













李飛飛團隊提出零樣本泛化的自專家克隆技術,性能超越SOTA
沒錯!又是李飛飛!
上次報道李飛飛是因為她為學界爭取到了亞馬遜谷歌云數據中心。
而這次,她和研究團隊帶著一篇論文向我們走來!
走在隊伍前面的,是來自斯坦福大學的博士,李飛飛的門生!
(不好意思最近重溫了一下08奧運開幕式……)
先來看看李飛飛團隊這次在arXiv上發表了的論文題目:

SECANT:用于視覺策略零樣本泛化的自專家克隆
廢話少說,給大家介紹一下這篇論文的大致內容。
論文介紹
簡要介紹
強化學習中的泛化(generalization),是指通過不斷跟環境交互,產生出一種網絡的記憶性。
這個網絡能夠根據環境中特定的信號完成相應的動作,經過訓練的agent能夠記住在什么狀態下要做什么,還能通過識別狀態的細微差別來采取不同的動作。
再通俗一點,就是在未見過的測試數據上也能夠進行預測。
因此,提升模型的泛化是機器學習領域中的一個重要研究。
特別是視覺強化學習方面,泛化很容易被高維觀察空間中,一些無關痛癢的因素分散了注意力。
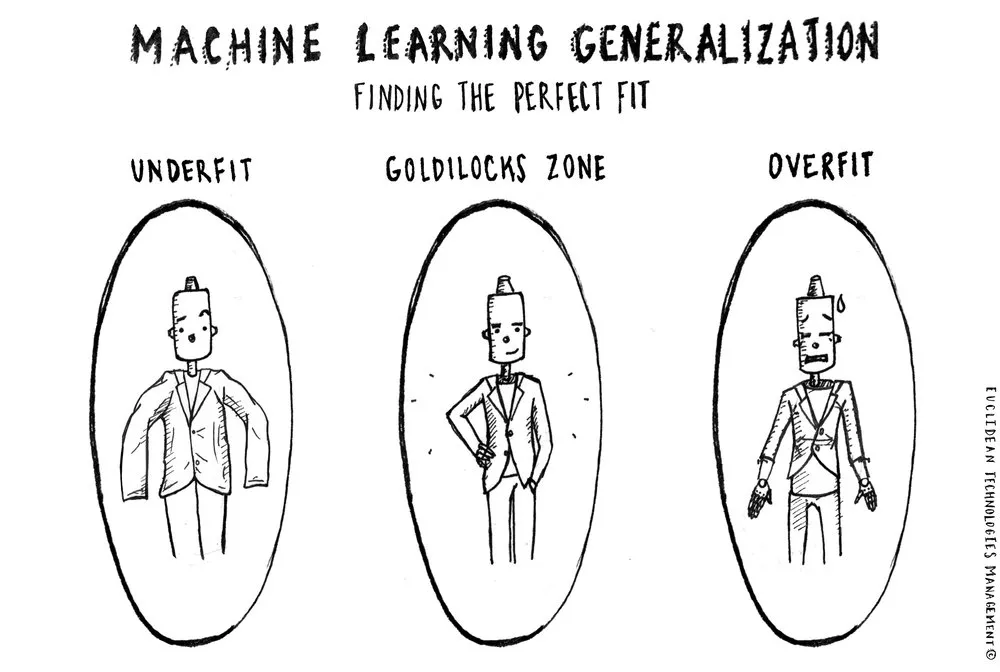
機器學習中的泛化:欠擬合、擬合、過度擬合
針對這個問題,團隊通過魯棒性策略學習,對具有大分布偏移的未見視覺環境進行零樣本泛化。
因此,團隊提出「SECANT」模型,一種可以適應新測試環境的自專家克隆方法(Self Expert Cloning for Adaptation to Novel Test-environments)。
這個方法能夠在兩個階段利用圖像增廣,分離魯棒性表征和策略優化。
首先,專家策略通過弱增廣從頭開始進行強化學習的訓練。
而學生網絡就是通過強增廣的監督學習來模仿專家策略,其表征與專家策略相比,對視覺變化更具魯棒性。
實驗表明,SECANT在DMControl(Deepmind Control)、自動駕駛、機器人操作和室內物體導航這四個具有挑戰性的領域中,在零樣本泛化方面超過了之前的SOTA模型,分別實現了26.5%、337.8%、47.7%和15.8%的提升。
主要貢獻
- 提出了SECANT模型,可以依次解決策略學習和魯棒性表征學習問題,從而實現了對未見過的視覺環境的強大零樣本泛化性能。
- 在自動駕駛、機器人操作和室內物體導航四個領域中,設計并制定了一套多樣化的基準測試。除了DMControl外,其它3種環境都具有代表實際應用程序的測試時視覺外觀漂移。
- 證明了SECANT在以上4個領域中,大多數任務都能達到SOTA。
SECANT框架
SECANT的主要目標是發展自我專家克隆技術,通過這種技術可以實現零樣本生成不一樣的視覺樣本。
作者研究的SECANT訓練模型可以分解為兩步,代碼已公開。
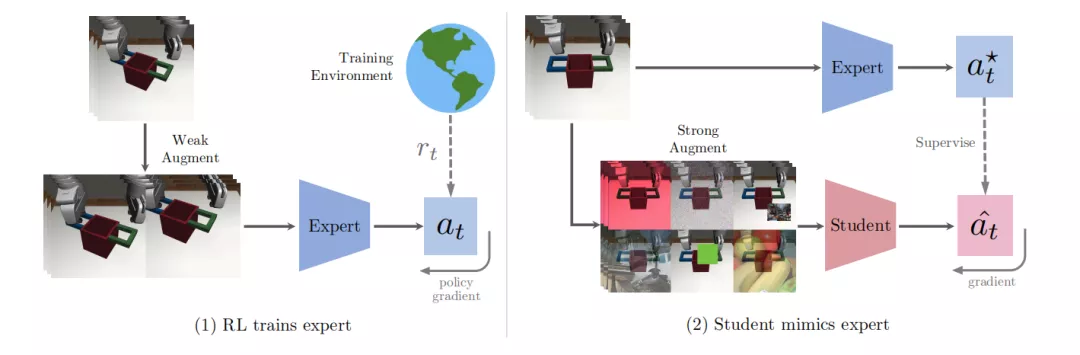
專家策略
第一步,作者在原始環境中通過弱增廣訓練了一套高性能的專家策略。在視覺連續控制任務中,這套策略通過前饋深度卷積網絡進行參數化,然后將觀察到的圖像轉化為d維連續動作向量。
在實際應用中,作者采用了幀疊加技術,在時間信息維度上,連接T個連續圖像進行觀測。然后通過語義保持圖像變換來生成數據擴增的算子。采用隨機裁剪圖像的方法作為默認的弱增廣方法來訓練專家策略。
這套專家策略可以通過任何標準的RL算法進行優化。作者選擇了Soft Actor-Critic (SAC),因為它在連續控制任務中被廣泛采用。然后采用梯度下降法對專家參數進行優化,使專家參數最小化。
學生策略
在第二階段,作者訓練一個學生網絡來預測專家策略采取的最優行動,在同樣的觀察的條件下,通過劇烈變化的圖像來進行測試。在這個階段不需要進一步接觸獎勵信號。
從形式上來看,學生策略也是一個深度卷積神經網絡,但與專家策略不同的是它有著不同的架構。本質上來說,學生策略是根據DAgger模仿流程,從專家策略中延伸而來的。
作者使用專家策略來收集軌跡的初始數據集D。接下來,在每一次迭代中,選擇一個強擴增算子,并將其應用于采樣的一批觀測數據。
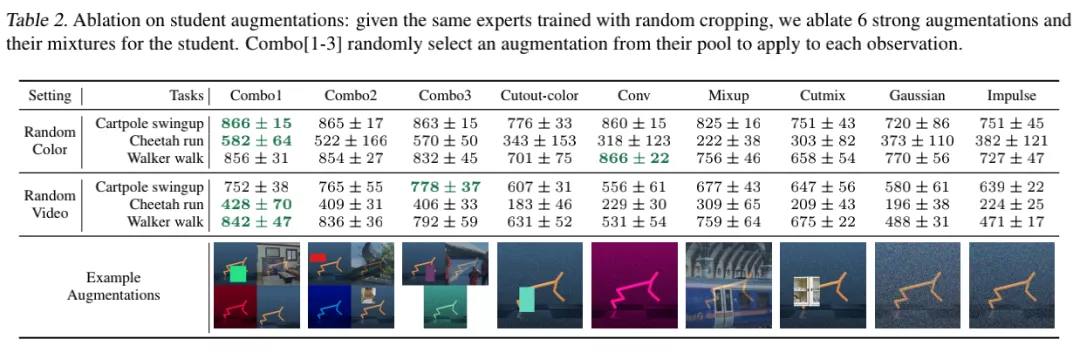
作者通過將原有視覺元素進行插入色塊(Cc)、隨機卷積(Cv)、補充高斯噪聲(G)以及添線性混合(M)等方式來生成不同的視覺樣本。
作者還研究了以上的組合,并試圖發現從低頻和高頻結構噪聲中的隨機抽樣產生最佳的總體結果。作者注意到,在混合中添加隨機裁剪略微有利于性能的提升,可能是因為它改善了學生策略表征的空間不變性。
實驗內容

四種不同場景的視覺策略泛化基準測試(從上至下):DMControl Suite、CARLA、Robosuite和iGibson
首先,作者提出了一個適用于四種不同領域的基準測試,系統地評估視覺agent的泛化能力。
在每個領域中,團隊研究了在一個環境中訓練的算法,在零樣本設置中的各種未見環境中的表現如何。此時沒有獎勵信號和額外的試驗。
在每個任務中,SECANT以之前的SOTA算法為基準:SAC、SAC+crop、DR、NetRand、SAC+IDM和PAD。
DMControl

研究團隊依照前人的設置,使用來自DMControl的8個任務進行實驗。
測量泛化能力,隨機生成背景和機器人本身的顏色,將真實的視頻作為動態背景。
除了一項任務外,SECANT在所有任務中都顯著優于先前的SOTA,通常高出88.3%。
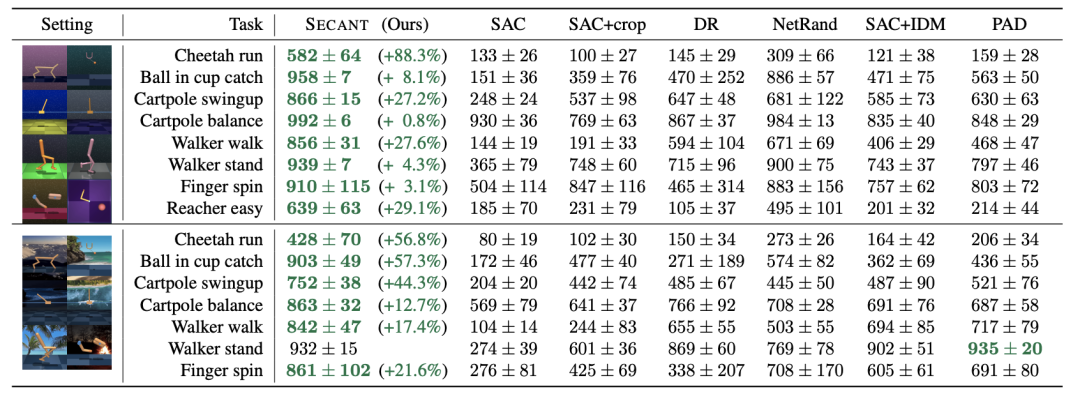
所有方法都經過50萬步訓練,有密集的任務特定獎勵。
Robosuite:機器人操作模擬器
Robosuite是用于機器人研究的模塊化模擬器。
作者在4個具有挑戰性的單臂和雙手操作任務上對SECANT和先前方法進行了基準測試。
使用具有操作空間控制的Franka Panda機器人模型,并使用特定于任務的密集獎勵進行訓練。
所有agent都接收一個168×168以自我為中心的RGB視圖作為輸入。
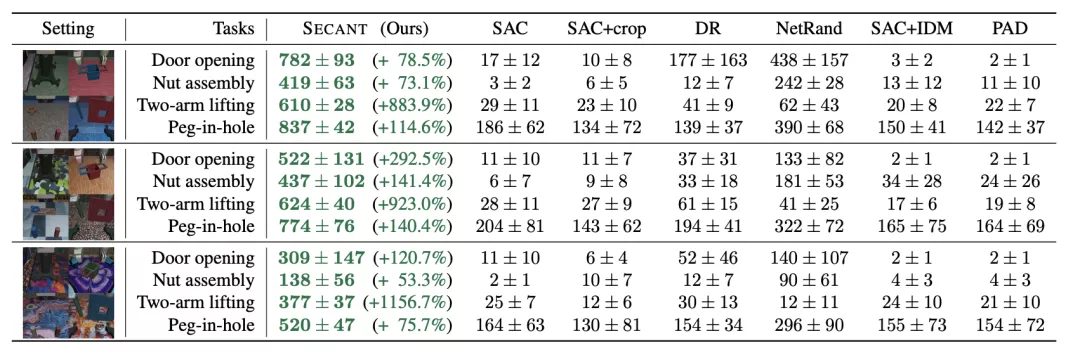
與之前SOTA相比,SECANT有337.8%的提升
實驗表明,與之前的最佳方法相比,SECANT在簡單設置中獲得的獎勵平均增加了287.5%,在困難設置中增加了374.3%,在極端設置中增加了351.6%。
CARLA:自動駕駛模擬器
為了進一步驗證SECANT對自然變化的泛化能力,作者在CARLA模擬器中構建了一個具有視覺觀察的真實駕駛場景。
測試目標是在1000個時間步長內沿著8字形高速公路(CARLA Town 4)行駛盡可能遠,不與行人或車輛發生碰撞。
agent在「晴朗的中午」情景接受訓練,并在中午和日落時對各種動態天氣和光照條件進行評估。


例如,潮濕天氣的特點是道路具有高反射點。經過平均每個天氣超過10集和5次訓練運行,SECANT在測試中能夠比之前的SOTA行駛的距離增加47.7%。
iGibson:室內物體導航
iGibson是一個交互式模擬器,有高度逼真的3D房間和家具。
在這個模擬器中,實驗的目標是盡可能接近一盞燈。
獎勵函數激勵agent使燈在視野中所占的像素比例最大,當這個比例在連續10個步驟中超過5%時就算成功。

在本測試中,在未見過的房間里,SECANT的成功率比之前的方法高出15.8%。
作者簡介
本文一作是李飛飛門下得意弟子Linxi Fan,他畢業于上海實驗中學,本科就讀于紐約哥倫比亞大學,目前在斯坦福大學攻讀博士,主修計算機視覺、強化學習以及機器人技術。在英偉達實習期間完成了本論文。
本文二作黃德安同樣師從李飛飛,本科畢業于國立臺灣大學,獲得了卡內基梅隆大學碩士學位。目前在斯坦福大學計算機科學專業攻讀博士學位,在NVIDIA做泛化學習類研究。
三作禹之鼎也是來自NVIDIA的科學家,獲得華南理工大學電機工程聯合班學士學位、香港科技大學電子工程學士學位,2017年在卡內基梅隆大學獲得了ECE博士學位。
2018年加入英偉達,現在是英偉達機器學習研究組的高級研究科學家。



























