













Kafka中的這只“千里眼”,你需要知道!!!
作為Kafka集群的負責人,消費端出現(xiàn)消息積壓,反復發(fā)生重平衡等問題時,如何快速定位性能瓶頸顯的至關重要。
本篇將詳細介紹消費端端監(jiān)控指標,讓架構師提出的性能優(yōu)化方案提供數(shù)據(jù)支撐。
Kafka的設計者早就為我們考慮好了,提供了豐富多彩的監(jiān)控指標。
1、消費端指標
Kafka中的監(jiān)控指標通過MBean進行存儲,我們可以通過jconsole中進行查看,截圖如下:
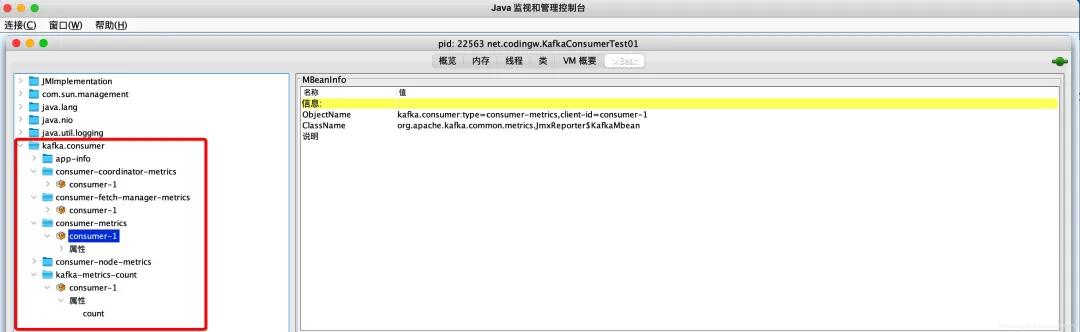
主要分為如下四個維度展開:
- Consumer-coordinator-metrics
消費者組協(xié)調器相關的監(jiān)控指標。
- Consumer-fetch-manager-metrics
消費組消息拉取相關的監(jiān)控指標
- Consumer-node-metrics
以broker節(jié)點為維度的統(tǒng)計信息,消費端向多個broker節(jié)點拉取消息等監(jiān)控指標。
- Kafka-metrics-count
接下來將分別展開,詳細介紹其各個指標的含義,并給出一些實踐指導。
1.1 消費者組協(xié)調器監(jiān)控指標
組協(xié)調器相關的監(jiān)控指標明細說明如下:
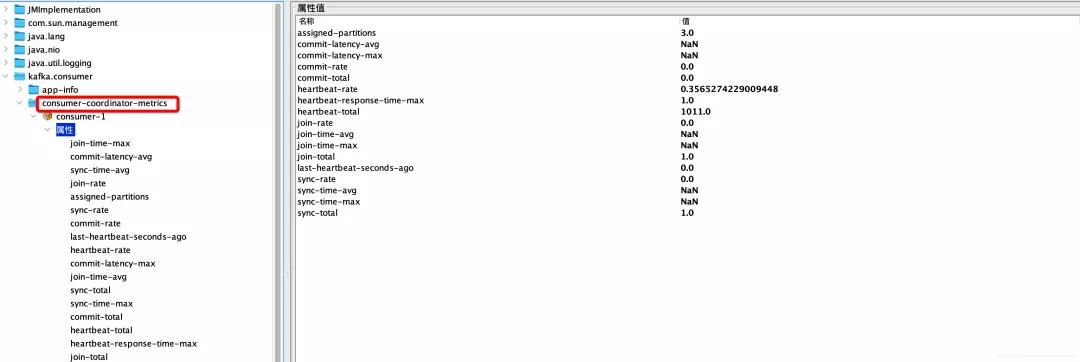
詳細說明如下:
- join-time-max
消費者重新加入消費組的最大時長
- join-time-avg
消費者重新加入消費組的平均時長
- join-rate
消費者加入消費組的TPS
實踐指導:該值為0正常,該值越大,越有問題,說明消費者在頻繁加入消費者,在加入消費者的過程中消費者是不會消費消息的。
- join-time-avg
消費者加入消費組的平均時間
- join-total
該消費者重新加入消費組的次數(shù)(重平衡發(fā)生的次數(shù))
實踐指導:該值值的采集,如果該值過大,說明發(fā)生重平衡的次數(shù)太多,重平衡時該消費者時不參與消息消費。
- commit-latency-avg
提交位點的平均耗時
- commit-rate
提交位點的tps
- commit-latency-max
提交位點時的最大延遲時間
- commit-total
消費者啟動以來的位點提交的總次數(shù)
- sync-time-avg
消費者發(fā)送sync的平均響應時長。
知識點:消費者加入小組后由該消費者中的Leader負責進行隊列分配,然后將分配方案發(fā)送給組協(xié)議器,各個從節(jié)點將向組協(xié)調器獲取分配隊列。
- sync-rate
消費者發(fā)送sync的tps
- sync-total
消費者發(fā)送sync請求的總次數(shù)
- sync-time-max
消費者sync請求響應的最大響應時間
- assigned-partitions
當前分配到的分區(qū)數(shù)量
- heartbeat-total
心跳請求的總數(shù)
- heartbeat-response-time-max
心跳請求的最大響應時間
- last-heartbeat-seconds-ago
上一次發(fā)送心跳包的時間
- heartbeat-rate
發(fā)送心跳包的tps
從監(jiān)控指標來看,我們有能得知消費端協(xié)調器的職責:
- 協(xié)調消費者加入消費組
- 協(xié)調消費者Leader進行隊列負載分配
- 發(fā)送心跳,保持會話
- 提交位點
1.2 消費者消息拉取監(jiān)控指標
消費者與消息拉取相關的監(jiān)控指標如下圖所示:
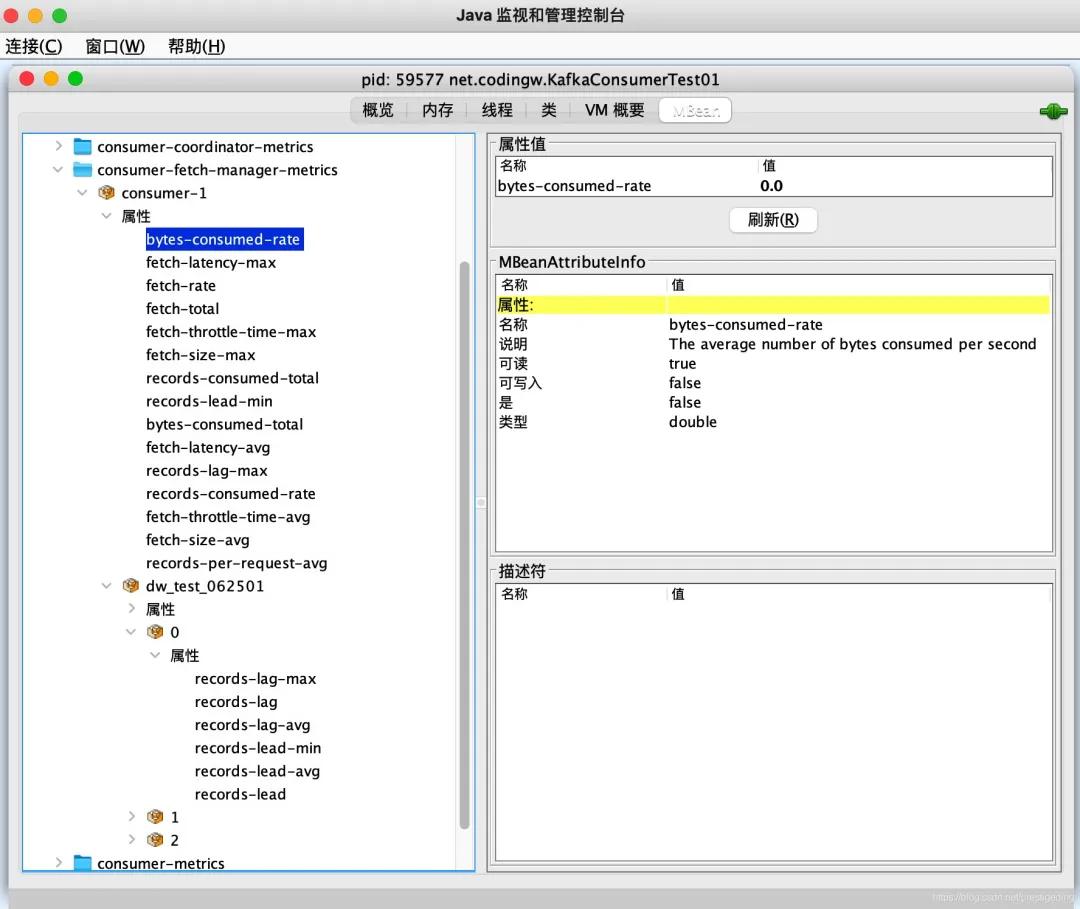
消費組拉取指標的組織分成消費組與該消費組訂閱的多個topic兩個維度。
接下來詳細分析上述指標:
- bytes-consumed-rate
消費端每秒提交到業(yè)務的tps。
- bytes-consumed-total
消費端目前消費的總字節(jié)數(shù)。
- fetch-latency-max
API.FETCH請求(即向broker端發(fā)送消息拉取)的最大耗時。
- records-per-request-avg
每一次Fetch請求拉取的消息條數(shù)(對當前指標取平均值)。
- fetch-rate
客戶端發(fā)送Fetch請求的tps。
- fetch-total
客戶端總共發(fā)起的Fetch請求個數(shù)
- fetch-throttle-time-max
消息拉取(Fetch請求)由于服務端(broker)限流的最大限流時長,關于broker端限流機制,后續(xù)會重點探究。
- fetch-throttle-time-avg
消息拉取Fetch請求的平均限流時長。
- fetch-size-max
單個分區(qū)一次消息拉取最大的字節(jié)數(shù)。
實踐指導:該值非常有必要采集監(jiān)控,可以評估消費端消息的拉取能力,如果該值持續(xù)接近設置的期望值,如果消費端tps不滿足需求,可以適當調大該值。
- fetch-latency-avg
消息拉取的平均耗時。
- fetch-size-avg
一次消息拉取的平均字節(jié)數(shù)
- records-consumed-total
消費端消費端總字節(jié)數(shù)
- records-lead-min
當前消費位點與日志端中最小位點的差值。
- records-lag-max
分配給消費者的分區(qū)中,消息積壓的最大值。
實戰(zhàn)指導:可以基于該值做告警。
消費者還會從主題-分區(qū)級別采集與消費進度相關的指標,相關指標說明如下:
- records-lag
- records-lag-avg
- records-lag-max
- records-lead
- records-lead-avg
- records-lead-min
對于上述指標,主要是解釋一下兩個基本的含義,其他指標是對其進行聚合計算(max,avg)。
- records-lag
消費積壓,即消費位點與當前分區(qū)最大位點點差距,該值越大,說明消費端處理速度越慢,需要十分關注,通常需要接入告警,及時通知項目方。
- records-lead
消費位點與當前分區(qū)最小位點的差距,我對該值的具體用途暫未參悟,有心的讀者看到,歡迎與我共同交流。
1.3 消費者網(wǎng)絡相關監(jiān)控指標
上面的指標主要是關注消費端協(xié)調器、消費端Fetch(消息拉取)兩個重要維度,接下來關注一下從消息者的視角關注一下底層網(wǎng)絡IO等維度相關的指標,相關指標的采集入口位Kafka的org.apache.kafka.common.network.Selector,其具體的指標如下圖所示:
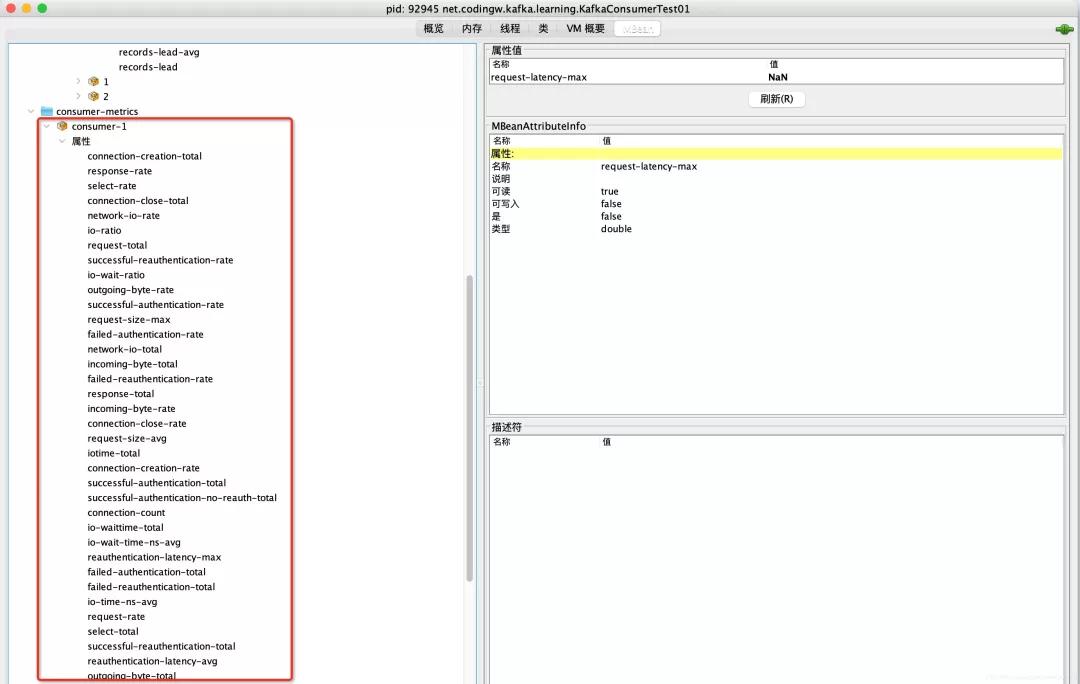
其實這些指標基本與生產(chǎn)者相同,說明如下:
- request-rate
請求發(fā)送tps。
- request-size-max
請求發(fā)送的最大字節(jié)
- request-size-avg
請求的平均大小
- request-total
總共的請求個數(shù)
- select-rate
事件選擇器tps。
- select-total
事件選擇器執(zhí)行事件選擇的總次數(shù)
- response-total
響應請求總數(shù)
- response-rate
響應TPS
- outgoing-byte-rate
每秒發(fā)送字節(jié)數(shù)
- outgoing-byte-total
總發(fā)送字節(jié)數(shù)
- incoming-byte-rate
每秒接受字節(jié)數(shù)
- incoming-byte-total
總工接受字節(jié)數(shù)
- io-ratio
IO線程處理IO讀寫的總時間
- io-time-ns-avg
每一次事件選擇器調用IO操作的平均時間(單位為納秒)
- io-waittime-total
io線程等待讀寫就緒的平均時間(單位為納秒)
- iotime-total
io處理總時間。
- io-wait-ratio
io等待占io總處理時間的比例
- io-wait-time-ns-avg
io線程平均等待時間(納秒)
實戰(zhàn)指導:網(wǎng)絡相關的監(jiān)控指標,可以重點關注一下io線程相關的性能。
1.4 按broker節(jié)點采集監(jiān)控數(shù)據(jù)
客戶端還會按照broker的維度,重點采集與請求相關的指標,例如請求tps、平均響應時間。
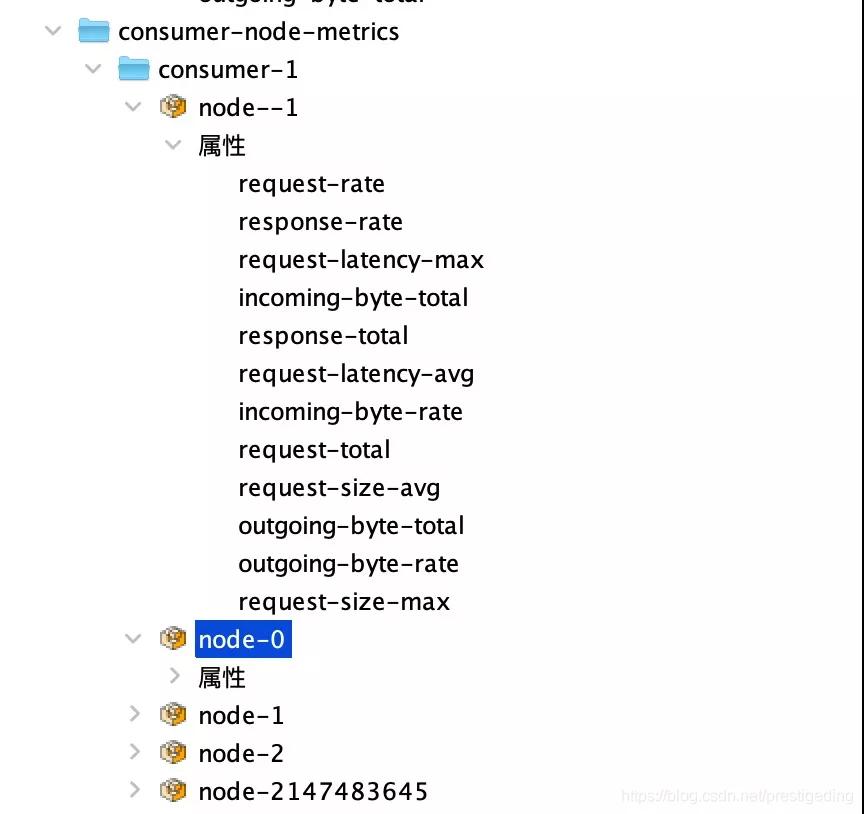
實戰(zhàn)指導:監(jiān)控指標的含義都已經(jīng)在上文中提到過,這些指標應該是最值得采集,特別是request-latency-max、request-latency-avg,這對確認broker是否存在瓶頸。
2、監(jiān)控指標采集
雖然Kafka內置了眾多的監(jiān)控指標,但這些指標默認是存儲在內存中,既然是存放在內存中,為了避免監(jiān)控數(shù)據(jù)無休止的增加內存觸發(fā)內存溢出,通常監(jiān)控數(shù)據(jù)的存儲基本是基于滑動窗口,即只會存儲最近一段時間內的監(jiān)控數(shù)據(jù),進行滾動覆蓋。
故為了更加直觀的展示這些指標,因為需要定時將這些信息進行采集,統(tǒng)一存儲在其他數(shù)據(jù)庫等持久化存儲,可以根據(jù)歷史數(shù)據(jù)繪制曲線,希望實現(xiàn)的效果如下圖所示:
在這里插入圖片描述
基本的監(jiān)控采集系統(tǒng)架構設計如下圖所示:
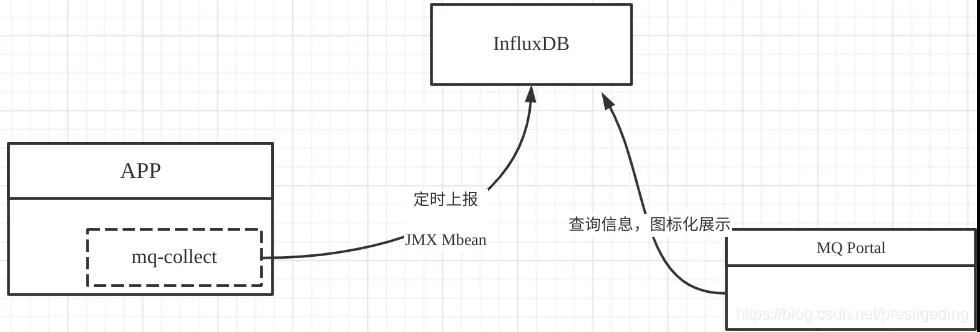
mq-collect應該是放在生產(chǎn)者SDK中,通過mq-collect類庫異步定時將采集信息上傳的到時序數(shù)據(jù)庫InfluxDB,然后通過mq-portal門戶展示頁面,對每一個生產(chǎn)客戶端按指標進行可視化展示,實現(xiàn)監(jiān)控數(shù)據(jù)的可視化,從而為性能優(yōu)化提供依據(jù)。
本文轉載自微信公眾號「中間件興趣圈」,可以通過以下二維碼關注。轉載本文請聯(lián)系中間件興趣圈公眾號。



















