













徹底搞懂Java線程池的工作原理
前言
多線程并發是Java語言中非常重要的一塊內容,同時,也是Java基礎的一個難點。說它重要是因為多線程是日常開發中頻繁用到的知識,說它難是因為多線程并發涉及到的知識點非常之多,想要完全掌握Java的并發相關知識并非易事。也正因此,Java并發成了Java面試中最高頻的知識點之一。
本篇文章將深入分析Java中線程池的工作原理。個人認為線程池是Java并發中比較難已理解的一塊知識,因為線程池內部實現使用到了大量的像ReentrantLock、AQS、AtomicInteger、CAS以及“生產者-消費者”模型等并發相關的知識,基本上涵蓋了并發系列前幾篇文章的大部分知識點。這也是為什么把線程池放到最后來寫的原因。本篇文章權當是一個并發系列的綜合練習,剛好鞏固實踐一下前面知識點的運用。
線程池基礎知識
在Java語言中,雖然創建并啟動一個線程非常方便,但是由于創建線程需要占用一定的操作系統資源,在高并發的情況下,頻繁的創建和銷毀線程會大量消耗CPU和內存資源,對程序性能造成很大的影響。為了避免這一問題,Java給我們提供了線程池。
線程池是一種基于池化技術思想來管理線程的工具。在線程池中維護了多個線程,由線程池統一的管理調配線程來執行任務。通過線程復用,減少了頻繁創建和銷毀線程的開銷。
本章內容我們先來了解一下線程池的一些基礎知識,學習如何使用線程池以及了解線程池的生命周期。
線程池的使用
線程池的使用和創建可以說非常的簡單,這得益于JDK提供給我們良好封裝的API。線程池的實現被封裝到了ThreadPoolExecutor中,我們可以通過ThreadPoolExecutor的構造方法來實例化出一個線程池,代碼如下:
- // 實例化一個線程池
- ThreadPoolExecutor executor = new ThreadPoolExecutor(3, 10, 60,
- TimeUnit.SECONDS, new ArrayBlockingQueue<>(20));
- // 使用線程池執行一個任務
- executor.execute(() -> {
- // Do something
- });
- // 關閉線程池,會阻止新任務提交,但不影響已提交的任務
- executor.shutdown();
- // 關閉線程池,阻止新任務提交,并且中斷當前正在運行的線程
- executor.showdownNow();
創建好線程池后直接調用execute方法并傳入一個Runnable參數即可將任務交給線程池執行,通過shutdown/shutdownNow方法可以關閉線程池。
ThreadPoolExecutor的構造方法中參數眾多,對于初學者而言在沒有了解各個參數的作用的情況下很難去配置合適的線程池。因此Java還為我們提供了一個線程池工具類Executors來快捷的創建線程池。Executors提供了很多簡便的創建線程池的方法,舉兩個例子,代碼如下:
- // 實例化一個單線程的線程池
- ExecutorService singleExecutor = Executors.newSingleThreadExecutor();
- // 創建固定線程個數的線程池
- ExecutorService fixedExecutor = Executors.newFixedThreadPool(10);
- // 創建一個可重用固定線程數的線程池
- ExecutorService executorService2 = Executors.newCachedThreadPool();
但是,通常來說在實際開發中并不推薦直接使用Executors來創建線程池,而是需要根據項目實際情況配置適合自己項目的線程池,關于如何配置合適的線程池這是后話,需要我們理解線程池的各個參數以及線程池的工作原理之后才能有答案。
線程池的生命周期
線程池從誕生到死亡,中間會經歷RUNNING、SHUTDOWN、STOP、TIDYING、TERMINATED五個生命周期狀態。
- RUNNING 表示線程池處于運行狀態,能夠接受新提交的任務且能對已添加的任務進行處理。RUNNING狀態是線程池的初始化狀態,線程池一旦被創建就處于RUNNING狀態。
- SHUTDOWN 線程處于關閉狀態,不接受新任務,但可以處理已添加的任務。RUNNING狀態的線程池調用shutdown后會進入SHUTDOWN狀態。
- STOP 線程池處于停止狀態,不接收任務,不處理已添加的任務,且會中斷正在執行任務的線程。RUNNING狀態的線程池調用了shutdownNow后會進入STOP狀態。
- TIDYING 當所有任務已終止,且任務數量為0時,線程池會進入TIDYING。當線程池處于SHUTDOWN狀態時,阻塞隊列中的任務被執行完了,且線程池中沒有正在執行的任務了,狀態會由SHUTDOWN變為TIDYING。當線程處于STOP狀態時,線程池中沒有正在執行的任務時則會由STOP變為TIDYING。
- TERMINATED 線程終止狀態。處于TIDYING狀態的線程執行terminated()后進入TERMINATED狀態。
根據上述線程池生命周期狀態的描述,可以畫出如下所示的線程池生命周期狀態流程示意圖。
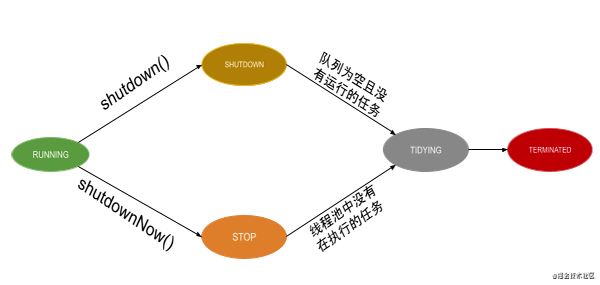
線程池的工作機制
ThreadPoolExecutor中的參數
上一小節中,我們使用ThreadPoolExecutor的構造方法來創建了一個線程池。其實在ThreadPoolExecutor中有多個構造方法,但是最終都調用到了下邊代碼中的這一個構造方法:
- public class ThreadPoolExecutor extends AbstractExecutorService {
- public ThreadPoolExecutor(int corePoolSize,
- int maximumPoolSize,
- long keepAliveTime,
- TimeUnit unit,
- BlockingQueue<Runnable> workQueue,
- ThreadFactory threadFactory,
- RejectedExecutionHandler handler) {
- // ...省略校驗相關代碼
- this.corePoolSize = corePoolSize;
- this.maximumPoolSize = maximumPoolSize;
- this.workQueue = workQueue;
- this.keepAliveTime = unit.toNanos(keepAliveTime);
- this.threadFactory = threadFactory;
- this.handler = handler;
- }
- // ...
- }
這個構造方法中有7個參數之多,我們逐個來看每個參數所代表的含義:
- corePoolSize 表示線程池的核心線程數。當有任務提交到線程池時,如果線程池中的線程數小于corePoolSize,那么則直接創建新的線程來執行任務。
- workQueue 任務隊列,它是一個阻塞隊列,用于存儲來不及執行的任務的隊列。當有任務提交到線程池的時候,如果線程池中的線程數大于等于corePoolSize,那么這個任務則會先被放到這個隊列中,等待執行。
- maximumPoolSize 表示線程池支持的最大線程數量。當一個任務提交到線程池時,線程池中的線程數大于corePoolSize,并且workQueue已滿,那么則會創建新的線程執行任務,但是線程數要小于等于maximumPoolSize。
- keepAliveTime 非核心線程空閑時保持存活的時間。非核心線程即workQueue滿了之后,再提交任務時創建的線程,因為這些線程不是核心線程,所以它空閑時間超過keepAliveTime后則會被回收。
- unit 非核心線程空閑時保持存活的時間的單位
- threadFactory 創建線程的工廠,可以在這里統一處理創建線程的屬性
- handler 拒絕策略,當線程池中的線程達到maximumPoolSize線程數后且workQueue已滿的情況下,再向線程池提交任務則執行對應的拒絕策略
線程池工作流程
線程池提交任務是從execute方法開始的,我們可以從execute方法來分析線程池的工作流程。
(1)當execute方法提交一個任務時,如果線程池中線程數小于corePoolSize,那么不管線程池中是否有空閑的線程,都會創建一個新的線程來執行任務。
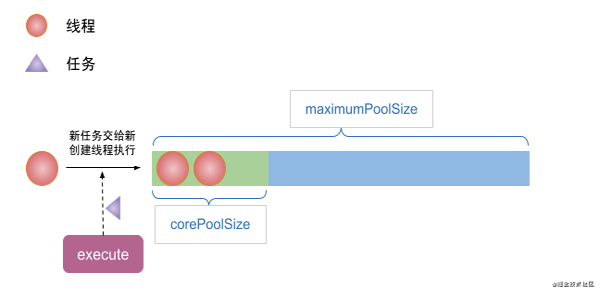
(2)當execute方法提交一個任務時,線程池中的線程數已經達到了corePoolSize,且此時沒有空閑的線程,那么則會將任務存儲到workQueue中。
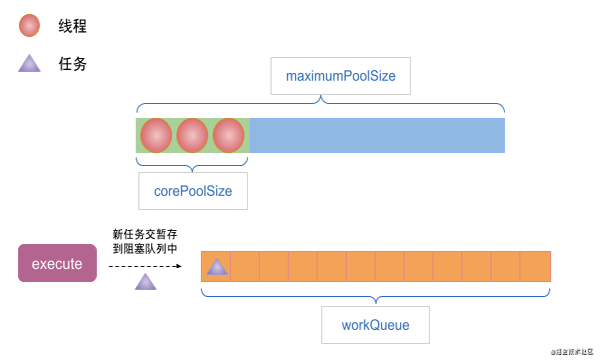
(3)如果execute提交任務時線程池中的線程數已經到達了corePoolSize,并且workQueue已滿,那么則會創建新的線程來執行任務,但總線程數應該小于maximumPoolSize。
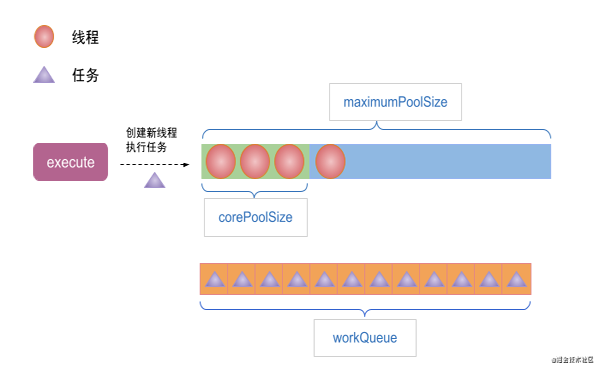
(4)如果線程池中的線程執行完了當前的任務,則會嘗試從workQueue中取出第一個任務來執行。如果workQueue為空則會阻塞線程。
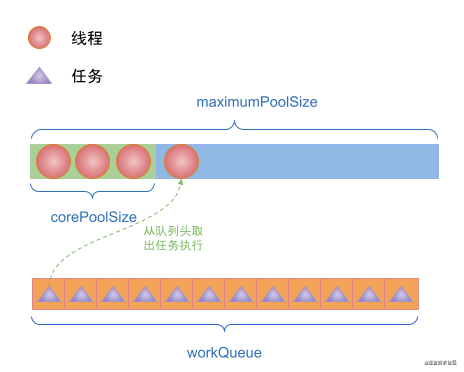
(5)如果execute提交任務時,線程池中的線程數達到了maximumPoolSize,且workQueue已滿,此時會執行拒絕策略來拒絕接受任務。
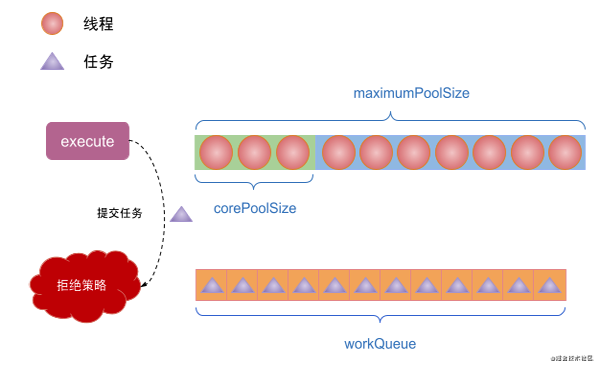
(6)如果線程池中的線程數超過了corePoolSize,那么空閑時間超過keepAliveTime的線程會被銷毀,但程池中線程個數會保持為corePoolSize。
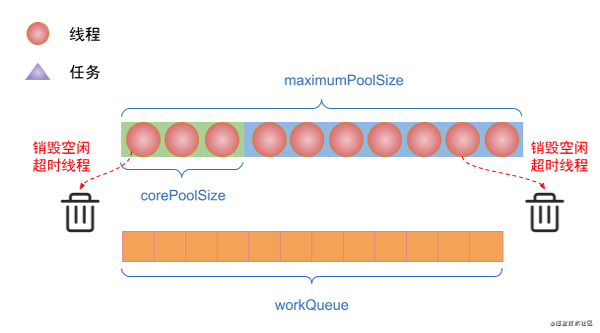
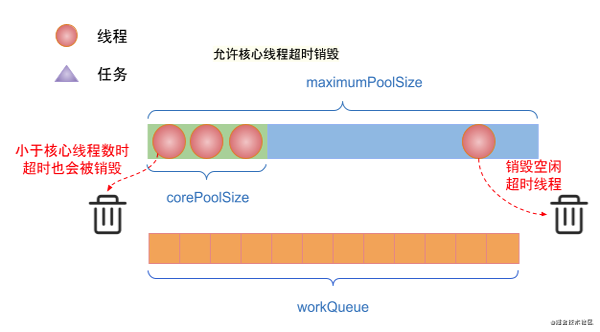
(7)如果線程池存在空閑的線程,并且設置了allowCoreThreadTimeOut為true。那么空閑時間超過keepAliveTime的線程都會被銷毀。
線程池的拒絕策略
如果線程池中的線程數達到了maximumPoolSize,并且workQueue隊列存儲滿的情況下,線程池會執行對應的拒絕策略。在JDK中提供了RejectedExecutionHandler接口來執行拒絕操作。實現RejectedExecutionHandler的類有四個,對應了四種拒絕策略。分別如下:DiscardPolicy 當提交任務到線程池中被拒絕時,線程池會丟棄這個被拒絕的任務
- DiscardOldestPolicy 當提交任務到線程池中被拒絕時,線程池會丟棄等待隊列中最老的任務。
- CallerRunsPolicy 當提交任務到線程池中被拒絕時,會在線程池當前正在運行的Thread線程中處理被拒絕額任務。即哪個線程提交的任務哪個線程去執行。
- AbortPolicy 當提交任務到線程池中被拒絕時,直接拋出RejectedExecutionException異常。
線程池源碼分析
從上一章對線程池的工作流程解讀來看,線程池的原理似乎并沒有很難。但是開篇時我說過想要讀懂線程池的源碼并不容,主要原因是線程池內部運用到了大量并發相關知識,另外還與線程池中用到的位運算有關。
線程池中的位運算(了解內容)
在向線程池提交任務時有兩個比較中要的參數會決定任務的去向,這兩個參數分別是線程池的狀態和線程池中的線程數。在ThreadPoolExecutor內部使用了一個AtomicInteger類型的整數ctl來表示這兩個參數,代碼如下:
- public class ThreadPoolExecutor extends AbstractExecutorService {
- // Integer.SIZE = 32.所以 COUNT_BITS= 29
- private static final int COUNT_BITS = Integer.SIZE - 3;
- // 00001111 11111111 11111111 11111111 這個值可以表示線程池的最大線程容量
- private static final int COUNT_MASK = (1 << COUNT_BITS) - 1;
- // 將-1左移29位得到RUNNING狀態的值
- private static final int RUNNING = -1 << COUNT_BITS;
- // 線程池運行狀態和線程數
- private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));
- private static int ctlOf(int rs, int wc) { return rs | wc; }
- // ...
- }
因為涉及多線程的操作,這里為了保證原子性,ctl參數使用了AtomicInteger類型,并且通過ctlOf方法來計算出了ctl的初始值。如果你不了解位運算大概很難理解上述代碼的用意。
我們知道,int類型在Java中占用4byte的內存,一個byte占用8bit,所以Java中的int類型共占用32bit。對于這個32bit,我們可以進行高低位的拆分。做Android開發的同學應該都了解View測量流程中的MeasureSpec參數,這個參數將32bit的int拆分成了高2位和低30位,分別表示View的測量模式和測量值。而這里的ctl與MeasureSpec類似,ctl將32位的int拆分成了高3位和低29位,分別表示線程池的運行狀態和線程池中的線程個數。
下面我們通過位運算來驗證一下ctl是如何工作的,當然,如果你不理解這個位運算的過程對理解線程池的源碼影響并不大,所以對以下驗證內容不感興趣的同學可以直接略過。
可以看到上述代碼中RUNNING的值為-1左移29位,我們知道在計算機中**負數是以其絕對值的補碼來表示的,而補碼是由反碼加1得到。**因此-1在計算機中存儲形式為1的反碼+1。
- 1的原碼:00000000 00000000 00000000 00000001
- +
- 1的反碼:11111111 11111111 11111111 11111110
- ---------------------------------------
- -1存儲: 11111111 11111111 11111111 11111111
接下來對-1左移29位可以得到RUNNING的值為:
- // 高三位表示線程狀態,即高三位為111表示RUNNING
- 11100000 00000000 00000000 00000000
而AtomicInteger初始線程數量是0,因此ctlOf方法中的“|”運算如下:
- RUNNING: 11100000 00000000 00000000 00000000
- |
- 線程數為0: 00000000 00000000 00000000 00000000
- ---------------------------------------
- 得到ctl: 11100000 00000000 00000000 00000000
通過RUNNING|0(線程數)即可得到ctl的初始值。同時還可以通過以下方法將ctl拆解成運行狀態和線程數:
- // 00001111 11111111 11111111 11111111
- private static final int COUNT_MASK = (1 << COUNT_BITS) - 1;
- // 獲取線程池運行狀態
- private static int runStateOf(int c) { return c & ~COUNT_MASK; }
- // 獲取線程池中的線程數
- private static int workerCountOf(int c) { return c & COUNT_MASK; }
假設此時線程池為RUNNING狀態,且線程數為0,驗證一下runStateOf是如何得到線程池的運行狀態的:
- COUNT_MASK: 00001111 11111111 11111111 11111111
- ~COUNT_MASK: 11110000 00000000 00000000 00000000
- &
- ctl: 11100000 00000000 00000000 00000000
- ----------------------------------------
- RUNNING: 11100000 00000000 00000000 00000000
如果不理解上邊的驗證流程沒有關系,只要知道通過runStateOf方法可以得到線程池的運行狀態,通過workerCountOf可以得到線程池中的線程數即可。
接下來我們進入線程池的源碼的源碼分析環節。
ThreadPoolExecutor的execute
向線程池提交任務的方法是execute方法,execute方法是ThreadPoolExecutor的核心方法,以此方法為入口來進行剖析,execute方法的代碼如下:
- public void execute(Runnable command) {
- if (command == null)
- throw new NullPointerException();
- // 獲取ctl的值
- int c = ctl.get();
- // 1.線程數小于corePoolSize
- if (workerCountOf(c) < corePoolSize) {
- // 線程池中線程數小于核心線程數,則嘗試創建核心線程執行任務
- if (addWorker(command, true))
- return;
- c = ctl.get();
- }
- // 2.到此處說明線程池中線程數大于核心線程數或者創建線程失敗
- if (isRunning(c) && workQueue.offer(command)) {
- // 如果線程是運行狀態并且可以使用offer將任務加入阻塞隊列未滿,offer是非阻塞操作。
- int recheck = ctl.get();
- // 重新檢查線程池狀態,因為上次檢測后線程池狀態可能發生改變,如果非運行狀態就移除任務并執行拒絕策略
- if (! isRunning(recheck) && remove(command))
- reject(command);
- // 如果是運行狀態,并且線程數是0,則創建線程
- else if (workerCountOf(recheck) == 0)
- // 線程數是0,則創建非核心線程,且不指定首次執行任務,這里的第二個參數其實沒有實際意義
- addWorker(null, false);
- }
- // 3.阻塞隊列已滿,創建非核心線程執行任務
- else if (!addWorker(command, false))
- // 如果失敗,則執行拒絕策略
- reject(command);
- }
execute方法中的邏輯可以分為三部分:
- 1.如果線程池中的線程數小于核心線程,則直接調用addWorker方法創建新線程來執行任務。
- 2.如果線程池中的線程數大于核心線程數,則將任務添加到阻塞隊列中,接著再次檢驗線程池的運行狀態,因為上次檢測過之后線程池狀態有可能發生了變化,如果線程池關閉了,那么移除任務,執行拒絕策略。如果線程依然是運行狀態,但是線程池中沒有線程,那么就調用addWorker方法創建線程,注意此時傳入任務參數是null,即不指定執行任務,因為任務已經加入了阻塞隊列。創建完線程后從阻塞隊列中取出任務執行。
- 3.如果第2步將任務添加到阻塞隊列失敗了,說明阻塞隊列任務已滿,那么則會執行第三步,即創建非核心線程來執行任務,如果非核心線程創建失敗那么就執行拒絕策略。
可以看到,代碼的執行邏輯和我們在第二章中分析的線程池的工作流程是一樣的。
接下來看下execute方法中創建線程的方法addWoker,addWoker方法承擔了核心線程和非核心線程的創建,通過一個boolean參數core來區分是創建核心線程還是非核心線程。先來看addWorker方法前半部分的代碼:
- // 返回值表示是否成功創建了線程
- private boolean addWorker(Runnable firstTask, boolean core) {
- // 這里做了一個retry標記,相當于goto.
- retry:
- for (int c = ctl.get();;) {
- // Check if queue empty only if necessary.
- if (runStateAtLeast(c, SHUTDOWN)
- && (runStateAtLeast(c, STOP)
- || firstTask != null
- || workQueue.isEmpty()))
- return false;
- for (;;) {
- // 根據core來確定創建最大線程數,超過最大值則創建線程失敗,注意這里的最大值可能有s三個corePoolSize、maximumPoolSize和線程池線程的最大容量
- if (workerCountOf(c)
- >= ((core ? corePoolSize : maximumPoolSize) & COUNT_MASK))
- return false;
- // 通過CAS來將線程數+1,如果成功則跳出循環,執行下邊邏輯
- if (compareAndIncrementWorkerCount(c))
- break retry;
- c = ctl.get(); // Re-read ctl
- // 線程池的狀態發生了改變,退回retry重新執行
- if (runStateAtLeast(c, SHUTDOWN))
- continue retry;
- }
- }
- // ...省略后半部分
- return workerStarted;
- }
這部分代碼會通過是否創建核心線程來確定線程池中線程數的值,如果是創建核心線程,那么最大值不能超過corePoolSize,如果是創建非核心線程那么線程數不能超過maximumPoolSize,另外無論是創建核心線程還是非核心線程,最大線程數都不能超過線程池允許的最大線程數COUNT_MASK(有可能設置的maximumPoolSize大于COUNT_MASK)。如果線程數大于最大值就返回false,創建線程失敗。
接下來通過CAS將線程數加1,如果成功那么就break retry結束無限循環,如果CAS失敗了則就continue retry從新開始for循環,注意這里的retry不是Java的關鍵字,是一個可以任意命名的字符。
接下來,如果能繼續向下執行則開始執行創建線程并執行任務的工作了,看下addWorker方法的后半部分代碼:
- private boolean addWorker(Runnable firstTask, boolean core) {
- // ...省略前半部分
- boolean workerStarted = false;
- boolean workerAdded = false;
- Worker w = null;
- try {
- // 實例化一個Worker,內部封裝了線程
- w = new Worker(firstTask);
- // 取出新建的線程
- final Thread t = w.thread;
- if (t != null) {
- // 這里使用ReentrantLock加鎖保證線程安全
- final ReentrantLock mainLock = this.mainLock;
- mainLock.lock();
- try {
- int c = ctl.get();
- // 拿到鎖湖重新檢查線程池狀態,只有處于RUNNING狀態或者處于SHUTDOWN并且firstTask==null時候才會創建線程
- if (isRunning(c) ||
- (runStateLessThan(c, STOP) && firstTask == null)) {
- // 線程不是處于NEW狀態,說明線程已經啟動,拋出異常
- if (t.getState() != Thread.State.NEW)
- throw new IllegalThreadStateException();
- // 將線程加入線程隊列,這里的worker是一個HashSet
- workers.add(w);
- workerAdded = true;
- int s = workers.size();
- if (s > largestPoolSize)
- largestPoolSize = s;
- }
- } finally {
- mainLock.unlock();
- }
- if (workerAdded) {
- // 開啟線程執行任務
- t.start();
- workerStarted = true;
- }
- }
- } finally {
- if (! workerStarted)
- addWorkerFailed(w);
- }
- return workerStarted;
- }
這部分邏輯其實比較容易理解,就是創建Worker并開啟線程執行任務的過程,Worker是對線程的封裝,創建的worker會被添加到ThreadPoolExecutor中的HashSet中。也就是線程池中的線程都維護在這個名為workers的HashSet中并被ThreadPoolExecutor所管理,HashSet中的線程可能處于正在工作的狀態,也可能處于空閑狀態,一旦達到指定的空閑時間,則會根據條件進行回收線程。
我們知道,線程調用start后就會開始執行線程的邏輯代碼,執行完后線程的生命周期就結束了,那么線程池是如何保證Worker執行完任務后仍然不結束的呢?當線程空閑超時或者關閉線程池又是怎樣進行線程回收的呢?這個實現邏輯其實就在Worker中。看下Worker的代碼:
- private final class Worker
- extends AbstractQueuedSynchronizer
- implements Runnable
- {
- // 執行任務的線程
- final Thread thread;
- // 初始化Worker時傳進來的任務,可能為null,如果不空,則創建和立即執行這個task,對應核心線程創建的情況
- Runnable firstTask;
- Worker(Runnable firstTask) {
- // 初始化時設置setate為-1
- setState(-1); // inhibit interrupts until runWorker
- this.firstTask = firstTask;
- // 通過線程工程創建線程
- this.thread = getThreadFactory().newThread(this);
- }
- // 線程的真正執行邏輯
- public void run() {
- runWorker(this);
- }
- // 判斷線程是否是獨占狀態,如果不是意味著線程處于空閑狀態
- protected boolean isHeldExclusively() {
- return getState() != 0;
- }
- // 獲取鎖
- protected boolean tryAcquire(int unused) {
- if (compareAndSetState(0, 1)) {
- setExclusiveOwnerThread(Thread.currentThread());
- return true;
- }
- return false;
- }
- // 釋放鎖
- protected boolean tryRelease(int unused) {
- setExclusiveOwnerThread(null);
- setState(0);
- return true;
- }
- // ...
- }
Worker是位于ThreadPoolExecutor中的一個內部類,它繼承了AQS,使用AQS來實現了獨占鎖的功能,但是并沒支持可重入。這里使用不可重入的特性來表示線程的執行狀態,即可以通過isHeldExclusively方法來判斷,如果是獨占狀態,說明線程正在執行任務,如果非獨占狀態,說明線程處于空閑狀態。關于AQS我們前邊文章中已經詳細分析過了,不了解AQS的可以翻看前邊ReentrantLock的文章。
另外,Worker還實現了Runnable接口,因此它的執行邏輯就是在run方法中,run方法調用的是線程池中的runWorker(this)方法。任務的執行邏輯就在runWorker方法中,它的代碼如下:
- final void runWorker(Worker w) {
- Thread wt = Thread.currentThread();
- // 取出Worker中的任務,可能為空
- Runnable task = w.firstTask;
- w.firstTask = null;
- w.unlock(); // allow interrupts
- boolean completedAbruptly = true;
- try {
- // task不為null或者阻塞隊列中有任務,通過循環不斷的從阻塞隊列中取出任務執行
- while (task != null || (task = getTask()) != null) {
- w.lock();
- // ...
- try {
- // 任務執行前的hook點
- beforeExecute(wt, task);
- try {
- // 執行任務
- task.run();
- // 任務執行后的hook點
- afterExecute(task, null);
- } catch (Throwable ex) {
- afterExecute(task, ex);
- throw ex;
- }
- } finally {
- task = null;
- w.completedTasks++;
- w.unlock();
- }
- }
- completedAbruptly = false;
- } finally {
- // 超時沒有取到任務,則回收空閑超時的線程
- processWorkerExit(w, completedAbruptly);
- }
- }
可以看到,runWorker的核心邏輯就是不斷通過getTask方法從阻塞隊列中獲取任務并執行.通過這樣的方式實現了線程的復用,避免了創建線程。這里要注意的是這里是一個“生產者-消費者”模式,getTask是從阻塞隊列中取任務,所以如果阻塞隊列中沒有任務的時候就會處于阻塞狀態。
getTask中通過判斷是否要回收線程而設置了等待超時時間,如果阻塞隊列中一直沒有任務,那么在等待keepAliveTime時間后會拋出異常。最終會走到上述代碼的finally方法中,意味著有線程空閑時間超過了keepAliveTime時間,那么調用processWorkerExit方法移除Worker。processWorkerExit方法中沒有復雜難以理解的邏輯,這里就不再貼代碼了。我們重點看下getTask中是如何處理的,代碼如下:
- private Runnable getTask() {
- boolean timedOut = false; // Did the last poll() time out?
- for (;;) {
- int c = ctl.get();
- // ...
- // Flag1. 如果配置了allowCoreThreadTimeOut==true或者線程池中的線程數大于核心線程數,則timed為true,表示開啟指定線程超時后被回收
- boolean timed = allowCoreThreadTimeOut || wc > corePoolSize;
- // ...
- try {
- // Flag2. 取出阻塞隊列中的任務,注意如果timed為true,則會調用阻塞隊列的poll方法,并設置超時時間為keepAliveTime,如果超時沒有取到任務則會拋出異常。
- Runnable r = timed ?
- workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS) :
- workQueue.take();
- if (r != null)
- return r;
- timedOut = true;
- } catch (InterruptedException retry) {
- timedOut = false;
- }
- }
- }
重點看getTask是如何處理空閑超時的邏輯的。我們知道,回收線程的條件是線程大于核心線程數或者配置了allowCoreThreadTimeOut為true,當線程空閑超時的情況下就會回收線程。上述代碼在Flag1處先判斷了如果線程池中的線程數大于核心線程數,或者開啟了allowCoreThreadTimeOut,那么就需要開啟線程空閑超時回收。
所有在Flag2處,timed為true的情況下調用了阻塞隊列的poll方法,并傳入了超時時間為keepAliveTime,如果在keepAliveTime時間內,阻塞隊列一直為null那么久會拋出異常,結束runWorker的循環。進而執行runWorker方法中回收線程的操作。
這里需要我們理解阻塞隊列poll方法的使用,poll方法接受一個時間參數,是一個阻塞操作,在給定的時間內沒有獲取到數據就會拋出異常。其實說白了,阻塞隊列就是一個使用ReentrantLock實現的“生產者-消費者”模式,我們在深入理解Java線程的等待與喚醒機制(二)這篇文章中使用ReentrantLock實現“生產者-消費者”模型其實就是一個簡單的阻塞隊列,與JDK中的BlockingQueue實現機制類似。感興趣的同學可以自己查看ArrayBlockingQueue等阻塞隊列的實現,限于文章篇幅,這里就不再贅述了。
ThreadPoolExecutor的拒絕策略
上一小節中我們多次提到線程池的拒絕策略,它是在reject方法中實現的。實現代碼也非常簡單,代碼如下:
- final void reject(Runnable command) {
- handler.rejectedExecution(command, this);
- }
通過調用handler的rejectedExecution方法實現。這里其實就是運用了策略模式,handler是一個RejectedExecutionHandler類型的成員變量,RejectedExecutionHandler是一個接口,只有一個rejectedExecution方法。在實例化線程池時構造方法中傳入對應的拒絕策略實例即可。前文已經提到了Java提供的幾種默認實現分別為DiscardPolicy、DiscardOldestPolicy、CallerRunsPolicy以及AbortPolicy。
以AbortPolicy直接拋出異常為例,來看下代碼實現:
- public static class AbortPolicy implements RejectedExecutionHandler {
- public AbortPolicy() { }
- public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
- throw new RejectedExecutionException("Task " + r.toString() +
- " rejected from " +
- e.toString());
- }
可以看到直接在rejectedExecution方法中拋出了RejectedExecutionException來拒絕任務。其他的幾個策略實現也都比較簡單,有興趣可以自己查閱代碼。
ThreadPoolExecutor的shutdown
調用shutdown方法后,會將線程池標記為SHUTDOWN狀態,上邊execute的源碼可以看出,只有線程池是RUNNING狀態才接受任務,因此被標記位SHUTDOWN后,再提交任務會被線程池拒絕。shutdown的代碼如下:
- public void shutdown() {
- final ReentrantLock mainLock = this.mainLock;
- mainLock.lock();
- try {
- //檢查是否可以關閉線程
- checkShutdownAccess();
- // 將線程池狀態置為SHUTDOWN狀態
- advanceRunState(SHUTDOWN);
- // 嘗試中斷空閑線程
- interruptIdleWorkers();
- // 空方法,線程池關閉的hook點
- onShutdown();
- } finally {
- mainLock.unlock();
- }
- tryTerminate();
- }
- private void interruptIdleWorkers() {
- interruptIdleWorkers(false);
- }
修改線程池為SHUTDOWN狀態后,會調用interruptIdleWorkers去中斷空閑線程線程,具體實現邏輯是在interruptIdleWorkers(boolean onlyOne)方法中,如下:
- private void interruptIdleWorkers(boolean onlyOne) {
- final ReentrantLock mainLock = this.mainLock;
- mainLock.lock();
- try {
- for (Worker w : workers) {
- Thread t = w.thread;
- // 嘗試tryLock獲取鎖,如果拿鎖成功說明線程是空閑狀態
- if (!t.isInterrupted() && w.tryLock()) {
- try {
- // 中斷線程
- t.interrupt();
- } catch (SecurityException ignore) {
- } finally {
- w.unlock();
- }
- }
- if (onlyOne)
- break;
- }
- } finally {
- mainLock.unlock();
- }
- }
shutdown的邏輯比較簡單,里邊做了兩件比較重要的事情,即先將線程池狀態修改為SHUTDOWN,接著遍歷所有Worker,將空閑的Worker進行中斷。
總結
本文深入的探究了線程池的工作流程和實現原理。就線程池的工作流程而言其實并不難以理解。但是在分析線程池的源碼時,如果沒有很好的并發基礎的話,大概率是難以讀懂線程池的源碼的。因為線程池內部使用了大量并發知識,對任何一點用到的并發知識認識不到位都會造成理解偏差。寫這篇文章參看了很多的其他線程池的相關文章,幾乎沒有找到一篇能夠剖析清楚線程池源碼的文章。歸根結底還是沒能系統的理解Atomic、Lock與AQS、CAS、阻塞隊列等并發相關知識。






















