ICML 獲獎者陸昱成:去中心化機器學習的理論極限在哪里?
本文轉自雷鋒網,如需轉載請至雷鋒網官網申請授權。
如何高效訓練大規模數據,一直是機器學習系統面臨的重要挑戰。
當下互聯網時代,數十億用戶每天生產著百億級規模的數據。作為AI煉丹的底層燃料,這些海量數據至關重要。然而,由于訓練數據和模型規模的增大,機器之間的通信成本越高,機器學習系統經常會出現高延遲、低負載的現象。
2004年,谷歌首次提出并行算法 Mapreduce,通過將大規模數據分發給網絡上的每個節點,實現了1TB以上的運算量。之后,AI科學家李沐又提出異步可擴展的Parameter Server算法,基本上解決了大規模數據的分布式訓練問題。
然而,近年來以 BERT 為代表預訓練模型,其體積規模不斷突破極限。動輒上百萬、甚至上億級參數量的超大模型,讓傳統分布式機器學習系統越來越難以高效運轉。基于此,業內普遍認為,去中心化(Decentralized )的分布式訓練方法將成為下一個“最優解”。
陸昱成向AI科技評論表示,隨著機器學習的應用越來越多樣化,中心化分布式系統的局限性也會越來越明顯,比如“中心節點負載過大”,“容錯性差”,“數據安全”等問題。如果設計好節點之間的協議,去中心化算法將有助于大幅提升系統的魯棒性。
陸昱成是康奈爾大學計算機系在讀博士,主要研究大規模機器學習系統,側重于隨機和并行算法。近日,他發表的一篇名為《Optimal Complexity in Decentralized Training》的研究論文獲得了ICML 2021杰出論文榮譽提名獎。
在這篇論文中,他主要研究了去中心化算法的理論極限,通過對D-PSGD(羅切斯特大學Ji Liu團隊提出)和SGP(Facebook AI Lab提出)等經典算法的系統性分析,推導出了隨機非凸環境下迭代復雜度的最優下界,并進一步提出DeTAG算法證明了該理論下界是可實現的。ICML組委會一致認為,這項研究成果推動了分布式機器學習系統在理論層面的發展。
1
去中心化:機器學習系統的最優解
“雖不及熱門領域諸如NLP等備受媒體追捧,但在‘煉大模型’這股浪潮的驅動下,去中心化已經成為機器學習系統領域的熱門研究方向”。陸昱成表示。
去中心化并不是一個全新的概念,它在金融、移動互聯網、云計算等領域早已有了廣泛的應用。只是最近五年來才逐漸部署到人工智能領域。例如,應用于金融服務的區塊鏈技術,采用的是去中心化的理念;用于優化計算機網絡負載和容量的點對點拓撲結構,依靠的也是去中心化的思想。
在機器學習系統中,中心化是指由一個節點管理所有計算機機器之間的數據交互與同步。而去中心化,則強調所有節點都是平等的,它不圍繞任何一個節點做中心化的設計。實驗證明,不同節點之間的信息交互也可以達到與集中式交互類似的效果,甚至訓練出無損的全局模型。
谷歌于2017年推出的FedAvg算法,是一種典型的去中心化聯邦學習架構。它以中心節點為server(服務器),各分支節點為本地的client(設備)。其運算模式是在各分支節點分別利用本地數據訓練模型,再將訓練好的模型匯合到中心節點,獲得一個更好的全局模型。
在本地訓練移動端數據,而無需用戶向外發送信息,是數據層去中心化的一個典型應用。分布式機器學習系統是可以看做一個棧式結構,包括數據、應用、協議、網絡拓撲等不同的層。
這些層通過不同的去中心化設計,可以適應不同的應用場景。D-PSGD是擴展隨機梯度下降(SGD)最基本算法之一,也是應用于協議層的一種典型去中心化算法,可實現線性并行加速。
雖然學術界已有一些成熟的去中心化算法,但落地工業級別的去中心化系統仍處于初步階段。傳統的機器學習框架諸如Facebook的Pytorch,谷歌的TensorFlow,亞馬遜的MXNet仍采用的是Parameter Server或AllReduce等中心化解決方案;但一些初創公司如Openmined等則已將去中心化作為其機器學習系統的一部分。
陸昱成認為,在接下來的幾年內,不同層的去中心化設計會成為擴展機器學習/深度學習在不同場景下應用的關鍵因素。其原因在于三點:
1. 在數據中心和集群式的模型訓練中,去中心化的設計提供了良好的容錯性和魯棒性,并減少了不同機器間的帶寬需求;
2. 去中心化可以為更多場景下的AI落地提供可能,比如近年來不斷發展的終端設備學習就是應用層去中心化的典型設計;
3、去中心化在分布式系統領域有大量關于協議層和安全性的研究,為其在機器學習領域的發展奠定了理論基礎。
從現有研究成果來看,陸昱成認為,類似于D-PSGD的眾多分布式算法在收斂速度方面仍存在理論差距,尤其是在隨機非凸環境下,其迭代復雜度的極限仍是一個未知數。而關于這一問題的探討,讓他獲得了ICML 2021杰出論文提名獎,并為機器學習系統的理論發展做出了貢獻。
2
理論下界:迭代復雜度的極限

論文地址:https://arxiv.org/abs/2006.08085
在這篇論文中,陸昱成團隊提供了去中心化分布式系統的一個最優的理論下界,并通過DeTAG和 DeFacto兩個算法證明了該下界是可實現的。
通信復雜度和網絡延遲是衡量機器學習模型在訓練過程是否高效的重要指標,二者展示了去中心化系統在運算過程中,每個節點的迭代次數和收斂速度,而下界則代表了這種迭代復雜度的理論極限,即在處理任意一個任務時,去中心化系統所需要最低迭代次數。
在陸昱成看來,任何一個最優算法的設計都需要理論下界的指導。“如果沒有下界的指導,我們其實并不知道現有算法的提升空間在哪里。只有明確一個極限,不斷趨近于極限,才能設計出接近最優的算法”。也因如此,這篇研究論文更注重機器學習系統優化的理論創新。
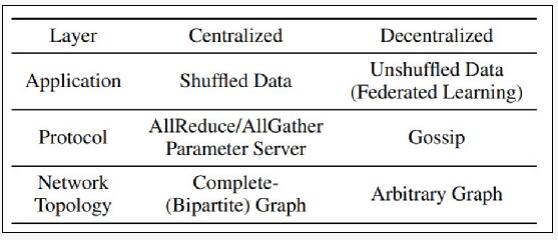
DeTAG算法是包含應用層、協議層、網絡拓撲層的棧式結構。陸昱成介紹稱,他們在算法設計過程中使用了一些去中心化的常見技巧,比如梯度追蹤,階段式通信和加速化的Gossip協議。
基于這些技巧,他們最大貢獻就是發現了一個最優的理論下界,并且提出了一個可以分析去中心化算法復雜度的理論框架。
實驗證明,DeTAG算法只需一個對數間隔即可達到理論下限。在論文中,陸昱成團隊將DeTAG與D-PSGD、D2、DSGT以及DeTAG等其他分布式算法在圖像分類任務上進行了比較,結果表明,DeTAG比基線算法具有更快的收斂速度,尤其是在異質數據和稀疏網絡中。
1、在異質數據上的收斂性
在許多應用場景中,節點間數據往往并不服從同一分布。在實驗中,當不同節點間數據完全同質時,除了D-PSGD的收斂速度略慢外,其他算法幾乎相差不大;當不同節點數據的同質程度為50%-25%時,DeTAG算法的收斂速度最快,而D-PSGD即使微調的超參數也無法收斂;當數據的同質程度為零時,DSGT獲得了比D2更穩定的性能。
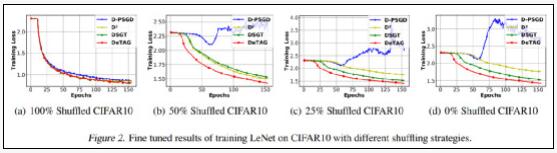
圖注:0%、25%、50%、100%代表不同的同質程度
2、在不同稀疏性通信網絡上的收斂性
與基線相比,在不同的控制參數(κ=1、0.1、0.05、0.01)下,DeTAG具有更快的收斂速度;此外,當網絡變得稀疏,即參數K減小時,DeTAG具有更穩健的收斂性。
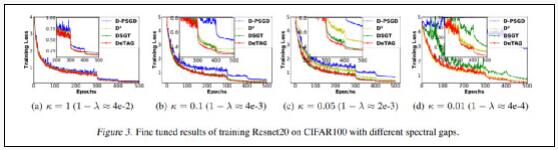
陸昱成表示,DeTAG算法通過優化不同節點之心的通信過程,在一定程度上實現了負載均衡,提高了系統的容錯率。同時也驗證了去中心化算法在優化分布式機器學習系統方面的潛力——機器學習的范圍不再局限于云端,或者大規模集群,而是可以從更廣的范圍上擬合更多的終端數據。
3
ICML獲獎者
陸昱成是康奈爾大學計算機科學系三年級博士生,師從 Chris De Sa.教授。主要研究如何優化分布式機器學習系統,集中于系統性能,通信壓縮、去中心化、采樣算法等方向。
在博士期間獲得頂級學術會議獎項的學生并不多見,尤其是ICML、CVPR、ACL等主流會議。作為機器學習領域的最熱門的頂會,ICML 2021共收到有效投稿5513篇,接受1184篇,接受率僅為21.48%。
這次大會頒發了一篇杰出論文獎,四篇杰出論文榮譽提名獎,其中陸昱成(第一作者)是唯一一位獲獎的華人博士生。另外一位獲獎的華人學者是Facebook AI 科學家田淵棟。
陸昱成本科就讀于上海交通大學,后來前往康奈爾大學攻讀博士。讀博后,他的研究方向開始聚焦于去中心化算法,并接觸一些更有挑戰性和影響力的課題。在微軟和AWS AI Lab 實習期間,他從采樣和通信壓縮的角度探討了如何優化分布式訓練算法。
通常來講,博士階段的研究更適合從小眾而具體的選題開始做起,以便培養科研信心,循序漸進為之后的研究積累經驗。在談到為何一開始便選擇熱門的去中心化算法時,陸昱成表示,從個人角度來講,第一篇論文從簡單易出成果的研究入手,建立自信心是非常必要的,但同時我們也應該有意識地為自己的研究逐級增加難度,擴大問題的主線。
另外,不同于計算機視覺、自然語言處理等研究更偏向工業界,優化算法領域的工作通常更注重基礎理論。工業界和學術界要的研究需求是不一樣的。除了理論層面外,也可以從非算法角度可以挖掘一些選題。