面試常考項目易錯,長文詳解C/C++中的字節對齊
引入主題,看代碼
我們先來看看以下程序
- #include <iostream>
- using namespace std;
- struct st1
- {
- char a ;
- int b ;
- short c ;
- };
- struct st2
- {
- short c ;
- char a ;
- int b ;
- };
- int main()
- {
- cout<<"sizeof(st1) -> "<<sizeof(st1)<<endl;
- cout<<"sizeof(st2) -> "<<sizeof(st2)<<endl;
- return 0 ;
- }
編譯的結果如下:
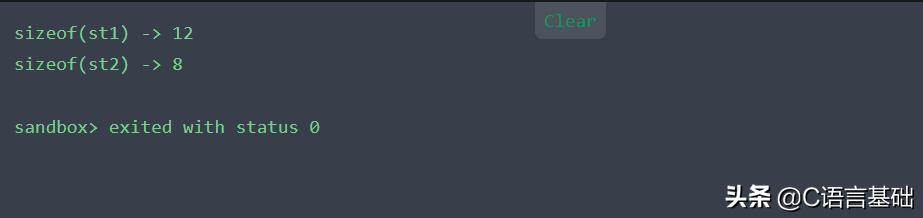
問題來了,兩個結構體的內容一樣,只是換了個位置,為什么sizeof(st)的時候大小不一樣呢?
沒錯,這正是因為內存對齊的影響,導致的結果不同。對于我們大部分程序員來說,都不知道內存是怎么分布的。
實際上因為這是編譯器該干的活,編譯器把程序中的每個數據單元安排在合適的位置上,導致了相同的變量,不同聲明順序的結構體大小的不同。
幾種類型數據所占字節數
int,long int,short int的寬度和機器字長及編譯器有關,但一般都有以下規則(ANSI/ISO制訂的)
- sizeof(short int) <= sizeof(int)
- sizeof(int) <= sizeof(long int)
- short int至少應為16位(2字節)
- long int至少應為32位
數據類型16位編譯器32位編譯器64位編譯器char1字節1字節1字節char*2字節4字節8字節short int2字節2字節2字節int2字節4字節4字節unsigned int2字節4字節4字節float4字節4字節4字節double8字節8字節8字節long4字節4字節8字節long long8字節8字節8字節unsigned long4字節4字節8字節
什么是對齊
現代計算機中內存空間都是按照byte劃分的,從理論上講似乎對任何類型的變量的訪問都可以從任何地址開始,但實際情況是在訪問特定變量的時候經常在特定的內存地址訪問。
所以這就需要各類型數據按照一定的規則在空間上排列,而不是順序的一個接一個的排放,這就是對齊。內存對齊又分為自然對齊和規則對齊。
對于內存對齊問題,主要存在于struct和union等復合結構在內存中的分布情況,許多實際的計算機系統對基本類型數據在內存中存放的位置有限制,它們要求這些數據的首地址的值是某個數M(通常是4或8);
對于內存對齊,主要是為了提高程序的性能,數據結構,特別是棧,應盡可能在自然邊界上對齊,經過對齊后,cpu的內存訪問速度大大提升。
自然對齊
指的是將對應變量類型存入對應地址值的內存空間,即數據要根據其數據類型存放到以其數據類型為倍數的地址處。
例如char類型占1個字節空間,1的倍數是所有數,因此可以放置在任何允許地址處,而int類型占4個字節空間,以4為倍數的地址就有0,4,8等。編譯器會優先按照自然對齊進行數據地址分配。
規則對齊
以結構體為例就是在自然對齊后,編譯器將對自然對齊產生的空隙內存填充無效數據,且填充后結構體占內存空間為結構體內占內存空間最大的數據類型成員變量的整數倍。
實驗對比
首先看這個結構體
- typedef struct test_32
- {
- char a;
- short b;
- short c;
- char d;
- }test_32;
首先按照自然對齊,得到如下圖的內存分布位置,第一個格子地址為0,后面遞增。

編譯器將對空白處進行無效數據填充,最后將得到此結構體占內存空間為8字節,這個數值也是最大的數據類型short的2個字節的整數倍。
如果稍微調換一下位置的結構體
- typedef struct test_32
- {
- char a;
- char b;
- short c;
- short d;
- }test_32;
同樣按照自然對齊如下圖分布

可以看到按照自然對齊,變量之間沒有出現間隙,所以規則對齊也不用進行填充,而這里有顏色的方格有6個,也就是6個字節
按照規則對齊,6字節是此結構體中最大數據類型short的整數倍,因此此結構體為6字節,后面的空白不需理會,可以實際編譯一下運行,結果和分析一致為6個字節。
double的情況
我們知道32位處理器一次只能處理32位也就是4個字節的數據,而double是8字節數據類型,這要怎么處理呢?
如果是64位處理器,8字節數據可以一次處理完畢,而在32位處理器下,為了也能處理double8字節數據,在處理的時候將會把double拆分成兩個4字節數進行處理,從這里就會出現一種情況如下:
- typedef struct test_32
- {
- char a;
- char b;
- double c;
- }test_32;
這個結構體在32位下所占內存空間為12字節,只能拆分成兩個4字節進行處理,所以這里規則對齊將判定該結構體最大數據類型長度為4字節,因此總長度為4字節的整數倍,也就是12字節。
這個結構體在64位環境下所占內存空間為16字節,而64位判定最大為8字節,所以結果也是8字節的整數倍:16字節。這里的結構體中的double沒有按照自然對齊放置到理論上的8字節倍數地址處,我認為這里編譯器也有根據規則對齊做出相應的優化,節省了4個多余字節。
這部分各位可以按照上述規則自行分析測試。
數組
對齊值為:min(數組元素類型,指定對齊長度)。但數組中的元素是連續存放,存放時還是按照數組實際的長度。
如char t[9],對齊長度為1,實際占用連續的9byte。然后根據下一個元素的對齊長度決定在下一個元素之前填補多少byte。
嵌套的結構體
假設
- struct A
- {
- ......
- struct B b;
- ......
- };
對于B結構體在A中的對齊長度為:min(B結構體的對齊長度,指定的對齊長度)。
B結構體的對齊長度為:上述2種結構整體對齊規則中的對齊長度。舉個例子
- #include <iostream>
- #include <cstdio>
- using namespace std;
- #pragma pack(8)
- struct Args
- {
- char ch;
- double d;
- short st;
- char rs[9];
- int i;
- } args;
- struct Argsa
- {
- char ch;
- Args test;
- char jd[10];
- int i;
- }arga;
- int main()
- {
- cout<<"Args:"<<sizeof(args)<<endl;
- cout<<""<<(unsigned long)&args.i-(unsigned long)&args.rs<<endl;
- cout<<"Argsa:"<<sizeof(arga)<<endl;
- cout<<"Argsa:"<<(unsigned long)&arga.i -(unsigned long)&arga.jd<<endl;
- cout<<"Argsa:"<<(unsigned long)&arga.jd-(unsigned long)&arga.test<<endl;
- return 0;
- }
輸出結果:
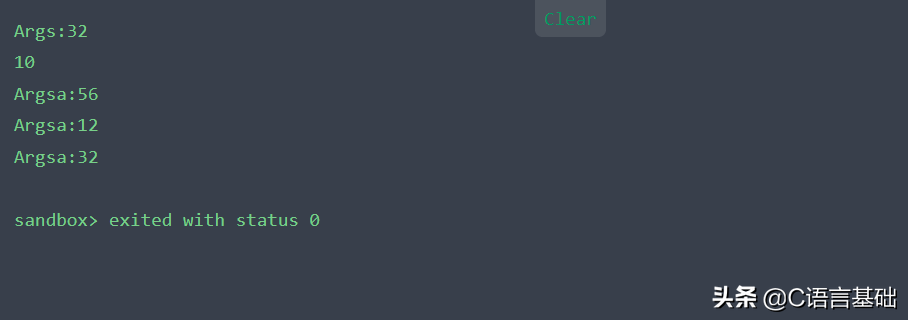
改成#pragma pack (16)結果一樣,這個例子證明了三點:
- 對齊長度長于struct中的類型長度最長的值時,設置的對齊長度等于無用
- 數組對齊的長度是按照數組成員類型長度來比對的
- 嵌套的結構體中,所包含的結構體的對齊長度是結構體的對齊長度
指針
主要是因為32位和64位機尋址上,來看看例子
- //編譯器:https://tool.lu/coderunner/
- //來源:技術讓夢想更偉大
- //作者:李肖遙
- #include <iostream>
- #include <cstdio>
- using namespace std;
- #pragma pack(4)
- struct Args
- {
- int i;
- double d;
- char *p;
- char ch;
- int *pi;
- }args;
- int main()
- {
- cout<<"args length:"<<sizeof(args)<<endl;
- cout<<"args1:"<<(unsigned long)&args.ch-(unsigned long)&args.p<<endl;
- cout<<"args2:"<<(unsigned long)&args.pi-(unsigned long)&args.ch<<endl;
- return 0;
- }
結果如下
pack48length3240args188args248
內存對齊的規則
1.數據成員對齊規則
結構或聯合的數據成員,第一個數據成員放在offset為0的地方,以后每個數據成員的對齊按照#pragma pack指定的數值和這個數據成員自身長度中,比較小的那個進行。
例如struct a里存有struct b,b里有char,int ,double等元素,那b應該從8的整數倍開始存儲。
2.結構體作為成員
如果一個結構里有某些結構體成員,則結構體成員要從其內部"最寬基本類型成員"的整數倍地址開始存儲。
在數據成員完成各自對齊之后,結構或聯合本身也要進行對齊,對齊將按照#pragma pack指定的數值和結構或聯合最大數據成員長度中,比較小的那個進行。
3.1&2的情況下注意
當#pragma pack的n值等于或超過所有數據成員長度的時候,這個n值的大小將不產生任何效果。
#pragma pack()用法詳解
- 作用
指定結構體、聯合以及類成員的packing alignment;
- 語法
#pragma pack( [show] | [push | pop] [, identifier], n )
- 說明
- pack提供數據聲明級別的控制,對定義不起作用;
- 調用pack時不指定參數,n將被設成默認值;
- 一旦改變數據類型的alignment,直接效果就是占用memory的減少,但是performance會下降;
- 語法具體分析
1.show:可選參數
顯示當前packing aligment的字節數,以warning message的形式被顯示;
2.push:可選參數
將當前指定的packing alignment數值進行壓棧操作,這里的棧是the internal compiler stack,同時設置當前的packing alignment為n;如果n沒有指定,則將當前的packing alignment數值壓棧;
3.pop:可選參數
從internal compiler stack中刪除最頂端的record;如果沒有指定n,則當前棧頂record即為新的packing alignment數值;如果指定了n,則n將成為新的packing aligment數值;如果指定了identifier,則internal compiler stack中的record都將被pop直到identifier被找到,然后pop出identitier,同時設置packing alignment數值為當前棧頂的record;如果指定的identifier并不存在于internal compiler stack,則pop操作被忽略;
4.identifier:可選參數
當同push一起使用時,賦予當前被壓入棧中的record一個名稱;當同pop一起使用時,從internal compiler stack中pop出所有的record直到identifier被pop出,如果identifier沒有被找到,則忽略pop操作;
5.n:可選參數
指定packing的數值,以字節為單位;缺省數值是8,合法的數值分別是1、2、4、8、16
例子
- #include<stddef.h>
- #include<iostream>
- using namespace std;
- #pragma pack(4)
- struct m
- {
- int a;
- short b;
- int c;
- };
- int main()
- {
- cout <<"結構體m的大小:"<< sizeof(m) << endl;
- cout << endl;
- // 獲得成員a相對于m儲存地址的偏移量
- int offset_b = offsetof(struct m, a);
- cout <<"a相對于m儲存地址的偏移量:"<< offset_b << endl;
- system("pause");
- return 0;
- }

從運行結果來看我們可以證實上面內存對齊規則的第一條:第一個數據成員放在offset為0的地方。
現在咱來看看上面結構體是如何內存對齊的;先用代碼打印它們每個數據成員的存儲地址的偏移量
- #include<stddef.h>
- #include<iostream>
- using namespace std;
- #pragma pack(4)
- struct m
- {
- int a;
- short b;
- int c;
- };
- int main()
- {
- cout <<"結構體m的大小:"<< sizeof(m) << endl;
- cout << endl;
- int offset_b = offsetof(struct m, a);// 獲得成員a相對于m儲存地址的偏移量
- int offset_b1 = offsetof(struct m, b);// 獲得成員a相對于m儲存地址的偏移量
- int offset_b2 = offsetof(struct m, c);// 獲得成員a相對于m儲存地址的偏移量
- cout <<"a相對于m儲存地址的偏移量:"<< offset_b << endl;
- cout << "b相對于m儲存地址的偏移量:" << offset_b1 << endl;
- cout << "c相對于m儲存地址的偏移量:" << offset_b2 << endl;
- //system("pause");
- return 0;
- }

在此c在結構體中偏移量為8加上它自身(int)4個字節,剛好是12(c的開始位置為8,所以要加它的4個字節)
上面內存結束為11,因為0-11,12是最大對齊數的整數倍,故取其臨近的倍數,所以就取4的整數倍即12;
上圖中我用連續的數組來模仿內存,如圖是它們的內存對齊圖;
如果將最大內存對齊數改為8,它將驗證內存對齊規則中的第3條。
如果將其改為2,會發生什么:我們來看看:
- #include<stddef.h>
- #include<iostream>
- using namespace std;
- #pragma pack(2)
- struct m
- {
- int a;
- short b;
- int c;
- };
- int main()
- {
- cout <<"結構體m的大小:"<< sizeof(m) << endl;
- cout << endl;
- int offset_b = offsetof(struct m, a);// 獲得成員a相對于m儲存地址的偏移量
- int offset_b1 = offsetof(struct m, b);// 獲得成員a相對于m儲存地址的偏移量
- int offset_b2 = offsetof(struct m, c);// 獲得成員a相對于m儲存地址的偏移量
- cout <<"a相對于m儲存地址的偏移量:"<< offset_b << endl;
- cout << "b相對于m儲存地址的偏移量:" << offset_b1 << endl;
- cout << "c相對于m儲存地址的偏移量:" << offset_b2 << endl;
- //system("pause");
- return 0;
- }
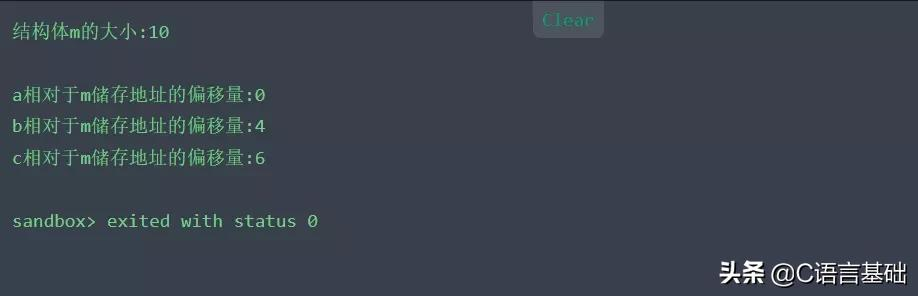
對于這個結果,我們按剛才第一個例子我所分析的過程來分析這段代碼,得到的是10;
故當我們將#pragma pack的n值小于所有數據成員長度的時候,結果將改變。
對齊的作用和原因
各個硬件平臺對存儲空間的處理上有很大的不同。如果不按照適合其平臺要求對數據存放進行對齊,可能會在存取效率上帶來損失。
比如有些平臺每次讀都是從偶地址開始,如果一個int型在32位地址存放在偶地址開始的地方,那么一個讀周期就可以讀出;
而如果存放在其地址開始的地方,就可能會需要2個讀周期,并對兩次讀出的結果的高低字節進行拼湊才能得到該int數據。那么在讀取效率上下降很多,這也是空間和時間的博弈。
CPU每次從內存中取出數據或者指令時,并非想象中的一個一個字節取出拼接的,而是根據自己的字長,也就是CPU一次能夠處理的數據長度取出內存塊。總之,CPU會以它“最舒服的”數據長度來讀取內存數據
舉個例子
如果有一個4字節長度的指令準備被讀取進CPU處理,就會有兩種情況出現:
4個字節起始地址剛好就在CPU讀取的地址處,這種情況下,CPU可以一次就把這個指令讀出,并執行,內存情況如下

而當4個字節按照如下圖所示分布時
假設CPU還在同一個地址取數據,則取到第一個4字節單元得到了1、2字節的數據,但是這個數據不符合需要的數字,所以CPU就要在后續的內存中繼續取值,這才取到后面的4字節單元得到3、4字節數據,從而和前面取到的1、2字節拼接成一個完整數據。
而本次操作進行了兩次內存讀取,考慮到CPU做大量的數據運算和操作,如果遇到這種情況很多的話,將會嚴重影響CPU的處理速度。
因此,系統需要進行內存對齊,而這項任務就交給編譯器進行相應的地址分配和優化,編譯器會根據提供參數或者目標環境進行相應的內存對齊。
什么時候需要進行內存對齊.
一般情況下都不需要對編譯器進行的內存對齊規則進行修改,因為這樣會降低程序的性能,除非在以下兩種情況下:
這個結構需要直接被寫入文件
這個結構需通過網絡傳給其他程序
對齊的實現
可以通知給編譯器傳遞預編譯指令,從而改變對指定數據的對齊方法。
- unsigned int calc_align(unsigned int n,unsigned align)
- {
- if ( n / align * align == n)
- return n;
- return (n / align + 1) * align;
- }
不過這種算法的效率很低,下面介紹一種高效率的數據對齊算法:
- unsigned int calc_align(unsigned int n,unsigned align)
- {
- return ((n + align - 1) & (~(align - 1)));
- }
這種算法的原理是:
(align-1) :對齊所需的對齊位,如:2字節對齊為1,4字節為11,8字節為111,16字節為1111...
(&~(align-1)) :將對齊位數據置位為0,其位為1
(n+(align-1)) & ~(align-1) :對齊后的數據
總結
通常,我們寫程序的時候,不需要考慮對齊問題,編譯器會替我們選擇目標平臺的對齊策略。但正因為我們沒注意這個問題,導致編輯器對數據存放做了對齊,而我們如果不了解的話,就會對一些問題感到迷惑。所以知其然,更要知其所以然。好了,我們介紹到這里,下一期再見!