Node Buffer/Stream內存策略分析
在Node 中,Buffer 是一個廣泛用到的類,本文將從以下層次來分析其內存策略:
◆ User 層面,即Node lib/*.js 或用戶自己的Js 文件調用 new Buffer
◆ Socekt read/write
◆ File read/write
51CTO推薦專題:Node.js專區
User Buffer
在 lib/buffer.js 模塊中,有個模塊私有變量 pool, 它指向當前的一個8K 的slab :
- Buffer.poolSize = 8 * 1024;
- var pool;
- function allocPool() {
- pool = new SlowBuffer(Buffer.poolSize);
- pool.used = 0;
- }
SlowBuffer 為 src/node_buffer.cc 導出,當用戶調用new Buffer時 ,如果你要申請的空間大于8K,Node 會直接調用SlowBuffer ,如果小于8K ,新的Buffer 會建立在當前slab 之上:
◆ 新創建的Buffer的 parent成員變量會指向這個slab ,
◆ offset 變量指向在這個slab 中的偏移:
- if (!pool || pool.length - pool.used < this.length) allocPool();
- this.parent = pool;
- this.offset = pool.used;
- pool.used += this.length;
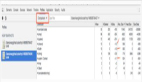
比如當你需要2K 的空間時 : new Buffer(2*1024),它會檢查這個slab 的剩余空間,如果有剩余,則分配給你這段可用空間,并把當前 slab 的已用空間 used += 2*1024
比如當我們連續兩次調用new Buffer(2*1024)時 :

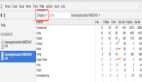
當我們再次申請一個5K 的空間時,當前的pool 僅有4K 可用,所以這時node會再次申請一個8K 的slab ,并把當前的pool 指向它 ,注意此時原先的slab 會有4K空間被浪費:

此時原先的slab 被兩個2K 的 Buffer 所引用,所以當這兩個Buffer 引用都變為null 后,V8 認為可以銷毀這個slab。
注意,假如我們的某一個slab被一個1Byte 的Buffer 所引用 ,那么,即使其他所有的引用都已經變為null ,這塊8K 的slab 也不會被回收:

Socket 讀寫
首先讓我們看stream read 的情況:
在stream_wrap 當中,此時的策略與用戶層的 new Buffer 相似,只是slab 的 size 變為 1MB ,此時我們需要考慮socket “讀操作” 緩沖區大小問題,設想以下,假如我們數據長度為30K,而我們的緩沖區大小僅為2K,這意味著我們至少調用15次socket read操作,要觸發15次 on(“data”) 事件,每次都需要把這個事件及數據從libuv 層次傳遞到用戶js 層次,這是極其低效的,所以我們需要設置一個較大的緩沖區,在libuv 的 unix/stream.c ,當綁定socket 的 watcher read 事件被觸發時,會調用uv__read 函數,其固化了buffer 大小為64*1024 :
- ...
- buf = stream->alloc_cb((uv_handle_t*)stream, 64 * 1024);
- ...
alloc_cb 定義在 stream_wrap.cc 中
uv_buf_t StreamWrap::OnAlloc(uv_handle_t* handle, size_t suggested_size)

但事實上我們知道,我們socket read 一般很少會有64K 大小,比如假如nread 僅為 2k,此時我們為了避免浪費,可以重設slab_used :
- if (handle_that_last_alloced == handle) {
- slab_used -= (buf.len - nread);
- }

敬請注意,我們之所以能夠這么做,是因為當檢測到socket 上read事件時才分配緩沖區, alloc_cb →socket read → read callback 這一過程是順序進行的,沒有外來的干擾!(我不明白為何node 還要加上一次判斷 if (handle_that_last_alloced == handle) ,深究的可以告訴我)
我們看到,在socket read 的情況下,緩沖區的管理在stream_wrap 中控制,uv steram.c 執行讀操作,返回的回調函數也是在stream_wrap 中定義,然后把讀取到的Buffe 層層傳遞給user 的js當中,即我們的on(“data”) 事件,這個過程中沒有額外的內存拷貝,還是相當高效的, 不過有個問題:假使你持久引用了一個有stream.read 上浮的Buffer ,你將導致其所引用的那個1M 的slab 得不到釋放!
我們在來看 Socket.prototype.write ,當你傳入一個 string 時,node 會自動生成一個Buffer ,如果你本身就是Buffer ,那就省了這一步 (注意調用的是user 層面的 new Buffer):
- // Change strings to buffers. SLOW
- if (typeof data == 'string') {
- data = new Buffer(data, encoding);
- }
然后這個Buffer 對應的指針會層層傳遞,直至 uv 的stream.c 的相應的 write 函數,這個過程也不會再有額外的拷貝操作,尤其要注意的是:當你直接傳入一個Buffer 時,直至socket.write 回調返回表示結束,此過程中你不應該再修改它,因為底層正在或將要操作它!
文件讀寫
regular file 的write 和 socket 比較類似,沒什么亮點,我們重點來看 file read。
關于IO 操作時bufsize 大小的重要性,上文已有介紹,記得APUE 中 steven 老先生也有專門的測試結果,此處不再贅述,
在 fs.ReadStream 時,我們可以傳入一些參數:
- { flags: 'r',
- encoding: null,
- fd: null,
- mode: 0666,
- bufferSize: 64 * 1024
- }
默認bufsize 為 64K ,但在 lib/fs.js 中,還有一個poolSize 控制變量:
- var kPoolSize = 40 * 1024;
當node 最終實際調用fs.read 時:
- var thisPool = pool;
- var toRead = Math.min(pool.length - pool.used, this.bufferSize);
- var start = pool.used;
Node 會對用戶傳入的bufsize 與 當前pool 的剩余空間作比較,取其小者而用之,所以默認的64*1024 大小其實是永遠不會生效的。
好吧,40K 大小也可以接受,但如果你要讀取的文件比較小,比如1K ,2K 級別的比較多,這時我們預留40K 的buf ,當讀返回時,其實只用到了1K 或 2K ,這時候,Node 不會再像socket.read 那樣,再把 pool.used 減去 39K 或 38K ,因為我們實際的fs.read 操作是在另一獨立線程中執行的,即 buf alloc → fs read → read cb 這一個過程不是順序的,我們不能再像socket.read 那樣重新設置pool used !這種情況下內存的浪費相當嚴重!
所以當你想緩存大量小文件時,如靜態服務器,我的建議是:自己分配大塊Buffer ,然后把從fs.readStream 上浮的Buffer 拷貝到我們自己的大塊Buffer 中,然后在這個大塊Buffer 上做 slice生成相應的小Buffer ,這樣我們就沒有引用readStream 上浮的Buffer ,使其可以被V8 回收,當然如果你內存足夠你揮霍,當我啥都沒說…
內存池
再來看底層的node_buffer :
void Buffer::Replace(char *data, size_t length, free_callback callback, void *hint)
這個函數的內存操作很單純:
- ….
- delete [] data_;
- ….
- data_ = new char[length_];
其實通過上面分析可知,一個繁忙的網絡服務器,很可能會頻繁的new/delete 8K / 1M 的內存塊,如果是靜態文件服務,可能還會有頻繁的40K 內存塊的操作,所以我試著對node 添加了 8K 內存塊的內存池控制,服務繁忙時命中率無限接近100%,可惜總體性能提升沒有達到預期,在此就不現拙了,有興趣的同學可以自己hack 玩玩,有成果了可以知會我一聲(http://weibo.com/windyrobin)…
小節:
由以上分析,我們可知
◆ 不要輕易持久引用由 socket.readStream 或 fs.readStream 上浮的Buffe
◆ 當你調用stream.write 并直接傳遞Buffer 進去時,在此操作返回之前,你不應該再修改它
◆ 當調用fs.readStream 時,如果你對文件大小有估值,盡量傳入較接近的bufsize
◆ 當你持久引用一個Buffer 時,哪怕它只有一個字節,也可能導致其依賴的slab (可能是8K /1M…)得不到釋放
附:以上分析基于node 0.6 系列,就這方面的問題,我已提交了幾個Issue 給 Node 官方,開發人員正在對以上暴露的問題就行改進:
原文:http://cnodejs.org/blog/?p=4186
【編輯推薦】