













深入探究Node | (5)“Buffer與亂碼的故事” 有十問
- 1. 為什么要有Buffer對象?
- 2. 可以談談你所認識的Buffer對象嗎?
- 模塊結構
- Buffer對象結構
- 3. 哇塞,原來Buffer對象這么有意思,還可以當成Array來使用,我突發奇想,要是給元素賦值的值是小數而不是整數會怎么樣呢?
- 4. 我看Buffer對象很像字符串,它兩可以互轉嗎?
- 字符串轉Buffer
- Buffer轉字符串
- 5. Buffer應該是常見于輸入輸入流中,你可以說說怎么使用嗎?
- 6. 我有時候這樣讀取數據,然后打印出來,有時候會出現亂碼,是什么原因呢?
- 7.為什么 “月”、“是”、“望”、“低”4個字沒有被正常輸出,取而代之的是3個亂碼?
- 8. so噶!那樣的話,那我限制Buffer對象的長度為12,就不會有問題了吧!但是這樣每次都要數,很麻煩,有沒有簡單的方法呢?
- 9. 哇塞,真是令人興奮,Node是如何實現這個輸出結果的呢?
- 10. 可是設置decoder后,即使被轉碼,那也無法改變寬字節字符串被截斷的問題啊?
1. 為什么要有Buffer對象?
在Node中,應用需要處理網絡協議、操作數據庫、處理圖片、接收上傳文件等,在網絡流和文件的操作中,還要處理大量二進制數據,JavaScript自有的字符串遠遠不能滿足這些需求,于是Buffer對象應運而生。
Buffer在文件I/O和網絡I/O中運用廣泛,尤其在網絡傳輸中,它的性能舉足輕重。在應用中,我們通常會操作字符串,但一旦在網絡中傳輸,都需要轉換為Buffer,以進行二進制數據傳輸。在Web應用中,字符串轉換到Buffer是時時刻刻發生的,提高字符串到Buffer的轉換效率,可以很大程度地提高網絡吞吐率。
2. 可以談談你所認識的Buffer對象嗎?
嗯嗯,好的。
Buffer是一個像Array的對象,但它主要用于操作字節。所以我將會從模塊結構和對象結構的層面上來認識它。
模塊結構
Buffer是一個典型的JavaScript與C++結合的模塊,它將性能相關部分用C++實現,將非性能相關的部分用JavaScript實現,如圖所示。
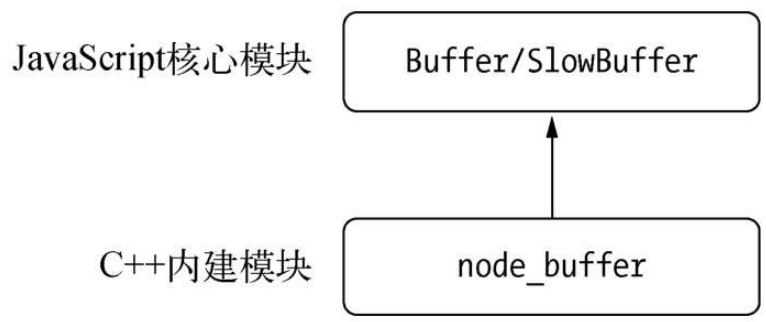
在【深入探究Node】(4)“內存控制” 有十五問我們提到Buffer所占用的內存不是通過V8分配的,屬于堆外內存。由于V8垃圾回收性能的影響,將常用的操作對象用更高效和專有的內存分配回收策略來管理是個不錯的思路。由于Buffer太過常見,Node在進程啟動時就已經加載了它,并將其放在全局對象(global)上。所以在使用Buffer時,無須通過require()即可直接使用。
Buffer對象結構
Buffer對象類似于數組,它的元素為16進制的兩位數,即0到255的數值。示例代碼如下所示:

由上面的示例可見,不同編碼的字符串占用的元素個數各不相同,上面代碼中的中文字在UTF-8編碼下占用3個元素,字母和半角標點符號占用1個元素。
Buffer受Array類型的影響很大,可以訪問length屬性得到長度,也可以通過下標訪問元素,在構造對象時也十分相似,代碼如下:
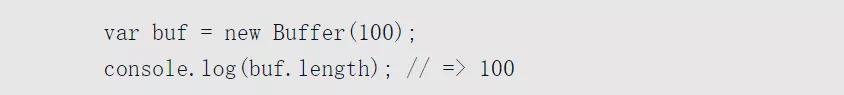
上述代碼分配了一個長100字節的Buffer對象。可以通過下標訪問剛初始化的Buffer的元素,代碼如下:

這里會得到一個比較奇怪的結果,它的元素值是一個0到255的隨機值。同樣,我們也可以通過下標對它進行賦值:
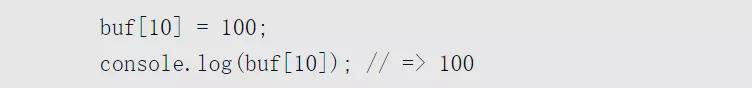
3. 哇塞,原來Buffer對象這么有意思,還可以當成Array來使用,我突發奇想,要是給元素賦值的值是小數而不是整數會怎么樣呢?

給元素的賦值如果小于0,就將該值逐次加256,直到得到一個0到255之間的整數。如果得到的數值大于255,就逐次減256,直到得到0~255區間內的數值。如果是小數,舍棄小數部分,只保留整數部分。
4. 我看Buffer對象很像字符串,它兩可以互轉嗎?
可以的。
字符串轉Buffer
字符串轉Buffer對象主要是通過構造函數完成的:

通過構造函數轉換的Buffer對象,存儲的只能是一種編碼類型。encoding參數不傳遞時,默認按UTF-8編碼進行轉碼和存儲。
Buffer轉字符串
實現Buffer向字符串的轉換也十分簡單,Buffer對象的toString()可以將Buffer對象轉換為字符串,代碼如下:

比較精巧的是,可以設置encoding(默認為UTF-8)、start、end這3個參數實現整體或局部的轉換。如果Buffer對象由多種編碼寫入,就需要在局部指定不同的編碼,才能轉換回正常的編碼。
5. Buffer應該是常見于輸入輸入流中,你可以說說怎么使用嗎?
Buffer在使用場景中,通常是以一段一段的方式傳輸。以下是常見的從輸入流中讀取內容的示例代碼:圖片上面這段代碼常見于國外,用于流讀取的示范,data事件中獲取的chunk對象即是Buffer對象。對于初學者而言,容易將Buffer當做字符串來理解,所以在接受上面的示例時不會覺得有任何異常。
6. 我有時候這樣讀取數據,然后打印出來,有時候會出現亂碼,是什么原因呢?
一旦輸入流中有寬字節編碼時,問題就會暴露出來。如果你在通過Node開發的網站上看到[插圖]亂碼符號,那么該問題的起源多半來自于這里。
用多個字節來代表的字符稱之為寬字符,而Unicode只是寬字符編碼的一種實現,寬字符并不一定是Unicode。
這里潛藏的問題在于如下這句代碼:圖片這句代碼里隱藏了toString()操作,它等價于如下的代碼:

值得注意的是,外國人的語境通常是指英文環境,在他們的場景下,這個toString()不會造成任何問題。但對于寬字節的中文,卻會形成問題。為了重現這個問題,下面我們模擬近似的場景,將文件可讀流的每次讀取的Buffer長度限制為11,代碼如下:
圖片搭配該代碼的測試數據為李白的《靜夜思》。執行該程序,將會得到以下輸出:
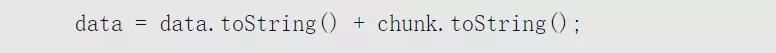
7.為什么 “月”、“是”、“望”、“低”4個字沒有被正常輸出,取而代之的是3個亂碼?
產生這個輸出結果的原因在于文件可讀流在讀取時會逐個讀取Buffer。
這首詩的原始Buffer應存儲為:

由于我們限定了Buffer對象的長度為11,因此只讀流需要讀取7次才能完成完整的讀取,結果是以下幾個Buffer對象依次輸出:

上文提到的buf.toString()方法默認以UTF-8為編碼,中文字在UTF-8下占3個字節。所以第一個Buffer對象在輸出時,只能顯示3個字符,Buffer中剩下的2個字節(e6 9c)將會以亂碼的形式顯示。第二個Buffer對象的第一個字節也不能形成文字,只能顯示亂碼。于是形成一些文字無法正常顯示的問題。
在這個示例中我們構造了11這個限制,但是對于任意長度的Buffer而言,寬字節字符串都有可能存在被截斷的情況,只不過Buffer的長度越大出現的概率越低而已,但該問題依然不可忽視。
8. so噶!那樣的話,那我限制Buffer對象的長度為12,就不會有問題了吧!但是這樣每次都要數,很麻煩,有沒有簡單的方法呢?
有的,我們別忘了可讀流還有一個設置編碼的方法setEncoding(),示例如下:
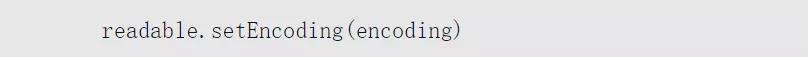
該方法的作用是讓data事件中傳遞的不再是一個Buffer對象,而是編碼后的字符串。為此,我們繼續改進前面詩歌的程序,添加setEncoding()的步驟如下:

重新執行程序,得到輸出:
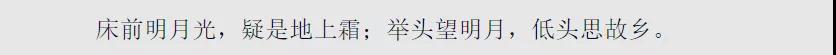
9. 哇塞,真是令人興奮,Node是如何實現這個輸出結果的呢?
事實上,在調用setEncoding()時,可讀流對象在內部設置了一個decoder對象。每次data事件都通過該decoder對象進行Buffer到字符串的解碼,然后傳遞給調用者。是故設置編碼后,data不再收到原始的Buffer對象。
10. 可是設置decoder后,即使被轉碼,那也無法改變寬字節字符串被截斷的問題啊?
decoder對象來自于string_decoder模塊StringDecoder的實例對象。
可以看看 下面的代碼:

我將前文提到的前兩個Buffer對象寫入decoder中。奇怪的地方在于“月”的轉碼并沒有如平常一樣在兩個部分分開輸出。StringDecoder在得到編碼后,知道寬字節字符串在UTF-8編碼下是以3個字節的方式存儲的,所以第一次write()時,只輸出前9個字節轉碼形成的字符,“月”字的前兩個字節被保留在StringDecoder實例內部。第二次write()時,會將這2個剩余字節和后續11個字節組合在一起,再次用3的整數倍字節進行轉碼。于是亂碼問題通過這種中間形式被解決了。














