













Nature封面:乘著AI的翅膀,數據「帶飛」計算社會科學
早在蘇美爾王國時期,這個智慧王國的子民就開始記錄數據,進行人口普查、分配糧食。
全世界最早產生的文明之一蘇美爾的人口普查記錄
蘇美爾人貢獻了書面數據分析的最早記錄。
隨著計算機的出現,人們開始用機器分析大型數據集,這一階段最早可以追溯到大型計算機時代。
計算機大大加快了數據分析的速度,被廣泛應用在審計和人口普查上。
而這種將大量數據分析與社會問題相結合的工作,即計算社會科學(Computational social science)近年來得到了巨大的發展。
巨大的發展伴隨的是沒有限制、不受監管的數據收集。

這其中存在很大風險:缺乏監控以及從匿名數據中重新識別身份的風險。
還有人擔心,收集數據卻沒有征得當事人的同意怎么辦?
大部分數據都被少數大型科技公司壟斷怎么辦?
不僅大型科技公司掌握數據、數據使用權在向發達國家、富裕人群傾斜,這樣做出的決策難免會有偏差。
所以,目前需要我們將社會科學和不同學科以及收集分析大型數據集所需的技能結合起來,這就需要跨學科的合作。
但是,目前跨學科合作面臨諸多挑戰。
今天,Nature就以特刊形式討論了目前計算社會科學面臨的挑戰和機遇。

克服跨學科的語言障礙
計算社會科學集社會、自然、計算科學等學科于一身。
同一個詞,在不同學科之間可能有不同的含義,在這種情況下就很容易「雞同鴨講」。
例如,在社會科學領域,「預測」(prediction)通常含有「相關」的意思;而在物理科學領域,這個詞更多指的是「預測」。
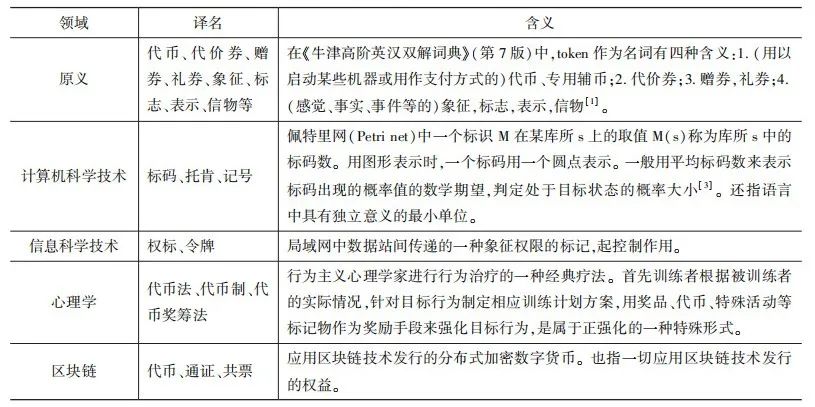
「token」在不同領域里也有不同含義
因此,不同學科之間需要克服同一術語表達不同意思的語言障礙。開展跨學科研究時,科學家們首先需要學會彼此的語言,然后得出一種能夠相互理解的術語。
但比起語言障礙,更難的是如何展示、分析和解釋數據,最終解釋某種現象。
比方說,要想了解交通擁堵的原因,研究人員會收集并預測交通流量數據,還會從司機口中了解到他們選擇特定路線的原因。計算社會科學的學科互補特性,能更高效地回答研究問題。
處理數據的「大忌」
所有研究結果取決于分析策略,還取決于數據的質量,在處理社會數據的時候更是如此。
要想完成計算社會科學的研究,就先得要有大量的數據,如手機的定位信息。但是這些信息通常不是出于研究目的才收集的,因此很容易被人誤解。
僅從數字中觀察到趨勢或模式中就得出結論,這是研究人員處理大數據集的「大忌」。研究人員應該考慮可能會影響結果的因素。
為了提取數據的真正意義,研究人員需要確保他們根據理論,仔細地定義測量對象,并適當地進行驗證和解釋。
算法的廣泛影響是另一個潛在錯誤。算法遍及整個社會,以不同的方式影響著個人和群體行為,這意味著,所有的觀察不僅在描述人類行為,還在描述算法對人們行為方式的影響。
社會科學理論需要更新,承認算法帶來的影響;要是沒有這些理論,沒有清晰理解算法對可用數據的影響,研究人員就無法得出有意義的結論。
共享數據的難處
大型數據集通常是商企的私有財產,這是計算社會科學的另一個復雜問題。搞學術的科學家需要跟企業聯系才能獲得訪問權限,這有可能會產生更多偏見。
對于公司而言,數據是有價值的,因此共享數據會冒犯到公司的「底線」。這也是公司傾向于限制共享內容的原因之一。
但考慮到這些數據能提供社會效益,公司——連同學術研究人員和公共機構——需要共同解決這些問題,并為數據的質量、數據訪問和數據所有權制定標準。
未來獲取數據的方式
一篇關于「人類社會感知」的文章對于如何獲得有用、可靠的數據列舉了一些方法。這是對個人如何在其社交網絡中收集他人信息的研究。
例如,研究人員可以通過采訪對象并詢問他們的朋友在談論什么,從而預測出政治觀點的變化。
收集他人的數據有助于避免自我報告數據中出現的一些偏見,生成匿名數據也有額外好處:研究人員永遠不需要知道他們獲得的數據中,任何有關個人或敏感細節的信息。
獲取數據的方式變得更加成熟,這一點體現在傳染病建模和行為科學的交叉領域。
要建立準確的傳染和感染模型,研究人員需要了解患病人群的文化和行為。如果不考慮傳播的這些和其他社會方面的傳播因素,就難以預測疾病的傳播路徑。跨學科的結構和廣泛合作十分關鍵。
而新冠肺炎疫情已經表明,大規模數據集應用于科學能夠挽救生命。隨著具有計算機科學或應用數學背景的研究人員與社會科學家的合作,而這種潛力才剛剛開始顯現。






















