零樣本性能超越小樣本,谷歌1370億參數(shù)新模型比GPT-3更強(qiáng)
在 NLP 領(lǐng)域,pretrain-finetune 和 prompt-tuning 技術(shù)能夠提升 GPT-3 等大模型在各類(lèi)任務(wù)上的性能,但這類(lèi)大模型在零樣本學(xué)習(xí)任務(wù)中的表現(xiàn)依然不突出。為了進(jìn)一步挖掘零樣本場(chǎng)景下的模型性能,谷歌 Quoc Le 等研究者訓(xùn)練了一個(gè)參數(shù)量為 1370 億的自回歸語(yǔ)言模型 Base LM,并在其中采用了全新的指令調(diào)整(instruction tuning)技術(shù),結(jié)果顯示,采用指令調(diào)整技術(shù)后的模型在自然語(yǔ)言推理、閱讀理解和開(kāi)放域問(wèn)答等未見(jiàn)過(guò)的任務(wù)上的零樣本性能超越了 GPT-3 的小樣本性能。
大規(guī)模語(yǔ)言模型(LM)已經(jīng)被證明可以很好的應(yīng)用到小樣本學(xué)習(xí)任務(wù)。例如 OpenAI 提出的 GPT-3 ,參數(shù)量達(dá) 1,750 億,不僅可以更好地答題、翻譯、寫(xiě)文章,還帶有一些數(shù)學(xué)計(jì)算的能力等。在不進(jìn)行微調(diào)的情況下,可以在多個(gè) NLP 基準(zhǔn)上達(dá)到最先進(jìn)的性能。
然而,像 GPT-3 這樣的大規(guī)模語(yǔ)言模型在零樣本(zero-shot)學(xué)習(xí)任務(wù)中表現(xiàn)不是很突出。例如,GPT-3 在執(zhí)行閱讀理解、問(wèn)答和自然語(yǔ)言推理等任務(wù)時(shí),零樣本的性能要比小樣本(few-shot)性能差很多。
本文中,Quoc Le 等來(lái)自谷歌的研究者探索了一種簡(jiǎn)單的方法來(lái)提高大型語(yǔ)言模型在零樣本情況下的性能,從而擴(kuò)大受眾范圍。他們認(rèn)為 NLP 任務(wù)可以通過(guò)自然語(yǔ)言指令來(lái)描述,例如「這部影評(píng)的情緒是正面的還是負(fù)面的?」或者「把『how are you』譯成漢語(yǔ)」。
該研究采用具有 137B 參數(shù)的預(yù)訓(xùn)練模型并執(zhí)行指令調(diào)整任務(wù),對(duì) 60 多個(gè)通過(guò)自然語(yǔ)言指令表達(dá)的 NLP 任務(wù)進(jìn)行調(diào)整。他們將這個(gè)結(jié)果模型稱(chēng)為 Finetuned LANguage Net,或 FLAN。

- 論文地址:https://arxiv.org/pdf/2109.01652.pdf
- GitHub 地址:https://github.com/google-research/flan.
為了評(píng)估 FLAN 在未知任務(wù)上的零樣本性能,該研究根據(jù) NLP 任務(wù)的任務(wù)類(lèi)型將其分為多個(gè)集群,并對(duì)每個(gè)集群進(jìn)行評(píng)估,同時(shí)在其他集群上對(duì) FLAN 進(jìn)行指令調(diào)整。如下圖 1 所示,為了評(píng)估 FLAN 執(zhí)行自然語(yǔ)言推理的能力,該研究在一系列其他 NLP 任務(wù)(如常識(shí)推理、翻譯和情感分析)上對(duì)模型進(jìn)行指令調(diào)整。由于此設(shè)置確保 FLAN 在指令調(diào)整中未見(jiàn)自然語(yǔ)言推理任務(wù),因此可以評(píng)估其執(zhí)行零樣本自然語(yǔ)言推理的能力。
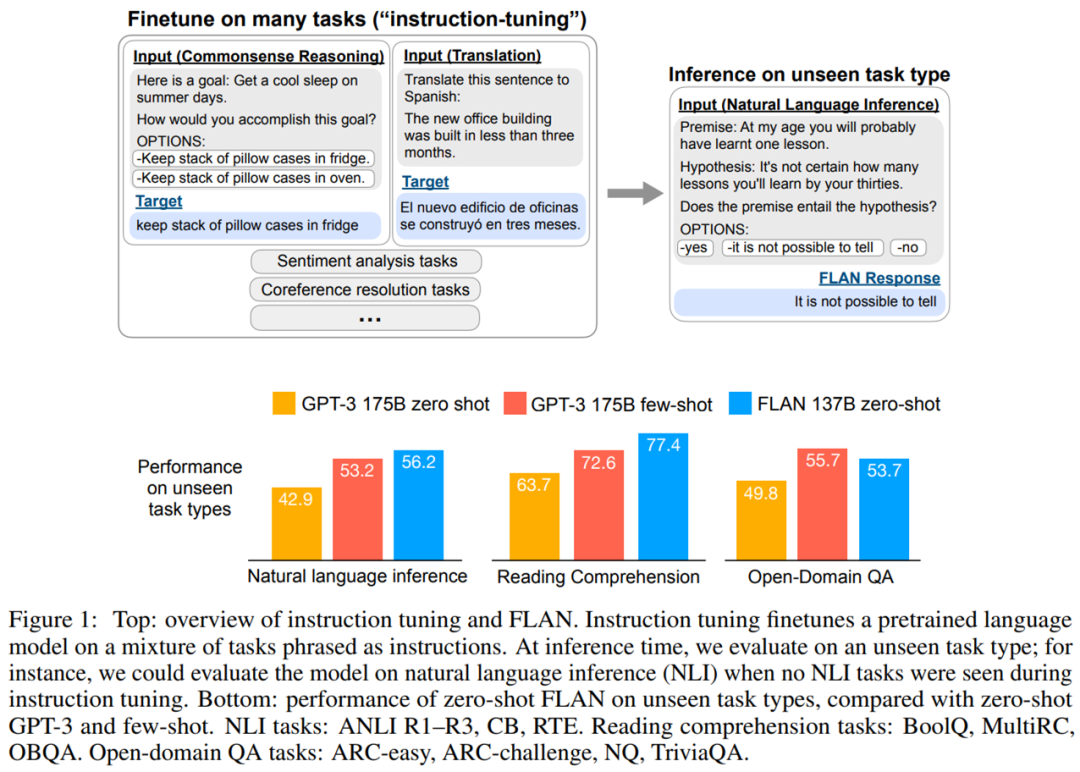
評(píng)估表明,F(xiàn)LAN 顯著提高了模型(base 137B 參數(shù))的零樣本性能。在 25 個(gè)評(píng)估任務(wù)中,F(xiàn)LAN 零樣本在 19 項(xiàng)任務(wù)上優(yōu)于具有 175B 參數(shù) GPT-3 零樣本,甚至在許多任務(wù)(如 ANLI、RTE、BoolQ、AI2-ARC、OpenbookQA 和 StoryCloze)上也顯著優(yōu)于 GPT-3 小樣本。在消融研究中,研究發(fā)現(xiàn)在指令調(diào)整中增加任務(wù)集群的數(shù)量,可以提高模型在未見(jiàn)過(guò)的任務(wù)的性能,并且指令調(diào)整的好處只有在模型規(guī)模足夠大的情況下才會(huì)出現(xiàn)。
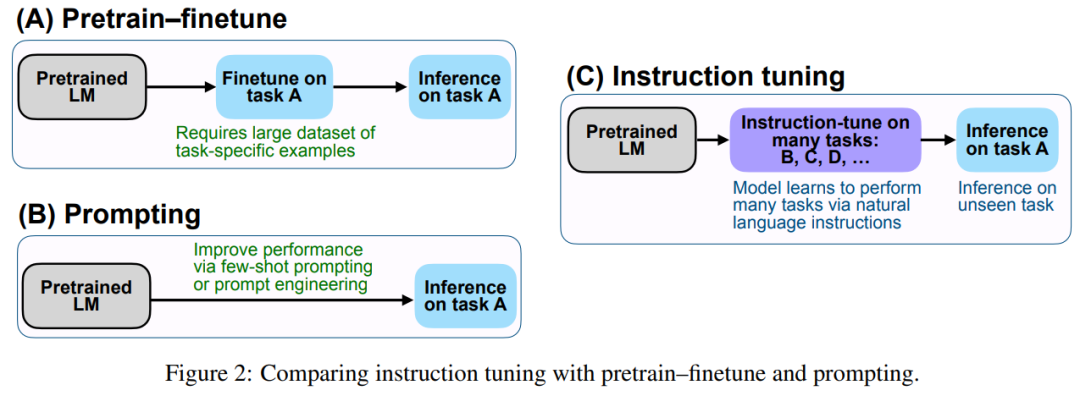
該研究實(shí)證結(jié)果強(qiáng)調(diào)了語(yǔ)言模型使用自然語(yǔ)言指令描述任務(wù)的能力。更廣泛地說(shuō),如圖 2 所示,指令調(diào)整結(jié)合了預(yù)訓(xùn)練微調(diào)(pretrain–finetune)特點(diǎn),并通過(guò)使用 finetune 監(jiān)督來(lái)提高語(yǔ)言模型響應(yīng)推理時(shí)文本交互的能力。
FLAN:用指令調(diào)整改進(jìn)零樣本學(xué)習(xí)
指令調(diào)整的動(dòng)機(jī)是提高語(yǔ)言模型響應(yīng) NLP 指令的能力,旨在通過(guò)使用監(jiān)督來(lái)教 LM 執(zhí)行以指令描述的任務(wù)。語(yǔ)言模型將學(xué)會(huì)遵循指令,即使對(duì)于未見(jiàn)過(guò)的任務(wù)也能執(zhí)行。為了評(píng)估模型在未見(jiàn)過(guò)的任務(wù)上的性能,該研究按照任務(wù)類(lèi)型將任務(wù)分成多個(gè)集群,當(dāng)其他集群進(jìn)行指令調(diào)整時(shí),留出一個(gè)任務(wù)集群進(jìn)行評(píng)估。
任務(wù)和模板
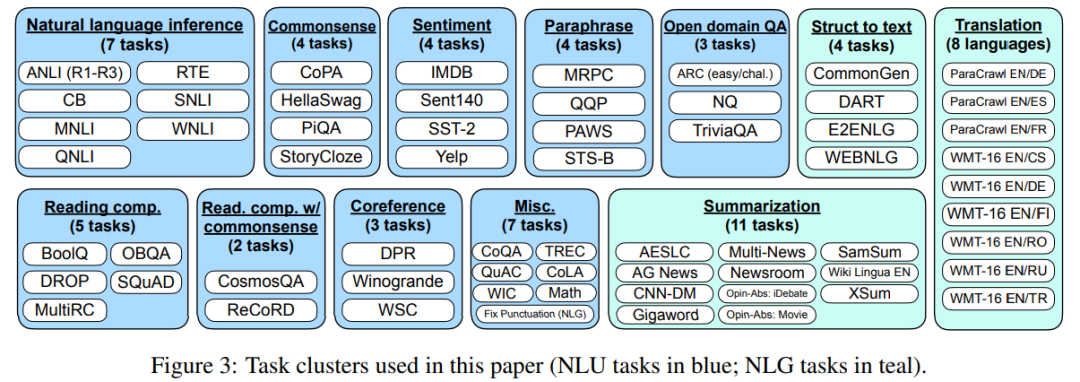
該研究將 62 個(gè)在 Tensorflow 數(shù)據(jù)集上公開(kāi)可用的文本數(shù)據(jù)集(包括語(yǔ)言理解和語(yǔ)言生成任務(wù))聚合到一起。下圖 3 顯示了該研究使用的所有數(shù)據(jù)集;每個(gè)數(shù)據(jù)集被歸類(lèi)為十二個(gè)任務(wù)集群之一,每個(gè)集群中的數(shù)據(jù)集有著相同的任務(wù)類(lèi)型。
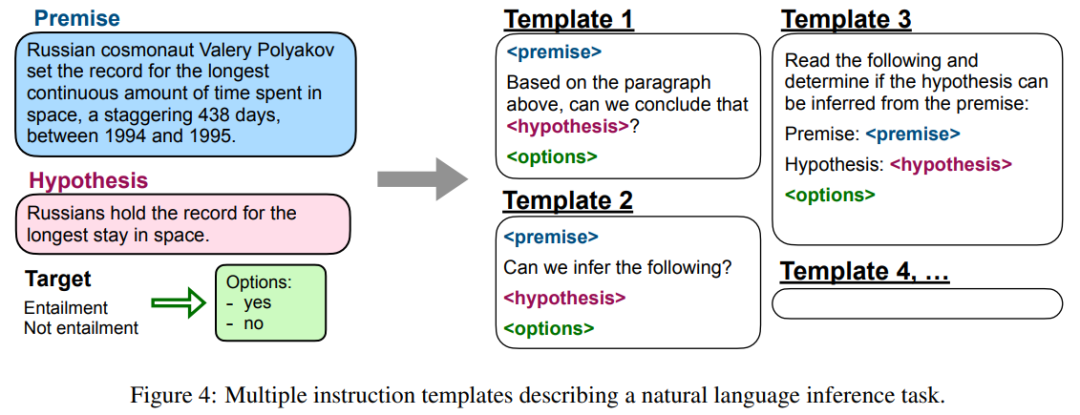
該研究將任務(wù)定義為由數(shù)據(jù)集給出的一組特定的輸入 - 輸出對(duì)。對(duì)于每個(gè)任務(wù),研究者手動(dòng)編寫(xiě)十個(gè)獨(dú)特的模板,使用自然語(yǔ)言指令描述任務(wù)。十個(gè)模板大多描述的是原始任務(wù),但為了增加多樣性,研究者為每個(gè)任務(wù),提供了最多三個(gè)「變更任務(wù)(turned the task around)」的模板,下圖 4 給出了自然語(yǔ)言推理任務(wù)的多個(gè)指令模板。
訓(xùn)練細(xì)節(jié)
模型架構(gòu)和預(yù)訓(xùn)練。在實(shí)驗(yàn)中,該研究使用密集的從左到右、僅解碼器、137B 參數(shù)的 transformer 語(yǔ)言模型。該模型在一組網(wǎng)絡(luò)文檔(包括含計(jì)算機(jī)代碼的文檔)、對(duì)話(huà)數(shù)據(jù)和 Wikipedia 上進(jìn)行預(yù)訓(xùn)練,這些文檔使用 SentencePiece 庫(kù) (Kudo & Richardson, 2018),被 tokenize 為 2.81T BPE token 和 32K token 的詞表。大約 10% 的預(yù)訓(xùn)練數(shù)據(jù)是非英語(yǔ)的。這個(gè)數(shù)據(jù)集不像 GPT-3 訓(xùn)練集那么干凈,而且還混合了對(duì)話(huà)和代碼。
實(shí)驗(yàn)結(jié)果
研究者分別在自然語(yǔ)言推理、閱讀理解、開(kāi)放域問(wèn)答、常識(shí)推理、共指消解和翻譯等多項(xiàng)任務(wù)上對(duì) FLAN 的性能進(jìn)行了評(píng)估。對(duì)于每一項(xiàng)任務(wù),他們報(bào)告了在所有模板上性能的平均和標(biāo)準(zhǔn)誤差,這代表了給定典型自然語(yǔ)言指令時(shí) FLAN 的預(yù)期性能。
自然語(yǔ)言推理任務(wù)
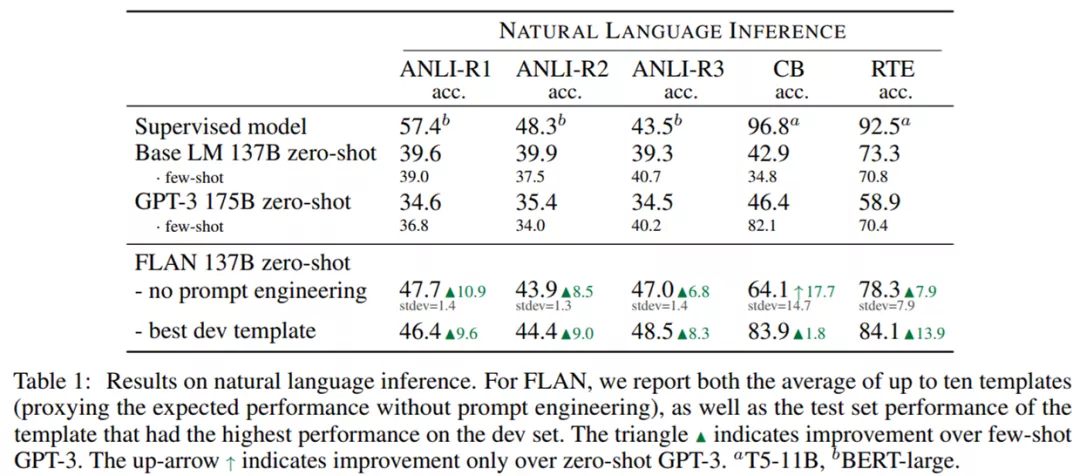
下表 1 展示了不同模型自然語(yǔ)言推理測(cè)試的結(jié)果,其中給定一個(gè)前提與假設(shè)——模型必須確認(rèn)在給定前提為真的情況下假設(shè)也為真。可以看到,F(xiàn)LAN 在所有情況下均表現(xiàn)出強(qiáng)大的性能。
盡管在 CB 和 RTE 的不同模板的結(jié)果中存在高方差,但 FLAN 在沒(méi)有任何 prompt 工程時(shí)依然在四個(gè)數(shù)據(jù)集上顯著優(yōu)于零樣本和小樣本 GPT-3。在具有最佳 dev 模板時(shí),F(xiàn)LAN 在五個(gè)數(shù)據(jù)集上優(yōu)于小樣本 GPT-3。FLAN 甚至在 ANLI-R3 數(shù)據(jù)集上超越了監(jiān)督式 BERT。
閱讀理解和開(kāi)放域問(wèn)答任務(wù)
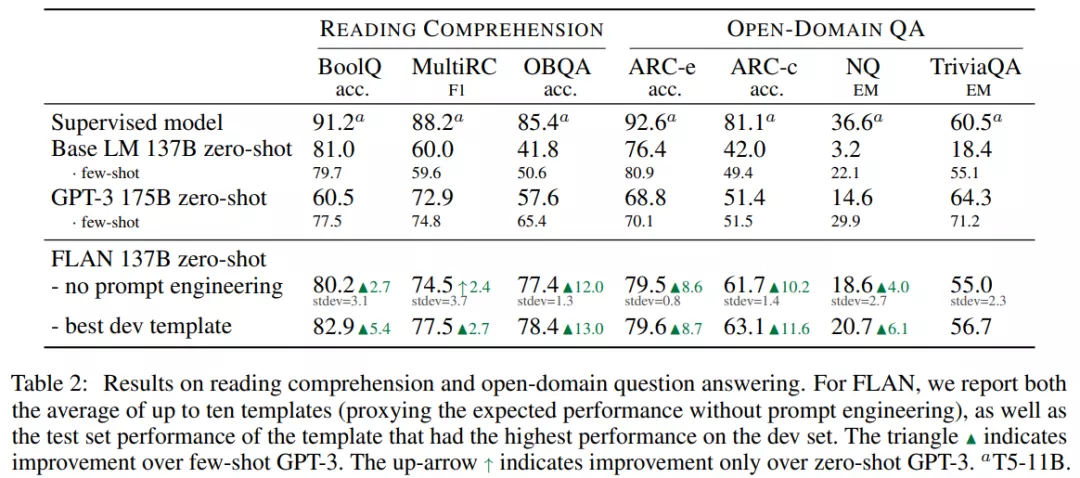
在閱讀理解任務(wù)上,模型被要求回答關(guān)于給定文章段落的問(wèn)題,結(jié)果如下表 2 所示。FLAN 在 BoolQ 和 OBQA 數(shù)據(jù)集上顯著優(yōu)于 GPT-3。在使用最佳 dev 模板時(shí),F(xiàn)LAN 在 MultiRC 數(shù)據(jù)集上略?xún)?yōu)于小樣本 GPT-3。
對(duì)于開(kāi)放域問(wèn)答任務(wù),F(xiàn)LAN 在 ARC-easy 和 ARC-challenge 數(shù)據(jù)集上顯著優(yōu)于零樣本和小樣本 GPT-3。在 Natural Questions 數(shù)據(jù)集上,F(xiàn)LAN 優(yōu)于零樣本 GPT-3,弱于小樣本 GPT-3。
常識(shí)推理和共指消解任務(wù)
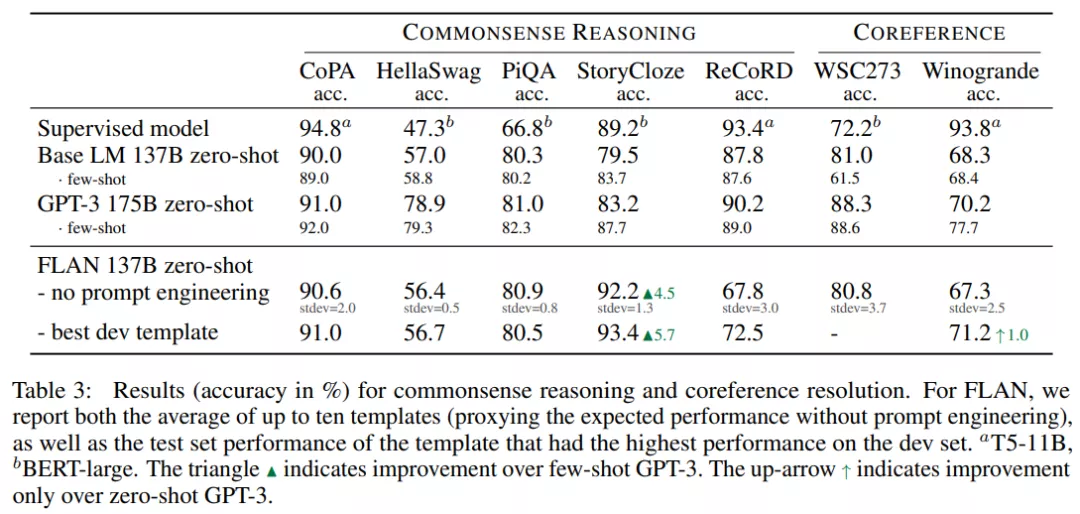
不同模型在五個(gè)常識(shí)推理數(shù)據(jù)集上的結(jié)果如下表 3 所示,F(xiàn)LAN 在 StoryCloze 數(shù)據(jù)集上優(yōu)于 GPT-3,在 CoPA 和 PiQA 數(shù)據(jù)集上媲美 GPT-3。但在 HellaSwag 和 ReCoRD 數(shù)據(jù)集上,Base LM 和 FLAN 均弱于 GPT-3。
在兩個(gè)共指消解任務(wù)上,具有最佳 dev 模板的 FLAN 在 Winogrande 數(shù)據(jù)集上優(yōu)于零樣本 GPT-3,但在 WSC273 數(shù)據(jù)集上,Base LM 和 FLAN 均弱于 GPT-3。
翻譯
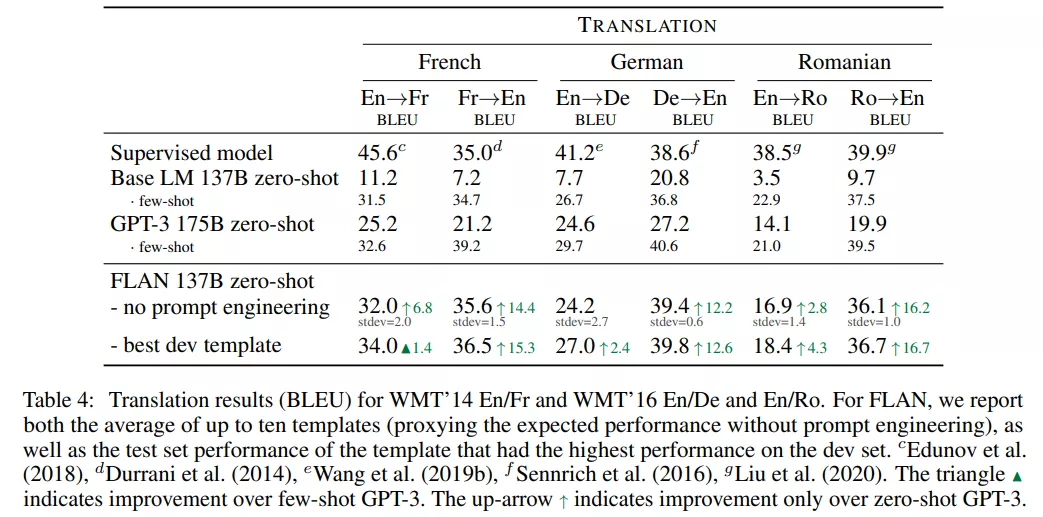
研究者還在 GPT-3 論文中評(píng)估的三個(gè)數(shù)據(jù)集上測(cè)試了 FLAN 的機(jī)器翻譯性能,這三個(gè)數(shù)據(jù)集分別是 WMT’14 法語(yǔ) - 英語(yǔ)以及 WMT’16 的德語(yǔ) - 英語(yǔ)和羅馬尼亞語(yǔ) - 英語(yǔ)。
測(cè)試結(jié)果如下表 4 所示,Base LM 的零樣本翻譯性能弱,但小樣本翻譯結(jié)果媲美 GPT-3。FLAN 在六個(gè)評(píng)估指標(biāo)中的五個(gè)上優(yōu)于小樣本 Base LM。與 GPT-3 類(lèi)似,F(xiàn)LAN 在翻譯成英語(yǔ)任務(wù)上展示出了強(qiáng)大的性能,并且與監(jiān)督式翻譯基線相比具有優(yōu)勢(shì)。
其他實(shí)驗(yàn)
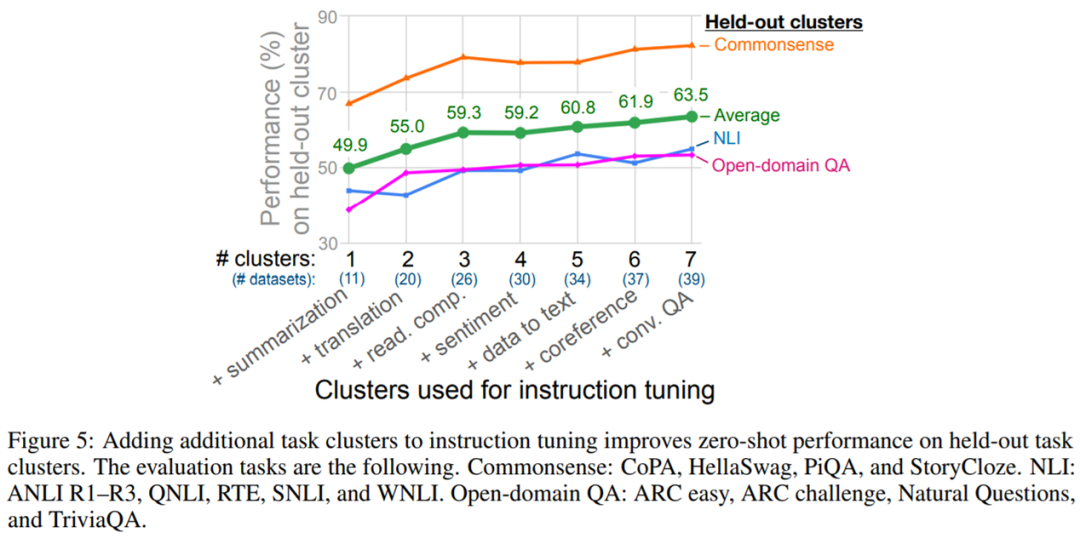
由于該論文的核心問(wèn)題是指令調(diào)整如何提高模型在未見(jiàn)過(guò)任務(wù)上的零樣本性能,因此該研究的第一個(gè)消融實(shí)驗(yàn)研究了指令調(diào)整中使用的集群和任務(wù)數(shù)量對(duì)性能的影響。
圖 5 顯示了實(shí)驗(yàn)結(jié)果。與預(yù)期一致,研究者觀察到 3 個(gè) held-out 集群的平均性能隨著向指令調(diào)整添加額外的集群和任務(wù)而提高(情感分析集群除外),證實(shí)了所提指令調(diào)整方法有助于在新任務(wù)上提升零樣本性能。
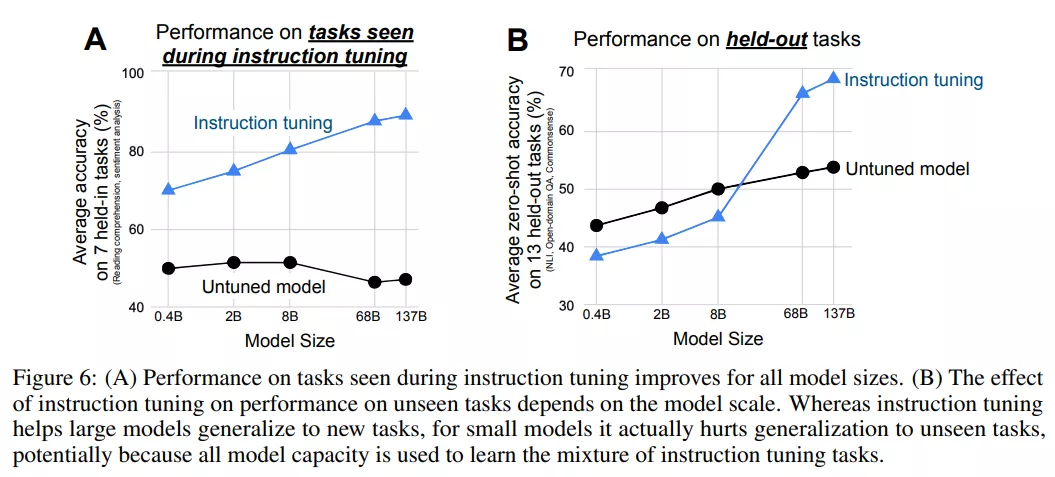
下圖 6 結(jié)果表明,對(duì)于較大規(guī)模的模型,指令調(diào)整填充了一些模型容量,但也教會(huì)了這些模型遵循指令的能力,允許模型將剩余的容量泛化到新任務(wù)。