













使用 Python 進行數(shù)據(jù)預(yù)處理的標(biāo)準(zhǔn)化
標(biāo)準(zhǔn)化和規(guī)范化是機器學(xué)習(xí)和深度學(xué)習(xí)項目中大量使用的數(shù)據(jù)預(yù)處理技術(shù)之一。
這些技術(shù)的主要作用
- 以類似的格式縮放所有數(shù)據(jù),使模型的學(xué)習(xí)過程變得容易。
- 數(shù)據(jù)中的奇數(shù)值被縮放或歸一化并且表現(xiàn)得像數(shù)據(jù)的一部分。
我們將通過 Python 示例深入討論這兩個概念。
標(biāo)準(zhǔn)化
數(shù)據(jù)的基本縮放是使其成為標(biāo)準(zhǔn),以便所有值都在共同范圍內(nèi)。 在標(biāo)準(zhǔn)化中,數(shù)據(jù)的均值和方差分別為零和一。 它總是試圖使數(shù)據(jù)呈正態(tài)分布。
標(biāo)準(zhǔn)化公式如下所示:
z =(列的值 - 平均值)/標(biāo)準(zhǔn)偏差
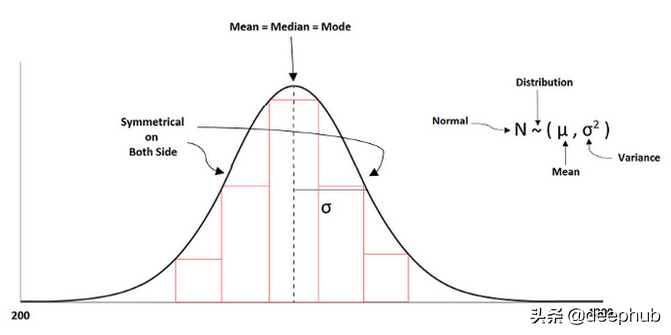
機器學(xué)習(xí)中的一些算法試圖讓數(shù)據(jù)具有正態(tài)分布。但是,如果一個特征有更多的方差,而其他特征有低或單位方差,那么模型的學(xué)習(xí)將是不正確的,因為從一個特征到另一個特征的方差是有差異的。
正如我們上面討論的,標(biāo)準(zhǔn)縮放的范圍是“0”均值和“1”單位方差。
我們?nèi)绾问褂脴?biāo)準(zhǔn)縮放?
要使用標(biāo)準(zhǔn)伸縮,我們需要從預(yù)處理類中導(dǎo)入它,如下所示:
- from sklearn import preprocessing
- scaler = preprocessing.StandardScaler()
使用標(biāo)準(zhǔn)縮放的正確步驟是什么?
我們可以在 train-test split 之后使用標(biāo)準(zhǔn)縮放,因為如果我們在發(fā)生數(shù)據(jù)泄漏問題之前這樣做,可能會導(dǎo)致模型不太可靠。 如果我們在拆分之前進行縮放,那么從訓(xùn)練中學(xué)習(xí)的過程也可以在測試集上完成,這是我們不想要的。
讓我們在sklearn庫的幫助下看看拆分過程
- from sklearn.model_selection import train_test_split
- X_train, X_test, y_train, y_test = train_test_split(x,
- y, train_size = 0.20, random_state = 42)
在此之后,我們可以使用標(biāo)準(zhǔn)縮放
- from sklearn.preprocessing import StandardScaler
- sc = StandardScaler()
- X_train = sc.fit_transform(X_train)
- X_test = sc.transform(X_test)
讓我們舉一個 python 例子。
- from sklearn import preprocessing
- import numpy as np
- #creating a training data
- X_train = np.array([[ 4., -3., 2.],
- [ 2., 2., 0.],
- [ 0., -6., 7.]])
- #fit the training data
- scaler = preprocessing.StandardScaler().fit(X_train)
- scaler
- #output:
- StandardScaler()
現(xiàn)在,我們將檢查訓(xùn)練數(shù)據(jù)中每個特征的均值和縮放比例。
- scaler.mean_
- #output:
- array([ 2., -2.33333333, 3.])
- scaler.scale_
- #output:
- array([1.63299316, 3.29983165, 2.94392029])
scale_屬性找出特征之間的相對尺度,得到一個標(biāo)準(zhǔn)尺度,即零均值和單位方差。均值屬性用來找出每個特征的均值。
現(xiàn)在,我們將轉(zhuǎn)換縮放后的數(shù)據(jù)
- X_scaled = scaler.transform(X_train)
- X_scaled
- #output:
- array([[ 1.22474487, -0.20203051, -0.33968311],
- [ 0. , 1.31319831, -1.01904933],
- [-1.22474487, -1.1111678 , 1.35873244]])
為了檢查特征的零均值和單位方差,我們將找到均值和標(biāo)準(zhǔn)差。
- X_scaled.mean(axis=0)
- #output:
- array([0., 0., 0.])
- X_scaled.std(axis=0)
- #output:
- array([1., 1., 1.])
我們還可以在 MinMaxScaler 和 MaxAbsScaler 的幫助下進行范圍縮放。
有時,我們在數(shù)據(jù)中存在影響算法建模的異常值,并且標(biāo)準(zhǔn)縮放器受到異常值的影響,其他方法如 min-max 和 max-abs 縮放器使數(shù)據(jù)在一定范圍內(nèi)。
MinMaxScaler
MinMaxScaler 是另一種在 [0,1] 范圍內(nèi)縮放數(shù)據(jù)的方法。 它使數(shù)據(jù)保持原始形狀并保留有價值的信息,而受異常值的影響較小。
python示例如下所示:
- from sklearn import preprocessing
- import numpy as np
- #creating a training data
- X_train = np.array([[ 4., -3., 2.],
- [ 2., 2., 0.],
- [ 0., -6., 7.]])
- min_max_scaler = preprocessing.MinMaxScaler()
- X_train_minmax = min_max_scaler.fit_transform(X_train)
- X_train_minmax
- #output:
- array([[1. , 0.375 , 0.28571429],
- [0.5 , 1. , 0. ],
- [0. , 0. , 1. ]])
我們可以在使用 MinMaxScaler 縮放后看到“0”到“1”范圍內(nèi)的數(shù)據(jù)。
MaxAbsScaler
這是另一種縮放方法,其中數(shù)據(jù)在 [-1,1] 的范圍內(nèi)。 這種縮放的好處是它不會移動或居中數(shù)據(jù)并保持?jǐn)?shù)據(jù)的稀疏性。
python示例如下所示:
- from sklearn import preprocessing
- import numpy as np
- #creating a training data
- X_train = np.array([[ 4., -3., 2.],
- [ 2., 2., 0.],
- [ 0., -6., 7.]])
- max_abs_scaler = preprocessing.MaxAbsScaler()
- X_train_maxabs = max_abs_scaler.fit_transform(X_train)
- X_train_maxabs
- #output:
- array([[ 1. , -0.5 , 0.28571429],
- [ 0.5 , 0.33333333, 0. ],
- [ 0. , -1. , 1. ]])
我們可以在使用 MaxAbsScaler 縮放后看到“-1”到“1”范圍內(nèi)的數(shù)據(jù)。
總結(jié)
數(shù)據(jù)的縮放是機器學(xué)習(xí)或深度學(xué)習(xí)的一個非常重要的部分。 在本文中,MaxAbsScaler 在稀疏數(shù)據(jù)中很有用,而另一方面,標(biāo)準(zhǔn)縮放也可以用于稀疏數(shù)據(jù),但也會由于過多的內(nèi)存分配而給出值錯誤。




















