Redis 內存壓縮實戰(zhàn),學習了!
在討論Redis內存壓縮的時候,我們需要了解一下幾個Redis的相關知識。
壓縮列表 ziplist
Redis的ziplist是用一段連續(xù)的內存來存儲列表數(shù)據(jù)的一個數(shù)據(jù)結構,它的結構示例如下圖

壓縮列表組成示例--截圖來自《Redis設計與實現(xiàn)》
- zlbytes: 記錄整個壓縮列表使用的內存大小
- zltail: 記錄壓縮列表表尾距離起始位置有多少字節(jié)
- zllen: 記錄壓縮列表節(jié)點數(shù)量,值得注意的一點是,因為它只占了2個字節(jié),所以最大值只能到65535,這意味著壓縮列表長度大于65535的時候,就只能通過遍歷整個列表來計算長度了
- zleng: 壓縮列表末端標志位,固定值為OxFF
- entry1-N: 壓縮列表節(jié)點, 具體結構如下圖

壓縮列表節(jié)點組成示例--截圖來自《Redis設計與實現(xiàn)》
其中
- previous_entry_length: 上一個節(jié)點的長度
- encoding: content的編碼以及長度
- content: 節(jié)點數(shù)據(jù)
當我們查找一個節(jié)點的時候,主要進行一下操作:
- 根據(jù)zltail獲取最后一個節(jié)點的位置
- 判斷當前節(jié)點是否是目標節(jié)點
- 如果是,則返回數(shù)據(jù)
- 如果不是,則根據(jù)previous_entry_length計算上一個節(jié)點的起始位置,然后重新進行步驟2判斷
通過上述的描述,我們可以知道,ziplist每次數(shù)據(jù)更新的復雜度大約是O(N),因為它需要對N個節(jié)點進行內存重分配,查找一個數(shù)據(jù)的時候,復雜度是O(N),最壞情況下需要遍歷整個列表。
什么情況下會使用到ziplist呢?
Redis會使用到ziplist的數(shù)據(jù)結構是Hash與List。
Hash結構使用ziplist作為底層存儲的兩個條件是:
- 所有的鍵與值的字符串長度都小于64字節(jié)的時候
- 鍵與值對數(shù)據(jù)小于512個
只要上述條件任何一個不滿足,Redis就會自動將這個Hash對象從ziplist轉換成hashtable。但這兩個閾值可以通過修改配置文件中的hash-max-ziplist-value與hash-max-ziplist-entries來變更。
List結構使用ziplist的條件與Hash結構一樣,當條件不滿足的時候,會從ziplist轉換成linkedlist,同樣我們可以修改list-max-ziplist-value與hash-max-ziplist-entries來使用不同的閾值。
為什么Hash與List會使用ziplist來存儲數(shù)據(jù)呢?
因為
- ziplist會比hashtable與ziplist節(jié)省跟多的內存
- 內存中以連續(xù)塊方式保存的數(shù)據(jù)比起hashtable與linkedlist使用的鏈表可以更快的載入緩存中
- 當ziplist的長度比較小的時候,從ziplist讀寫數(shù)據(jù)的效率比hashtable或者linkedlist的差異并不大。
本質上,使用ziplist就是以時間換空間的一種優(yōu)化,但是他的時間損壞小到幾乎可以忽略不計,但卻能帶來可觀的內存減少,所以滿足條件時,Redis會使用ziplist作為Hash與List的存儲結構。
實戰(zhàn)
我們先拋出問題,在廣告程序化交易的過程中,我們經(jīng)常需要為一個廣告投放計劃定制人群包,其存儲的形式如下:
- 人群包ID => [設備ID_1, 設備ID_2 ... 設備ID_N]
其中,人群包ID是Long型整數(shù),設備ID是經(jīng)過MD5處理,長度為32。在業(yè)務場景中,我們需要判斷一個設備ID是否在一個人群包中,來決定是否投放廣告。另外,Redis 系列面試題和答案全部整理好了,微信搜索Java技術棧,在后臺發(fā)送:面試,可以在線閱讀。
在傳統(tǒng)的使用Redis的場景, 我們可以使用標準的KV結構來存儲定向包數(shù)據(jù),則存儲方式如下:
- {人群包ID}_{設備ID_1} => true
- {人群包ID}_{設備ID_2} => true
如果我們想使用ziplist來繼續(xù)內存壓縮的話,我們必須保證Hash對象的長度小于512,并且鍵值的長度小于64字節(jié)。我們可以將KV結構的數(shù)據(jù),存儲到預先分配好的bucket中。
我們先預估下,整個Redis集群預計容納的數(shù)據(jù)條數(shù)為10億,那么Bucket的數(shù)量的計算公式如下:
- bucket_count = 10億 / 512 = 195W
那么我們大概需要200W個Bucket(預估Bucket數(shù)量需要多預估一點,以防觸發(fā)臨界值問題) 我們先以下公式計算BucketID:
- bucket_id = CRC32(人群包ID + "_" + 設備ID) % 200W
那么數(shù)據(jù)在Redis的存儲結構就變成
- bucket_id => {
- {人群包ID}_{設備ID_1} => true
- {人群包ID}_{設備ID_2} => true
- }
這樣我們保證每個bucket中的數(shù)據(jù)項都小于512,并且長度均小于64字節(jié)。點擊這里可以刷 Redis 系列面試題。
我們以2000W數(shù)據(jù)進行測試,前后兩者的內存使用情況如下:
| 數(shù)據(jù)集大小 | 存儲模式 | Bucket數(shù)量 | 所用內存 | 碎片率 | Redis占用的內存 |
|---|---|---|---|---|---|
| 2000W | 壓縮列表 | 200W | 928M | 1.38 | 1.25G |
| 2000W | 壓縮列表 | 5W | 785M | 1.48 | 1.14G |
| 2000W | 直接存儲 | - | 1.44G | 1.03 | 1.48G |
在這里需要額外引入一個概念 – 內存碎片率。
- 內存碎片率 = 操作系統(tǒng)給Redis分配的內存 / Redis存儲對象占用的內存
因為壓縮列表在更新節(jié)點的時候,經(jīng)常需要進行內存重分配,所以導致比較高的內存碎片率。我們在做技術方案比較的時候,內存碎片率也是非常需要關注的指標之一。
但有很多手段可以減少內存碎片率,比如內存對其,甚至更極端的直接重做整個Redis內存(利用快照或者從節(jié)點來重做內存)都能有效的減低內存碎片率。
我們在本次實驗中,因為存儲的數(shù)值比較大(單個KEY約34個字節(jié)),所以實際節(jié)省內存不是很多,但依然能節(jié)約35%-50%的內存使用。
在實際的生產(chǎn)環(huán)境中,我們根據(jù)應用場景合理的設計壓縮存儲結構,部分業(yè)務甚至能達到節(jié)約70%的內存使用的效果。
壓縮列表能節(jié)省多少內存?
我們現(xiàn)在知道壓縮列表是通過將節(jié)點緊湊的排列在內存中,從而節(jié)省掉內存的。但他究竟節(jié)省了哪些內存從而能達到驚人的壓縮率呢?
首先為了明白這個細節(jié),我們需要知道普通Key-Value結構在Redis中是如何存儲的。
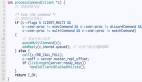
- typedef struct redisObject {
- unsigned type:4; // 對象的類型
- unsigned encoding:4; // 對象的編碼
- unsigned lru:LRU_BITS; // LRU類型
- int refcount; // 引用計數(shù)
- void *ptr; // 指向底層數(shù)據(jù)結構的指針
- } robj;
Redis所有的對象都是通過上述結構來存儲, 假設我存儲Hello=>World這樣一個健值對到Redis中,除了存儲本身鍵值的數(shù)據(jù)外,還需要額外的24個字節(jié)來存儲redisObject對象。
而Redis存儲字符串使用的SDS數(shù)據(jù)結構
- struct sdshdr8 {
- uint8_t len; // 所保存字符串的長度
- uint8_t alloc; // 分配的內存數(shù)量
- unsigned char flags;// 標志位,用于判斷sdshdr類型
- char buf[]; // 字節(jié)數(shù)組,用戶保存字符串
- };
假如字符串的長度無法用unsigned int8來表示的話,Redis會使用能表達更大長度的sdshdr16結構來存儲字符串。
并且,為了減少修改字符串帶來的內存重分類問題,Redis會進行內存預分配,所以可能你僅僅為了保存五個字符,但Redis會為你預分配10 bytes的內存。
這意味著當我們存儲Hello這個字符串的時候,你需要額外的3個以上的字節(jié)。
Oh~~~,我只想保存Hello=>World這十個字符的數(shù)據(jù),竟然需要的30~40個字節(jié)的數(shù)據(jù)來存儲額外的信息,比存儲數(shù)據(jù)本身的大小還多一些。這還沒包括Redis維護字典表所需要的額外的內存空間。
那么假設我們用ziplist來存儲這個數(shù)據(jù),我們僅僅需要額外的2個字節(jié)用于存儲previous_entry_length與encoding。具體的計算方式可以參考Redis源碼或者《Redis設計與實現(xiàn)》第一部分第7章壓縮列表。
總結
從以上對比,我們可以看出,在存儲越小的數(shù)據(jù)的時候,使用ziplist來進行數(shù)據(jù)壓縮能得到更好的壓縮率。但副作用也很明顯,ziplist的更新效率遠遠低于普通K-V模式,并且會造成額外的內存碎片率。
在Redis中存儲大量數(shù)據(jù)的實踐過程中,我們經(jīng)常會做一些小技巧來盡可能壓榨Redis的存儲能力。另外,關注公眾號Java技術棧,在后臺回復:面試,可以獲取我整理的 Redis 系列面試題和答案,非常齊全。