













為什么數組的下標從 0 開始?
作者: Tom哥
數組是一組連續內存空間存儲的具有相同類型的數據,整個排列像一條線一樣,是一種線性表數據結構。
本文轉載自微信公眾號「微觀技術」,作者Tom哥 。轉載本文請聯系微觀技術公眾號。
首先,我們來復習下數組的定義
數組是一組連續內存空間存儲的具有相同類型的數據,整個排列像一條線一樣,是一種線性表數據結構。
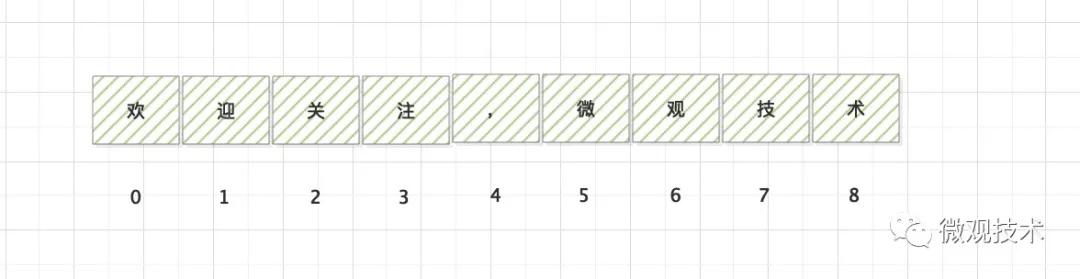
那么,問題來了,數組的下標為什么要從 0 開始?從 1 開始行不行?
端好你的小茶杯,開始進入正題
數組之所以廣泛使用,是因為它支持隨機訪問。
什么叫隨機訪問?
數據在內存中都是按順序存放的,通過下標直接觸達到某一個元素存放的位置。
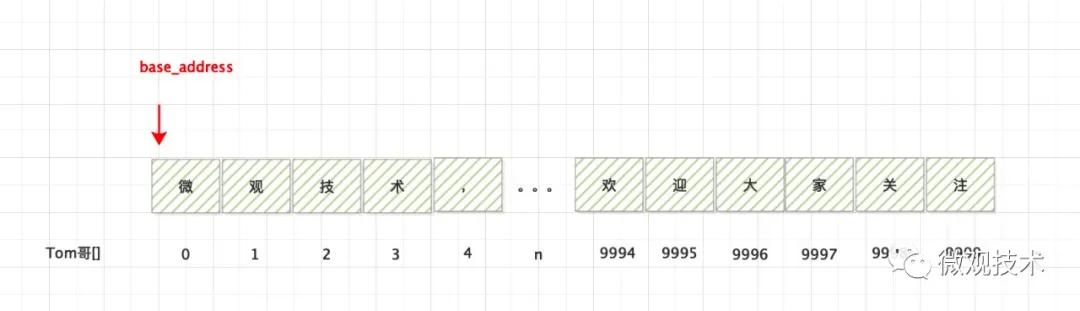
公式:
- Tom哥[n] = base_address + n * data_size
- base_address,表示數組的首地址
- n,表示偏移量
- data_size,表示數組類型的字節數
- ① 讀取上面數組的 【0】位置的 `微`
- ② 讀取上面數組的 【9999】位置的 `注`
- 由于基于計算的內存地址讀取數據,上面兩種情況的耗費的時間是一樣,時間復雜度為 O(1)
注意:想要使用隨機訪問,一定要滿足兩個條件: 1、連續的內存空間 2、相同類型的數據
知識補充:
與隨機訪問對應的是順序訪問
順序訪問:鏈表在內存中不是按順序存放的,而是通過指針連在一起,訪問某一元素,必須從鏈頭開始順著指針才能找到某一個元素。
突然,一個奇怪的念頭冒了出來,假如我們將數組的首個下標從 1 開始 ,會怎么樣?
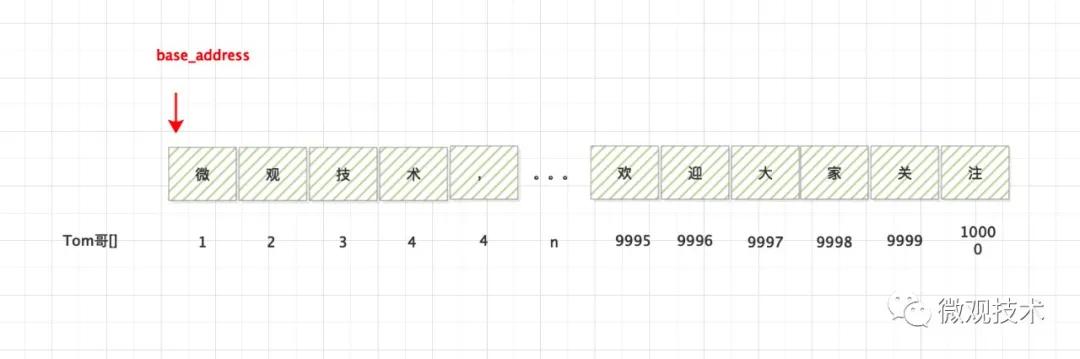
我們讀取 下標為n 的數據
公式:
- Tom哥[n] = base_address + (n-1) * data_size
與上面的公式的區別,多了一次 n-1 操作
雖然也能讀取數組中的值,但是多了一次減法的指令運算。
數組是一個最基礎、最簡單的數據結構。要知道我們的上層API內部很多都會依賴于數組,而互聯網應用又講究一個高并發,一言不合就是千萬級QPS,如此高頻的訪問量,這個冗余的減運算 就會放大無數倍,產生巨大的性能損耗。
這樣說,可能大家感受不一定明顯!!!
”我在馬路邊撿到一分錢,把它交到警察叔叔手里邊“。現在再有一分錢,你還會撿嗎,估計很多人都看不上眼,但要是全國人民每人給你一分錢呢
14億 * 1分錢 = 1400萬 人民幣
是不是可以立馬辭職,回家躺平了!
量變引發質變,做軟件開發,我們一定要考慮將性能優化到極致,骨子里透著工匠精神。
責任編輯:武曉燕
來源:
微觀技術





















