世界超大的多語言語音數據集現已開源!超40萬小時,共23種語言
本文經AI新媒體量子位(公眾號ID:QbitAI)授權轉載,轉載請聯系出處。
最近,Facebook開源了目前世界上最大的多語言語音數據集,VoxPopuli:

這一數據集共涵蓋了23種語言,時長超過40萬小時。
其中,每種語言都有9000到18000小時的無標簽語音數據。
此外,還包括了共1800小時,16種語言的轉錄語音數據,以及17300小時,15種目標語言的口譯語音數據。
國外網友很快為這一行為點贊:
顯然,如果數據集已經存在,那么它應該被利用,并以一種道德的方式來改善人類社會。
這一數據集龐大的無標簽數據量和廣泛的語言覆蓋率,對改進自監督模型有著很大的幫助。
而Facebook也希望能夠幫助提高語音數據集的質量和魯棒性,使訓練語音轉換神經網絡更加可靠。
最終加速新的NLP系統的開發,使AI翻譯的效果越來越好。
而數據集的名字,VoxPopuli的直譯“人民的心聲”也表示了其原始數據的來源——
即源語音全都收集自2009-2020年歐洲議會的活動錄音。
來自10年歐會的語料庫
在歐洲議會的各自活動,如全體會議、委員會會議和其他活動上,發言者都會以不同的歐盟語言輪流發表演講。
Facebook就是從歐會官網上抓取了每個演講的文字記錄、演講者信息、開始/結束時間戳。
然后,將所有的原始演講數據進行處理,大致分為以下3類:
共40萬小時,23種語言的無標簽語音數據
每種語言都有8千到2萬多的原始語音數據。
因此,Facebook基于能量的語音激活檢測(VAD)算法,將完整音頻分割成15-30秒的短片段。
最終得到沒有太多的數據不平衡,也不需要調整數據采樣策略的數據集。
因此非常適合多語言模型的訓練。
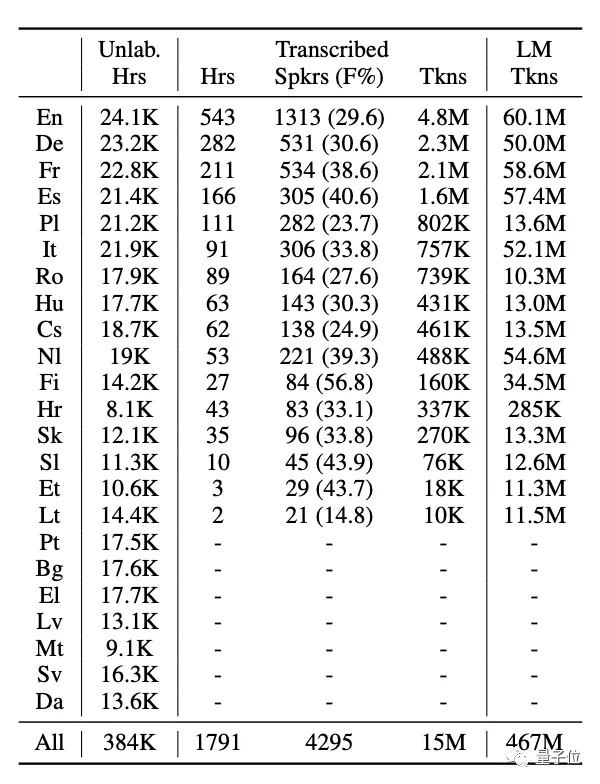
而上表中除了無標簽數據,也有轉錄的語音數據,這也就是第二種:
共1800小時,16種語言的轉錄語音數據
歐會官方的時間戳雖然可以用來在會議中定義演講者,但常常會被截斷,或混合前后演講的片段,因此并不完全準確。
所以Facebook對全會話音頻采用了聲紋分割聚類(SD)。
這時的語音段落平均時長為197秒,再利用語音識別(ASR)系統,將其細分為20秒左右的短片段。
觀察上表,可以看到最終得到的數據中,有包括各語言的持續時間、發言人數量、女性發言人百分比、標記數量等多種屬性。
17300小時的15種目標語言的口譯語音數據:
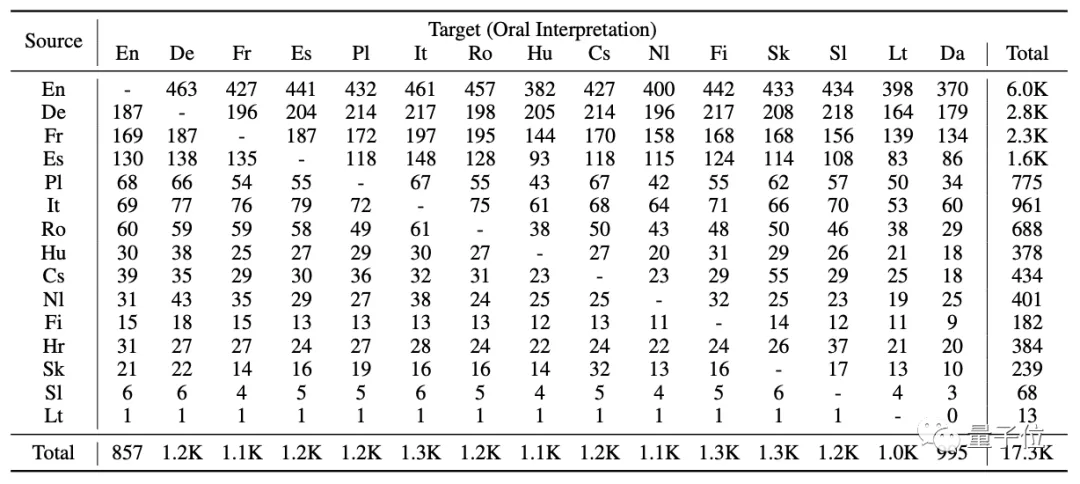
每個原始語音都有相對應的同聲傳譯,并互相關聯。
但要使這個數據集可用,必須經過大量的預處理和過濾。
因此,Facebook使用了語音識別(ASR)系統在句子層面上對齊源語音和目標語音。
在域外環境的半監督學習下具有通用性
那么這一數據集用起來到底怎么樣?
首先,是使用包含了域外語言(out-of-domain out-of-language)的無監督預訓練,進行少樣本的語音識別:
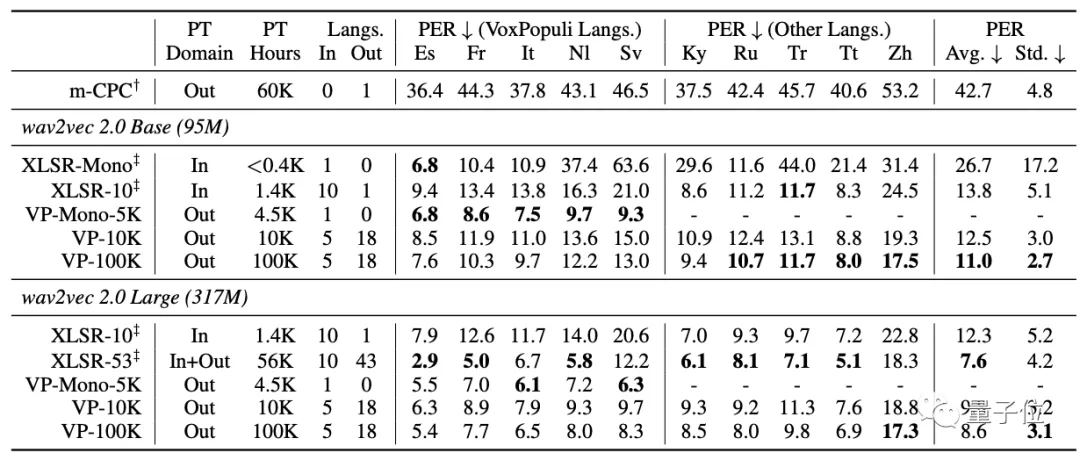
可以從表中看到,VP-Mono5K在5種VoxPopuli語言上,都優于XLSR-Mono和XLSR-10。
而VP-100K則在10種語言中的8種上的都比XLSR-10的表現更好。
并且,雖然XLSR-53涵蓋了Zh語言,但與VP-100K(Large)在Zh上的表現相距甚遠。
這表明VP-100K所學的語音表征具有高度的通用性。
然后是使用VoxPopuli數據集進行自我訓練或弱監督的語言翻譯(ST)和語音識別(ASR):
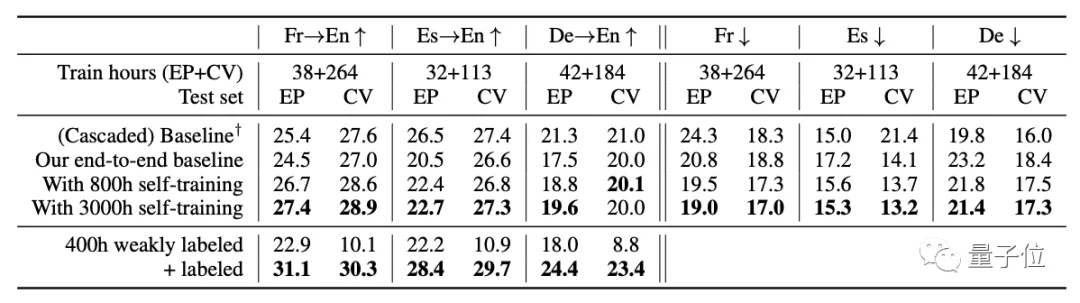
從表中可以看到,不管是對于域內語言還是域外語言,對VoxPopuli的自我訓練在大多數時候都能夠提高性能。
而在翻譯上,也不用再增加昂貴的標簽數據。
通過自我訓練,就能夠縮小端到端模型和級聯模型之間的差距。
論文地址:
https://arxiv.org/abs/2101.00390
下載:
https://github.com/facebookresearch/voxpopuli