MaxCompute 中如何通過 logview 診斷慢作業(yè)
在這里把任務(wù)跑的慢的問題劃分為以下幾類
資源不足導(dǎo)致的排隊(一般是包年包月項目)
數(shù)據(jù)傾斜,數(shù)據(jù)膨脹
用戶自身邏輯導(dǎo)致的運行效率低下
一、資源不足
一般的SQL任務(wù)會占用CPU、Memory這兩個維度的資源,logview如何查看參考鏈接
1.1 查看作業(yè)耗時和執(zhí)行的階段

1.2 提交任務(wù)的等待
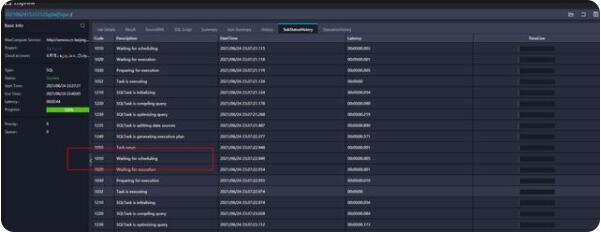
如果提交任務(wù)以后一直顯示“Job Queueing...”則有可能是由于其他人的任務(wù)占用了資源組的資源,使得自己的任務(wù)在排隊。
在SubStatusHistory中看Waiting for scheduling就是等待的時間
1.3 任務(wù)提交后的資源不足
這里還有另一種情況,雖然任務(wù)可以提交成功,但是由于所需的資源較大,當(dāng)前的資源組不能同時啟動所有的實例,導(dǎo)致出現(xiàn)了任務(wù)雖然有進度,但是執(zhí)行并不快的情況。這種可以通過logview中的latency chart功能觀察到。latency chart可以在detail中點擊相應(yīng)的task看到
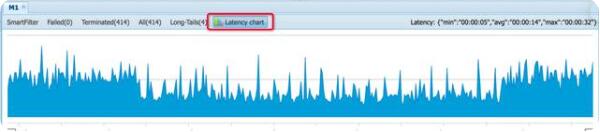
上圖顯示的是一個資源充足的任務(wù)運行狀態(tài),可以看到藍(lán)色部分的下端都是平齊的,表示幾乎在同一時間啟動了所有的實例。
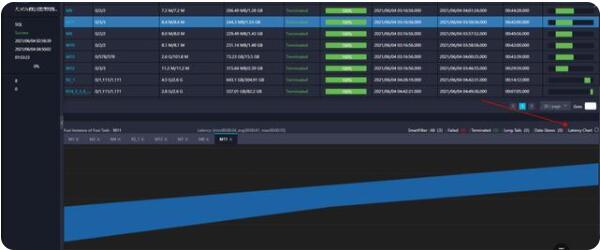
而這個圖形的下端呈現(xiàn)階梯向上的形態(tài),表示任務(wù)的實例是一點一點的調(diào)度起來的,運行任務(wù)時資源并不充足。如果任務(wù)的重要性較高,可以考慮增加資源,或者調(diào)高任務(wù)的優(yōu)先級。
1.4資源不足的原因
1.通過cu管家查看cu是否占滿,點到對應(yīng)的任務(wù)點,找到對應(yīng)時間看作業(yè)提交的情況
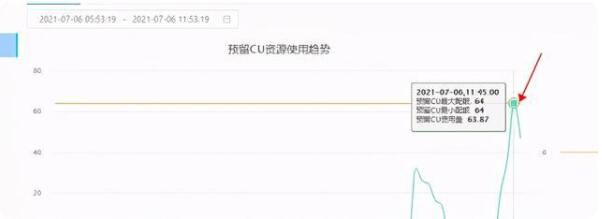
按cpu占比進行排序
(1)某個任務(wù)占用cu特別大,找到大任務(wù)看logview是什么原因造成(小文件過多、數(shù)據(jù)量確實需要這么多資源)。(2)cu占比均勻說明是同時提交多個大任務(wù)把cu資源直接打滿,

2.由于小文件過多導(dǎo)致cu占慢
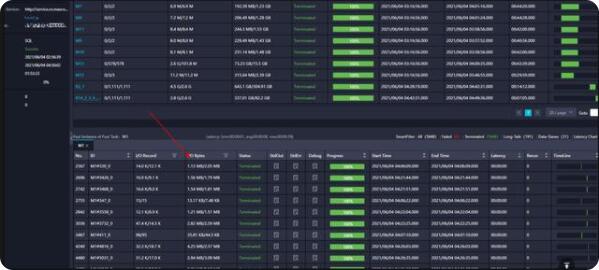
map階段的并行度是根據(jù)輸入文件的分片大小,從而間接控制每個Map階段下Worker的數(shù)量。默認(rèn)是256m。如果是小文件會當(dāng)作一個塊讀取如下圖map階段m1每個task的i/o bytes都只有1m或者幾十kb,所以造成2500多個并行度瞬間把資源打滿,說明該表下文件過多需要合并小文件
合并小文件https://help.aliyun.com/knowledge_detail/150531.html?spm=a2c4g.11186623.6.1198.60ea4560Hr5H8d#section-5nj-hoa-d7f
3.數(shù)據(jù)量大導(dǎo)致資源占滿
可以增加購買資源,如果是臨時作業(yè)可以加set odps.task.quota.preference.tag=payasyougo;參數(shù),可以讓指定作業(yè)臨時跑到按量付費大資源池,
1.5任務(wù)并行度如何調(diào)節(jié)
MaxCompute的并行度會根據(jù)輸入的數(shù)據(jù)和任務(wù)復(fù)雜度自動推測執(zhí)行,一般不需要調(diào)節(jié),理想情況并行度越大速度處理越快但是對于包年包月資源組可能會把資源組占滿,導(dǎo)致任務(wù)都在等待資源這種情況會導(dǎo)致任務(wù)變慢
map階段并行度
odps.stage.mapper.split.size :修改每個Map Worker的輸入數(shù)據(jù)量,即輸入文件的分片大小,從而間接控制每個Map階段下Worker的數(shù)量。單位MB,默認(rèn)值為256 MB
reduce的并行度
odps.stage.reducer.num :修改每個Reduce階段的Worker數(shù)量
odps.stage.num:修改MaxCompute指定任務(wù)下所有Worker的并發(fā)數(shù),優(yōu)先級低于odps.stage.mapper.split.size、odps.stage.reducer.mem和odps.stage.joiner.num屬性。
odps.stage.joiner.num:修改每個Join階段的Worker數(shù)量。
二、數(shù)據(jù)傾斜
數(shù)據(jù)傾斜
【特征】task 中大多數(shù) instance 都已經(jīng)結(jié)束了,但是有某幾個 instance 卻遲遲不結(jié)束(長尾)。如下圖中大多數(shù)(358個)instance 都結(jié)束了,但是還有 18 個的狀態(tài)是 Running,這些 instance 運行的慢,可能是因為處理的數(shù)據(jù)多,也可能是這些instance 處理特定數(shù)據(jù)慢。
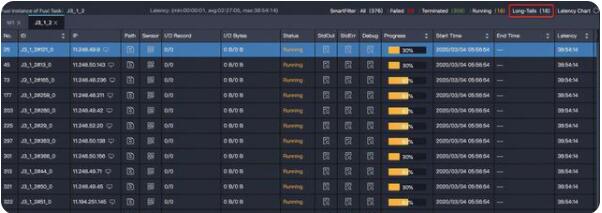
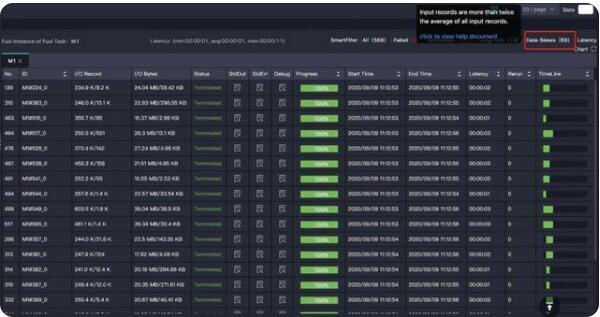
解決方法:https://help.aliyun.com/document_detail/102614.html?spm=a2c4g.11186623.6.1160.28c978569uyE9f
三、邏輯問題
這里指用戶的SQL或者UDF邏輯低效,或者沒有使用最優(yōu)的參數(shù)設(shè)定。表現(xiàn)出來的現(xiàn)象時一個Task的運行時間很長,而且每個實例的運行時間也比較均勻。這里的情況更加多種多樣,有些是確實邏輯復(fù)雜,有些則有較大的優(yōu)化空間。
數(shù)據(jù)膨脹
【特征】task 的輸出數(shù)據(jù)量比輸入數(shù)據(jù)量大很多。
比如 1G 的數(shù)據(jù)經(jīng)過處理,變成了 1T,在一個 instance 下處理 1T 的數(shù)據(jù),運行效率肯定會大大降低。輸入輸出數(shù)據(jù)量體現(xiàn)在 Task 的 I/O Record 和 I/O Bytes 這兩項:
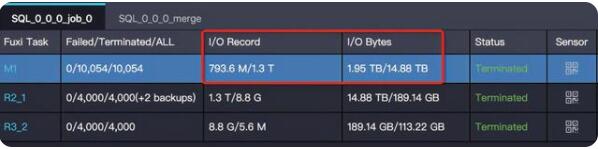
解決方法:確認(rèn)業(yè)務(wù)邏輯確實需要這樣,增大對應(yīng)階段并行度
UDF執(zhí)行效率低
【特征】某個 task 執(zhí)行效率低,且該 task 中有用戶自定義的擴展。甚至是 UDF 的執(zhí)行超時報錯:“Fuxi job failed - WorkerRestart errCode:252,errMsg:kInstanceMonitorTimeout, usually caused by bad udf performance”。
首先確定udf位置,點看慢的fuxi task, 可以看到operator graph 中是否包含udf,例如下圖說明有java 的udf。
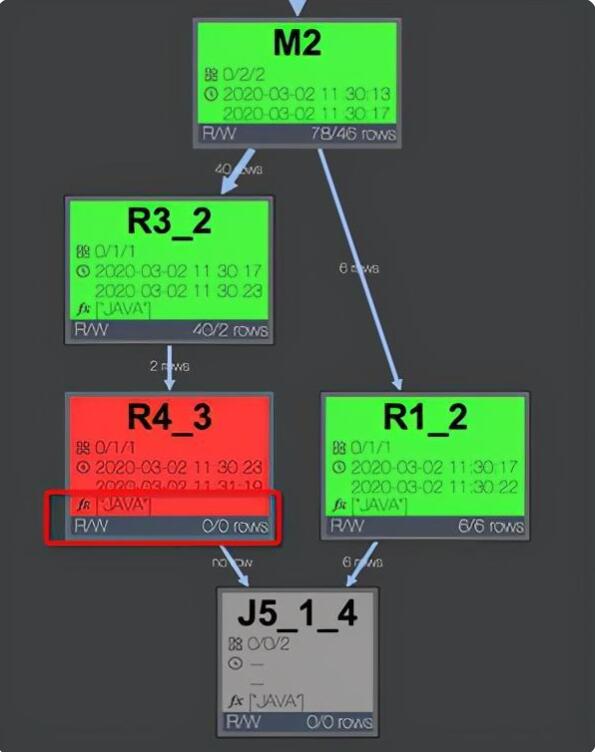
通過查看logview 中fuxi instance 的stdout 可以查看該operator 運行速度,正常情況 Speed(records/s) 在百萬或者十萬級別。

解決方法:檢查udf邏輯盡量使用內(nèi)置函數(shù)
原文鏈接:http://click.aliyun.com/m/1000283552/