再批 MySQL Json

本文轉載自微信公眾號「董澤潤的技術筆記」,作者董澤潤。轉載本文請聯系董澤潤的技術筆記公眾號。
上一篇弱智的 MySQL NULL, 居然有小伙伴留言說,在業務中依賴 NULL 使聯合索引不唯一的特性,比如有的用戶就要多條記錄,有的僅一條。
我看了差點一口老血噴出來,把業務邏輯耦合在 DB 中這樣真的合適嘛? 要是外包另當別論,正常項目誰接手誰倒霉。
討伐 json
今天的分享是再批 json, 去年分享過因為 mysql json 導致的故障,今天的 case 其實是去年的姊妹篇,原理一模一樣。有兩個原因不建議用 json:
- Table Schema 就是強一致的,約束開發不要亂搞,json 這種弱約束的就是開后門,時間一長 json 字段就成了下水道
- MySQL JSON 很垃圾,5.7 系列都有性能問題,測試 8.0 好很多。強烈建義大家,使用前壓測一下
上面提到的兩點有爭議?有爭議就對了,一致認同是垃圾的東西誰會討論它呢?
實現
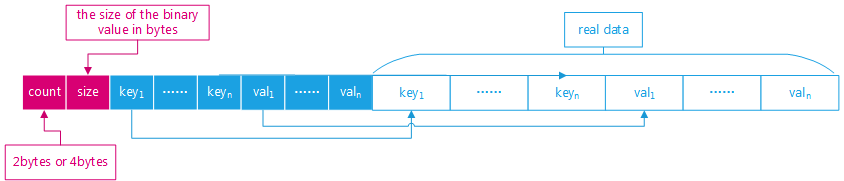
JSON 有兩種表示方法:文本可讀的在 mysql 中對應 json_dom.cc, binary 二進制表示的對應 json_binary.cc
Binary Format
- If the value is a JSON object, its binary representation will have a
- header that contains:
- - the member count
- - the size of the binary value in bytes
- - a list of pointers to each key
- - a list of pointers to each value
- The actual keys and values will come after the header, in the same
- order as in the header.
- Similarly, if the value is a JSON array, the binary representation
- will have a header with
- - the element count
- - the size of the binary value in bytes
- - a list of pointers to each value
源碼中注釋也寫的比較清楚,二進制分成兩部分 header + element. 實際上 mysql 只是 server 識別了 json, 各個存儲引擎仍存儲的二進制 blob
換句話說,底層引擎對 json 是無感知的,就是一條數據而己
json-function-reference[1] 官方有好多在 server 層操作 json 的方法,感興趣的可以看一下
我們的問題
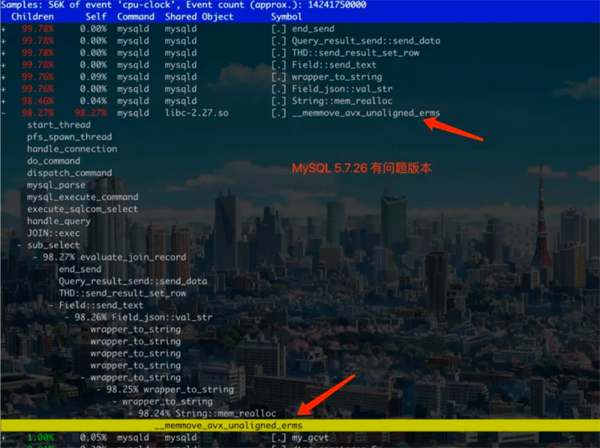
MySQL Client 讀取 json 時是 json_dom 調用 wrapper_to_string 方法,序列化成可讀格式數據
寫入 json 時,是由 json_binary 調用 serialize_json_value 方法,序列化成上面圖表示的 binary 數據,然后由引擎層存儲成 blob 格式
去年故障也有服務端的問題:加載單條數據失敗主動 panic, 坑人不淺 (理由是數據不一致,寧可不對外提供服務,問題是那條數據恰好是重不重要的一類)。所以這個故事告訴我們: 在線服務的可用性,遠高于數據一致性
慢的原因是 wrapper_to_string 遇到 json array 特別多的情況下反復 mem_realloc 創建內存空間,導致性能下降
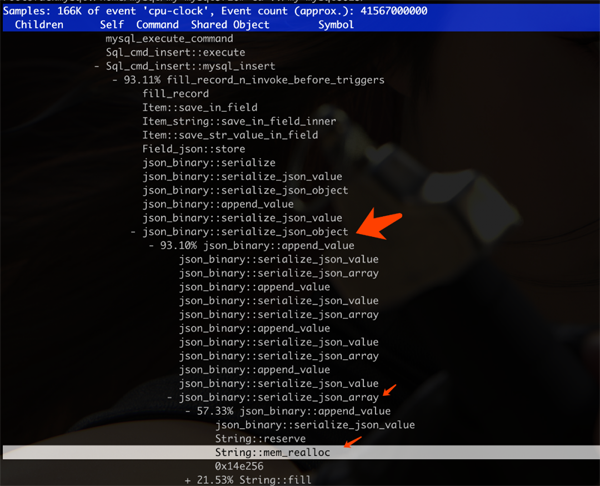
其實去年沒有 fix 完整,最近發現寫入也有類似問題,只不過是 serialize_json_value 寫入存儲引擎前反復 mem_realloc 造成超時。這時前端頁面發現寫入超時了,(人工)重試繼續寫入 json 數據
恰好趕上聯合索引中有 NULL 字段,由此引出了唯一索引不唯一的現象。那怎么解決呢?前端按鈕 cooldown 治標不治本,sql 執行 12s 前端肯定又點擊提交了,治本還得升級 mysql 8.0 并且移除 NULL 字段, 那會不會又引入其它問題呢?
項目初期做了錯誤的決定,后人很容易買單。希望我們踩到的坑,能讓你決定使用 json 前猶豫幾秒鐘 ^^
8.0 fix
在測試機上發現 8.0 是 ok 的,沒有性能問題,查看提交的 commit, 2016 年就有人發現并 fix 了,不知道有沒有 back port 到 mysql 5.7 那幾個版本
- commit a2f9ea422e4bdfd65da6dd0c497dc233629ec52e
- Author: Knut Anders Hatlen <knut.hatlen@oracle.com>
- Date: Fri Apr 1 12:56:23 2016 +0200
- Bug#23031146: INSERTING 64K SIZE RECORDS TAKE TOO MUCH TIME
- If a JSON value consists of a large sub-document which is wrapped in
- many levels of JSON arrays or objects, serialization of the JSON value
- may take a very long time to complete.
- This is caused by how the serialization switches between the small
- storage format (used by documents that need less than 64KB) and the
- large storage format. When it detects that the large storage format
- has to be used, it redoes the serialization of the current
- sub-document using the large format. But this re-serialization has to
- be redone again when the parent of the sub-document is switched from
- small format to large format. For deeply nested documents, the inner
- parts end up getting re-serializing again and again.
- This patch changes how the switch between the formats is done. Instead
- of starting with re-serializing the inner parts, it now starts with
- the outer parts. If a sub-document exceeds the maximum size for the
- small format, we know that the parent document will exceed it and need
- to be re-serialized too. Re-serializing an inner document is therefore
- a waste of time if we haven't already expanded its parent. By starting
- with expanding the outer parts of the JSON document, we avoid the
- wasted work and speed up the serialization.
參考資料
[1]json-function-reference: https://dev.mysql.com/doc/refman/5.7/en/json-function-reference.html