













深入理解 Node.js Buffer 的 Encoding
字符怎么存儲呢?就是靠編碼,不同的字符對應不同的編碼,然后在需要渲染的時候根據對應編碼去查字體庫,然后渲染對應字符的圖形。
字符集
字符集(charset)最早是 ASCII 碼,也就是 abc ABC 123 等 128 個字符,因為計算機最早就是美國發明的。后來歐洲也制定了一套字符集標準,叫做 ISO,后來中國也搞了一套,叫做 GBK。
國際標準化組織覺得不能這樣各自搞一套,不然同一個編碼在不同字符集里面就不同的意思,于是就提出了 unicode 編碼,把全世界大部分編碼收錄,這樣每個字符只有唯一的編碼。
但是 ASCII 碼只需要 1 個字節就可以存儲,而 GBK 需要 2 個字節,還有的字符集需要 3 個字節等。有的只要一個字節存儲卻存了 2 個字節,比較浪費空間。所以就出現了 utf-8、utf-16、utf-24 等不同編碼方案。
utf-8、utf-16、utf-24 都是 unicode 編碼,但是具體實現方案不同。
UTF-8 為了節省空間,設計了從 1 到 6 個字節的變長存儲方案。而 UTF-16 是固定 2 個字節,UTF-24 是固定 4 個字節。
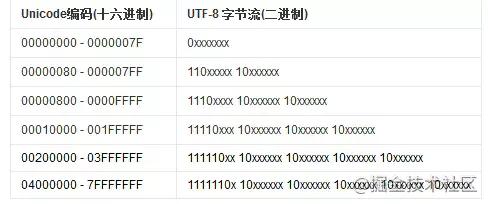
最后,UTF-8 因為占用空間最少,所以被廣泛應用。
Node.js 的 Buffer 的 encoding
每種語言都支持字符集的編碼解碼,Node.js 也同樣。
Node.js 里面可以通過 Buffer 來存儲二進制的數據,而二進制的數據轉為字符串的時候就需要指定字符集,Buffer 的 from、byteLength、lastIndexOf 等方法都支持指定 encoding:
具體支持的 encoding 有這些:
utf8、ucs2、utf16le、latin1、ascii、base64、hex
可能有的同學會發現:base64、hex 不是字符集啊,怎么也出現在這里?
是的,字節到字符的編碼方案除了字符集之外,也有用于轉為明文字符的 base64、以及轉為 16 進制的 hex。
這也是為什么 Node.js 把它叫做 encoding 而不是 charset,因為支持的編解碼方案不只是字符集。
如果不指定 encoding,默認是 utf8。
- const buf = Buffer.alloc(11, 'aGVsbG8gd29ybGQ=', 'base64');
- console.log(buf.toString());// hello world
encoding 的 源碼
我去翻了下 Node.js 關于 encoding 的源碼:
這一段是實現 encoding 的:
https://github.com/nodejs/node/blob/master/lib/buffer.js#L587-L726
可以看到每個 encoding 都實現了 encoding、encodingVal、byteLength、write、slice、indexOf 這幾個 api,因為這些 api 用不同 encoding 方案,會有不同的結果,Node.js 會根據傳入的 encoding 來返回不同的對象,這是一種多態的思想。
- const encodingOps = {
- utf8: {
- encoding: 'utf8',
- encodingVal: encodingsMap.utf8,
- byteLength: byteLengthUtf8,
- write: (buf, string, offset, len) => buf.utf8Write(string, offset, len),
- slice: (buf, start, end) => buf.utf8Slice(start, end),
- indexOf: (buf, val, byteOffset, dir) =>
- indexOfString(buf, val, byteOffset, encodingsMap.utf8, dir)
- },
- ucs2: {
- encoding: 'ucs2',
- encodingVal: encodingsMap.utf16le,
- byteLength: (string) => string.length * 2,
- write: (buf, string, offset, len) => buf.ucs2Write(string, offset, len),
- slice: (buf, start, end) => buf.ucs2Slice(start, end),
- indexOf: (buf, val, byteOffset, dir) =>
- indexOfString(buf, val, byteOffset, encodingsMap.utf16le, dir)
- },
- utf16le: {
- encoding: 'utf16le',
- encodingVal: encodingsMap.utf16le,
- byteLength: (string) => string.length * 2,
- write: (buf, string, offset, len) => buf.ucs2Write(string, offset, len),
- slice: (buf, start, end) => buf.ucs2Slice(start, end),
- indexOf: (buf, val, byteOffset, dir) =>
- indexOfString(buf, val, byteOffset, encodingsMap.utf16le, dir)
- },
- latin1: {
- encoding: 'latin1',
- encodingVal: encodingsMap.latin1,
- byteLength: (string) => string.length,
- write: (buf, string, offset, len) => buf.latin1Write(string, offset, len),
- slice: (buf, start, end) => buf.latin1Slice(start, end),
- indexOf: (buf, val, byteOffset, dir) =>
- indexOfString(buf, val, byteOffset, encodingsMap.latin1, dir)
- },
- ascii: {
- encoding: 'ascii',
- encodingVal: encodingsMap.ascii,
- byteLength: (string) => string.length,
- write: (buf, string, offset, len) => buf.asciiWrite(string, offset, len),
- slice: (buf, start, end) => buf.asciiSlice(start, end),
- indexOf: (buf, val, byteOffset, dir) =>
- indexOfBuffer(buf,
- fromStringFast(val, encodingOps.ascii),
- byteOffset,
- encodingsMap.ascii,
- dir)
- },
- base64: {
- encoding: 'base64',
- encodingVal: encodingsMap.base64,
- byteLength: (string) => base64ByteLength(string, string.length),
- write: (buf, string, offset, len) => buf.base64Write(string, offset, len),
- slice: (buf, start, end) => buf.base64Slice(start, end),
- indexOf: (buf, val, byteOffset, dir) =>
- indexOfBuffer(buf,
- fromStringFast(val, encodingOps.base64),
- byteOffset,
- encodingsMap.base64,
- dir)
- },
- hex: {
- encoding: 'hex',
- encodingVal: encodingsMap.hex,
- byteLength: (string) => string.length >>> 1,
- write: (buf, string, offset, len) => buf.hexWrite(string, offset, len),
- slice: (buf, start, end) => buf.hexSlice(start, end),
- indexOf: (buf, val, byteOffset, dir) =>
- indexOfBuffer(buf,
- fromStringFast(val, encodingOps.hex),
- byteOffset,
- encodingsMap.hex,
- dir)
- }
- };
- function getEncodingOps(encoding) {
- encoding += '';
- switch (encoding.length) {
- case 4:
- if (encoding === 'utf8') return encodingOps.utf8;
- if (encoding === 'ucs2') return encodingOps.ucs2;
- encoding = StringPrototypeToLowerCase(encoding);
- if (encoding === 'utf8') return encodingOps.utf8;
- if (encoding === 'ucs2') return encodingOps.ucs2;
- break;
- case 5:
- if (encoding === 'utf-8') return encodingOps.utf8;
- if (encoding === 'ascii') return encodingOps.ascii;
- if (encoding === 'ucs-2') return encodingOps.ucs2;
- encoding = StringPrototypeToLowerCase(encoding);
- if (encoding === 'utf-8') return encodingOps.utf8;
- if (encoding === 'ascii') return encodingOps.ascii;
- if (encoding === 'ucs-2') return encodingOps.ucs2;
- break;
- case 7:
- if (encoding === 'utf16le' ||
- StringPrototypeToLowerCase(encoding) === 'utf16le')
- return encodingOps.utf16le;
- break;
- case 8:
- if (encoding === 'utf-16le' ||
- StringPrototypeToLowerCase(encoding) === 'utf-16le')
- return encodingOps.utf16le;
- break;
- case 6:
- if (encoding === 'latin1' || encoding === 'binary')
- return encodingOps.latin1;
- if (encoding === 'base64') return encodingOps.base64;
- encoding = StringPrototypeToLowerCase(encoding);
- if (encoding === 'latin1' || encoding === 'binary')
- return encodingOps.latin1;
- if (encoding === 'base64') return encodingOps.base64;
- break;
- case 3:
- if (encoding === 'hex' || StringPrototypeToLowerCase(encoding) === 'hex')
- return encodingOps.hex;
- break;
- }
- }
總結
計算機中存儲數據的最小單位是位,但是存儲信息最小的單位是字節,基于編碼和字符的映射關系又實現了各種字符集,包括 ascii、iso、gbk 等,而國際標準化組織提出了 unicode 來包含所有字符,unicode 實現方案有若干種:utf-8、utf-16、utf-32,他們分別用不同的字節數來存儲字符。其中 utf-8 是變長的,存儲體積最小,所以被廣泛應用。
Node.js 通過 Buffer 存儲二進制數據,而轉為字符串時需要指定編碼方案,這個編碼方案不只是包含字符集(charset),也支持 hex、base64 的方案,包括:
utf8、ucs2、utf16le、latin1、ascii、base64、hex
我們看了下 encoding 的 Node.js 源碼,發現每種編碼方案都會用實現一系列 api,這是一種多態的思想。














