簡單地用 Slave 去同步 Master 的數據,RocketMQ 最早也是這種實現。分為同步模式(Sync Mode)和異步模式(Async Mode),區別就是 Master 是否等數據同步到 Slave 之后再返回 Client。這兩種方式目前在 RocketMQ 社區廣泛使用的版本中都有支持,也可以看我前面分享的文章。
基于 Zookeeper 服務
隨著分布式領域開啟了快速發展。在 Hadoop 生態中,誕生了一個基于 Paxos 算法選舉 Leader 的分布式協調服務 ZooKeeper。
由于 ZooKeeper 本身擁有高可用和高可靠的特性,隨之誕生了很多基于 ZooKeeper 的高可用高可靠的系統。
具體做法如下圖所示:
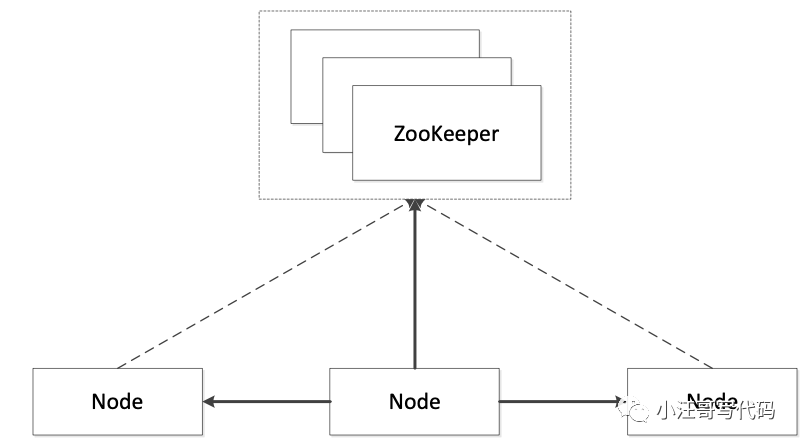
Based on Zookeeper/Etcd
如圖所示,假如系統里有 3 個節點,通過 ZooKeeper 提供的一些接口,可以從 3 個節點中自動的選出一個 Master 來。選出一個 Master 后,另外兩個沒成功的就自然變成 Slave。選完之后,后續過程與傳統實現方式中的復制一樣。故基于 ZooKeeper 的系統與基于 Master/Slave 系統最大的區別就是:選 Master 的過程由手動選舉變成依賴一個第三方的服務(比如 ZooKeeper 或 Etcd)的選舉。
但是基于 ZooKeeper 的服務也帶來一個比較嚴重的問題:依賴加重。因為運維 ZooKeeper 是一件很復雜的事情。
基于 Raft 服務方式
因為 ZooKeeper 的復雜性,又有了以下 Raft 的方式。Raft 可以認為是 Paxos 的簡化版。基于 Raft 的方式如下圖 4 所示,與上述兩種方式最大的區別是:leader 的選舉是由自己完成的。比如一個系統有 3 個節點,這 3 個節點的 leader 是利用 Raft 的算法通過協調選舉自己去完成的,選舉完成之后,Master 到 Slave 同步的過程仍然與傳統方式類似。最大的好處就是去除了依賴,即本身變得很簡單,可以自己完成自己的協調
實現高可靠和高可用的方法優劣對比
Master/Slave,Based on ZooKeeper/Etcd 和 Raft,這三種是目前分布式系統中,做到高可靠和高可用的基本的實現方法,各有優劣。
Master/Slave
優點:實現簡單
缺點:不能自動控制節點切換,一旦出了問題,需要人為介入。
基于 Zookeeper/Etcd
優點:可以自動切換節點
缺點:運維成本很高,因為 ZooKeeper 本身就很難運維。
Raft
優點:可以自己協調,并且去除依賴。
缺點:實現 Raft,在編碼上比較困難。
多副本架構首先需要解決自動故障轉移的問題,本質上來說是自動選主的問題。這個問題的解決方案基本可以分為兩種:
- 利用第三方協調服務集群完成選主,比如 zookeeper 或者 etcd。這種方案會引入了重量級外部組件,加重部署,運維和故障診斷成本,比如在維護 RocketMQ 集群還需要維護 zookeeper 集群,并且 zookeeper 集群故障會影響到 RocketMQ 集群。
- 利用 raft 協議來完成一個自動選主,raft 協議相比前者的優點是不需要引入外部組件,自動選主邏輯集成到各個節點的進程中,節點之間通過通信就可以完成選主。
目前很多中間件都使用了raft 協議或使用了變種的raft協議,如mongodb .還有新版的kafka,放棄了zookeeper,
將元數據存儲在 Kafka 本身,而不是存儲 ZooKeeper 這樣的外部系統中。新版kafka的Quorum 控制器使用新的 KRaft 協議來確保元數據在仲裁中被精確地復制。這個協議在很多方面與 ZooKeeper 的 ZAB 協議和 Raft 相似。
RocketMQ也選擇用 raft 協議來解決這個問題。
關于Raft
我們知道在分布式領域,始終都要面臨的一個挑戰就是:數據一致性.
Paxos。如今它是業界公認此類問題的最有效解。雖然Paxos在理論界得到了高度認可,但是卻給工程界帶來了難題。因為這個算法本身比較晦澀,并且抽象,缺少很多實現細節。這讓許多工程師大為頭疼
Raft是為解決Paxos難以理解和實現的問題而提出的。
Raft 算法的工作流程主要包含五個部分:
- 領導選舉(Leader election):在集群初始化或者舊領導異常情況下,選舉出一個新的領導。
- 日志復制(Log replication): 當有新的日志寫入時,領導能把它復制到集群中大多數節點上。
- 集群成員變更(Cluster Membership changes): 當集群有擴容或者縮容的需求,集群各節點能準確感知哪些節點新加入或者被去除。
- 日志壓縮(Log compaction): 當寫入的日志文件越來越大,重啟時節點回放(replay)日志的時間將無限延長,并且新節點加入集群時傳送日志文件也會無限拉大。需要定期對日志文件進行重整壓縮。
- 讀寫一致性(Read/write consistency): 客戶端作為集群的外部組件,當一個客戶端寫入新數據時,能保證后續所有客戶端都能讀到最新的值。
數據一致性的幾層語義:
- 數據的寫入順序要保持一致。否則可能出現很多不預期的情況,比如:舊值覆蓋新值。先刪后增變成先增后刪,數據消失了
- 對成功寫入的數據供認不諱。如果數據被集群表明寫入成功,那么集群各節點都應該認可并接受這個結果,而不會出現某些節點不知情的情況。
- 數據寫入成功保證持久化的。如果集群表明數據寫入成功,數據卻沒落盤。這時宕機了,那么數據就丟失了。
Raft在 保序性、共識性、持久性都能很好的支持這就能證明:
在假定領導永不宕機的前提下,Raft是能夠保證集群數據一致性的。
Leader在非正常運行情況下,推選出的新Leader至少擁有所有已提交的日志,從而保證數據一致性。
因為Raft規定:一切寫入操作必須由Leader管控,所以選主這段時間客戶端的寫入會被告知失敗或者進行不斷重試。這里其實一定程度上犧牲了集群的可用性來保證一致性。然而就像CAP定理告訴我們的,分布式系統不能既保證一致性C,又保證可用性A。而Raft集群選擇了 C和 P,也就一定程度失去了A。
所以,Raft算法能保證集群的數據一致性。
什么是 DLedger
Dledger 的定位
DLedger 就是一個基于 raft 協議的 commitlog 存儲庫,
Dledger 作為一個輕量級的 Java Library,它的作用就是將 Raft 有關于算法方面的內容全部抽象掉,開發人員只需要關心業務即可也是 RocketMQ 實現新的高可用多副本架構的關鍵。
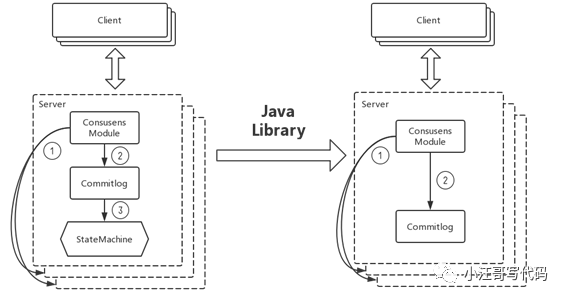
如上圖所示,Dledger 只做一件事情,就是 CommitLog。Etcd 雖然也實現了 Raft 協議,但它是自己封裝的一個服務,對外提供的接口全是跟它自己的業務相關的。在這種對 Raft 的抽象中,可以簡單理解為有一個 StateMachine 和 CommitLog。CommitLog 是具體的寫入日志、操作記錄,StateMachine 是根據這些操作記錄構建出來的系統的狀態。在這樣抽象之后,Etcd 對外提供的是自己的 StateMachine 的一些服務。Dledger 的定位就是把上一層的 StateMachine 給去除,只留下 CommitLog。這樣的話,系統就只需要實現一件事:就是把操作日志變得高可用和高可靠。
Dledger 的架構
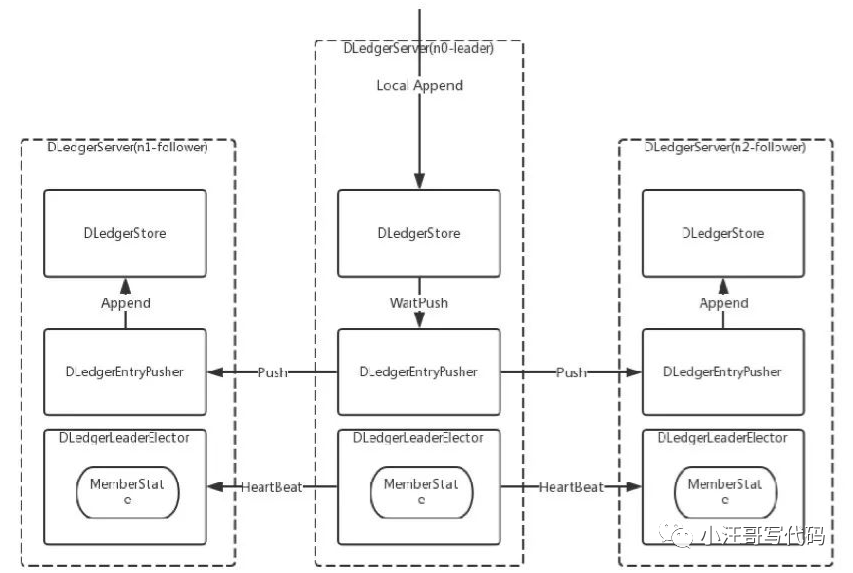
從前面介紹的多副本技術的演進可以知道,我們要做的主要有兩件事:選舉和復制,對應到上面的架構圖中,也就是兩個核心類:DLedgerLeaderElector 和 DLedgerStore,選舉和文件存儲。選出 leader 后,再由 leader 去接收數據的寫入,同時同步到其他的 follower,這樣就完成了整個 Raft 的寫入過程。
DLedger 的優化
Raft 協議復制過程可以分為四步,先是發送消息給 leader,leader 除了本地存儲之外,會把消息復制給 follower,然后等待follower 確認,如果得到多數節點確認,該消息就可以被提交,并向客戶端返回發送成功的確認。
DLedger對于復制過程有以下優化:
- 1、對于復制過程,DLedger 采用一個異步線程模型提高吞吐量和性能。
- 2、DLedger 中,leader 向所有 follower 發送日志也是完全相互獨立和并發的,leader 為每個 follower 分配一個線程去復制日志 這是一個獨立并發的復制過程。
- 3、在獨立并發的復制過程內,DLedger設計并實現日志并行復制的方案,不再需要等待前一個日志復制完成再復制下一個日志,只需在 follower 中維護一個按照日志索引排序請求列表, follower 線程按照索引順序串行處理這些復制請求。而對于并行復制后可能出現數據缺失問題,可以通過少量數據重傳解決。
通過以上3點,優化這一復制過程。
在可靠性方面DLedger也對網絡分區做了優化,而且也對DLedger 做了可靠性測試:
DLedger對網絡分區的優化
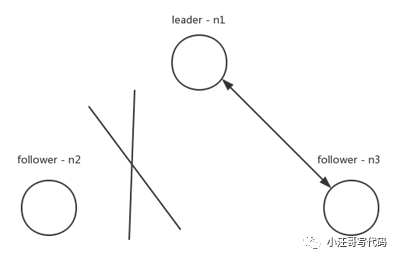
如果出現上圖的網絡分區,n2與集群中的其他節點發生了網絡隔離,按照 raft 論文實現,n2會一直請求投票,但得不到多數的投票,term 一直增大。一旦網絡恢復后,n2就會去打斷正在正常復制的n1和n3,進行重新選舉。為了解決這種情況,DLedger 的實現改進了 raft 協議,請求投票過程分成了多個階段,其中有兩個重要階段:WAIT_TO_REVOTE和WAIT_TO_VOTE_NEXT。WAIT_TO_REVOTE是初始狀態,這個狀態請求投票時不會增加 term,WAIT_TO_VOTE_NEXT則會在下一輪請求投票開始前增加 term。對于圖中n2情況,當有效的投票數量沒有達到多數量時。可以將節點狀態設置WAIT_TO_REVOTE,term 就不會增加。通過這個方法,提高了Dledger對網絡分區的容忍性。
DLedger 可靠性測試
官方不僅測試對稱網絡分區故障,還測試了其他故障下 Dledger 表現情況,包括隨機殺死節點,隨機暫停一些節點的進程模擬慢節點的狀況,以及 bridge、partition-majorities-ring 等復雜的非對稱網絡分區。在這些故障下,DLedger 都保證了一致性,驗證了 DLedger 有很好可靠性。
Dledger 的應用
在 RocketMQ 上的應用
RocketMQ 4.5 版本發布后,可以采用 RocketMQ on DLedger 方式進行部署。DLedger commitlog 代替了原來的 commitlog,使得 commitlog 擁有了選舉復制能力,然后通過角色透傳的方式,raft 角色透傳給外部 broker 角色,leader 對應原來的 master,follower 和 candidate 對應原來的 slave。
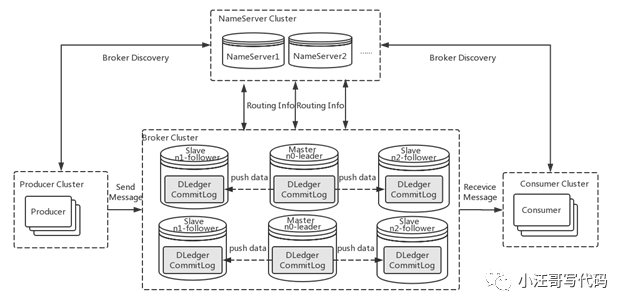
因此 RocketMQ 的 broker 擁有了自動故障轉移的能力。在一組 broker 中, Master 掛了以后,依靠 DLedger 自動選主能力,會重新選出 leader,然后通過角色透傳變成新的 Master。
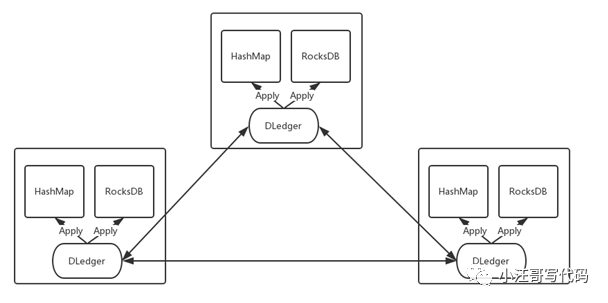
Dledger構建高可用的嵌入式 KV 存儲
DLedger 還可以構建高可用的嵌入式 KV 存儲。
我們沒有一個嵌入式且高可用的解決方案。RocksDB 可以直接用,但是它本身不支持高可用。(Rocks DB 是Facebook開源的單機版數據庫)
有了 DLedger 之后,我們把對一些數據的操作記錄到 DLedger 中,然后根據數據量或者實際需求,恢復到hashmap 或者 rocksdb 中,從而構建一致的、高可用的 KV 存儲系統,應用到元信息管理等場景。
參考:
https://developer.aliyun.com/article/713017
https://blog.csdn.net/csdn_lhs/article/details/108029978