圖解分布式一致性算法
今天的文章,咱們會通過圖的方式,來深入學習和理解分布式一致性的實現原理。
開始的時候,咱們先來靈魂一問:什么是分布式一致性?
- 你的應用是單節點嗎?
- 你的系統用戶多嗎、支持擴容嗎?
- 你的系統擴容后數據能保持一致嗎?
- 你的系統是否使用Raft、Paxos?
- ……
是否理解都沒關系,后面開始咱們的例子,通過圖的方式,來描述一致性的工作原理。
一、前奏
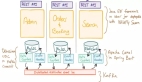
假設咱們有個系統。是個單節點的系統,只部署在一個實例上。可以把它理解成一個數據庫服務(Database Server),實例上只有一個數據X,咱們后續的故事都是要圍繞操作變更X的值開展的。
咱們還有個客戶端(Client),它要向節點 (Server) 寫數據,這個時候應用代碼寫起來也簡單,這個數據的一致性很容易保證。


寫請求執行后,客戶端和服務端的X數據都變成了8。
在用戶量少的時候,還天天操心啥時候來個百萬千萬用戶,等用戶稍微一多起來才發現,原來的一個實例扛不住了。這個時候為了支持更多用戶訪問,又擴容出來了更多的實例。

那么這下問題來了,當我們有多個實例節點間的時候,客戶端向其中一個節點寫了數據,如何再同步給其他節點呢?怎樣保證節點間數據的一致性呢?這就是分布式一致性問題。
二、 Raft 協議概覽
Raft 就是一個解決上述分布式一致性問題的協議。類似的協議還有Paxos、Zab等等。相比 Paxos,Raft 更易理解和實現。
咱們本次會俯瞰 Raft , 來了解其工作原理。
在 Raft 里, 節點可能存在三種狀態:
- Follower
- Candidate
- Leader
在后面的圖里內容中,上述三種狀態分別和下面三個圖一一對應。
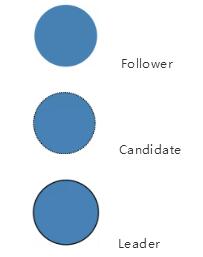
任何時候,都只會處于上述三種狀態中的一種。初始時候,所以節點都處于 Follower狀態。

如果follower 節點不再能接收到 leader 節點的消息, 他們的狀態就會變成 Candidate。

Candidate 節點會向其他節點發起投票請求,

其他節點也會投票進行響應。

如果獲得了多數節點的投票,那 Candidate節點會成為Leader。

上面的這個過程就是分布式一致性協議中的「選舉」(Leader Election)。
后續所有對于系統的變更,都是通過Leader進行的。經由 Leader 再到達其他節點。
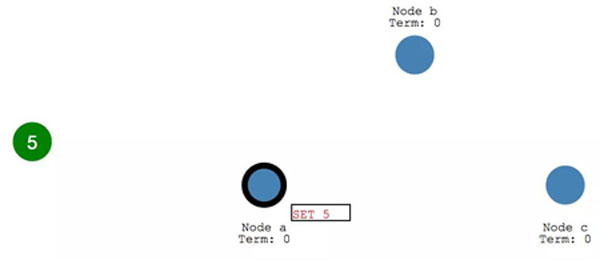
每次 Client 的變更請求到達 leader 時,都會視為一個 Entry ,先添加到節點的日志 (Log)里。這個新增的 log entry,目前還并沒有提交,所以不會真的更新節點里 X 的值。

leader 首先會復制 log entry 給所有 follower節點。

然后, leader 會等待,直到多數節點都寫入了entry。

在收到多數節點的寫入響應之后, leader 節點會將 entry 提交,此時 leader節點的值變成了 5.
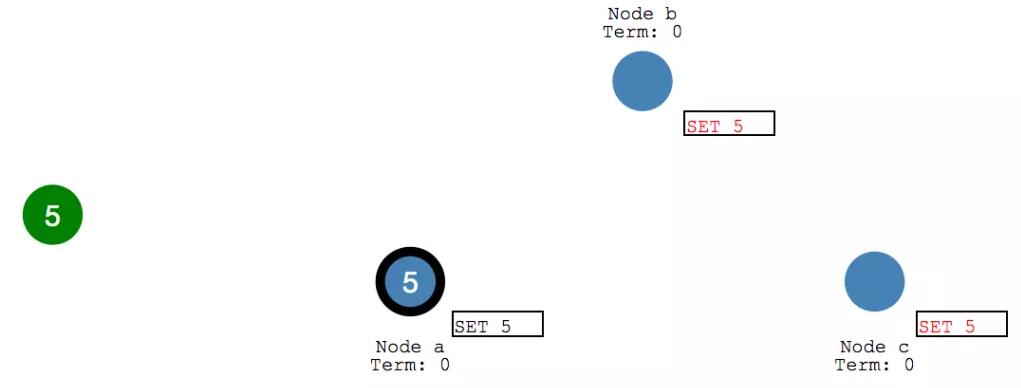
然后 leader 會通知 follower 節點 自己的 entry 已經提交了。

此時各個 follower 節點也會將之前收到的entry 進行提交。

整個系統目前所有的集群節點都達到了一致的狀態。這個過程一般稱為日志復制(Log Replication)。
三、 Leader Election
Raft 里有項控制選舉的超時時間設置。選舉超時時間是一個follower變成 candidate 的等待時間。值是150ms到300ms間的一個隨機值.

在選舉超時后, follower 會變成 candidate 開始一個新的選舉周期(term),同時會給自己投一票。

并且給其他節點發送請求投票的消息。

如果收到消息的節點在這一個周期還沒有投過票,那他需要給 candidate 投一票,并且該節點重置他的選舉超時時間。

如果 candidate 收到大多數節點的投票,就會成為leader。

leader 此時會在心跳檢測的周期內,給給所有的follower發送Append Entries messages 。檢測的頻率是通過心跳超時時間設置的。

然后 每個 follower 也會給 Append Entries message 發送響應。

這個選舉周期會一直持續直到某個 follower 停止心跳消息接收變成 candidate。

我們停掉 leader 再來看一下重新選舉的情況。
此時 節點 B 已經停止,所以 節點A 和節點C 都收不到心跳消息。咱們前面說收不到心跳消息的話,節點的狀態會從 Follower 變成 Candidate,所以A 和C 在各自的選舉超時時間設置內會改變狀態,

此時,節點 A 和 節點 C 都在等待,由于節點C先超時,所以會先開始一輪選舉。和上面的選舉過程一樣,會先新增Term,給自己投一票,并發送投票請求給其他節點。
在收到節點A的投票后,節點C現在升級為 term 2的 leader。

咱們前面總在說的「大多數節點投票」(a majority of votes)。這個能保證能在一個投票周期內,只會產生一個 leader。
假設兩個節點同時從 Follower 狀態變成了 Candidate,這個時候兩者都會升級 Term,并請求其他節點不給自己投票。


這個時候兩者的 Term 其實是相同的,在同一個 Term 內 其他節點只會投出一票,所以每個 Candidate 都只會收到一個節點的投票。


因為沒有超過「大多數」,所以都會不能成為 leader。這些節點就會等待新一輪的選舉,此時節點D先開始發起投票,并收到了大多數的投票,所以在Term 5 最終成為 leader。

四、 Log Replication
在選舉出一個leader之后,就需要復制所有的變更信息到系統里的所有節點。這些是通過和心跳檢測相同的的Append Entries message 來完成的。

我們來看下這個過程。一開始, client會向leader發送一個變更。

這個變更會加到 leader的log中,并會在下一次心跳檢測的時候發給 follower。

follower在收到消息之會,都會給 leader 發送響應的 ack消息。

收到大多數的 follower 響應之后, leader 會提交這個entry,并且發送響應給 client。


并在下次心跳的時候,通知 follower 們執行提交操作。

follower 在寫入完成后再給 leader 發送響應。
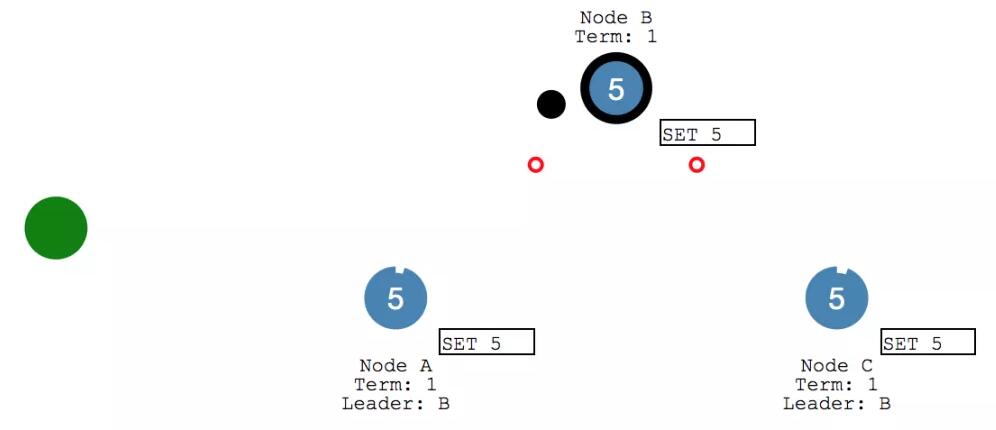
此時 Client 又給給 leader 發送消息,要給X 來執行個 加2 的操作。leader 將消息添加到 log 之后,給各個follower 發送心跳。
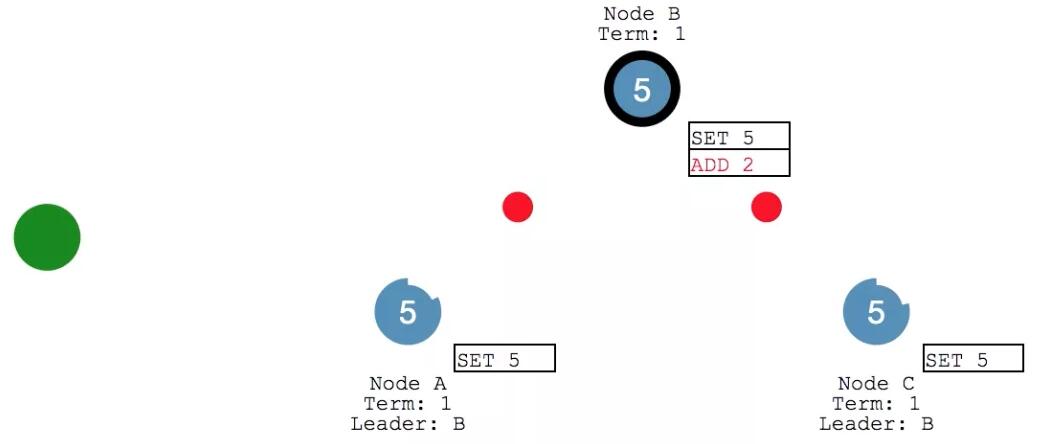
follower 們收到之后繼續返回響應。
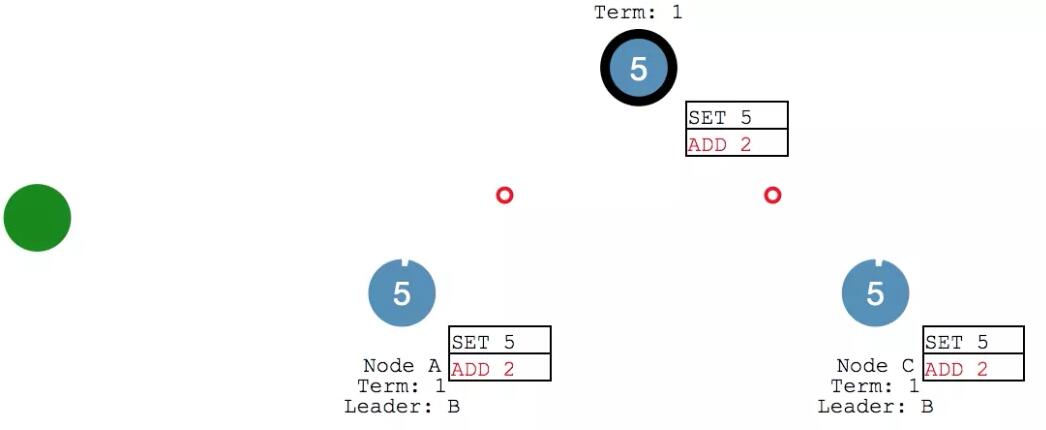
leader 收到 ack 之后,確認本次執行進行 commit ,然后給 client 發回響應。并在下次心跳的時候,把寫入發給各個 follower。
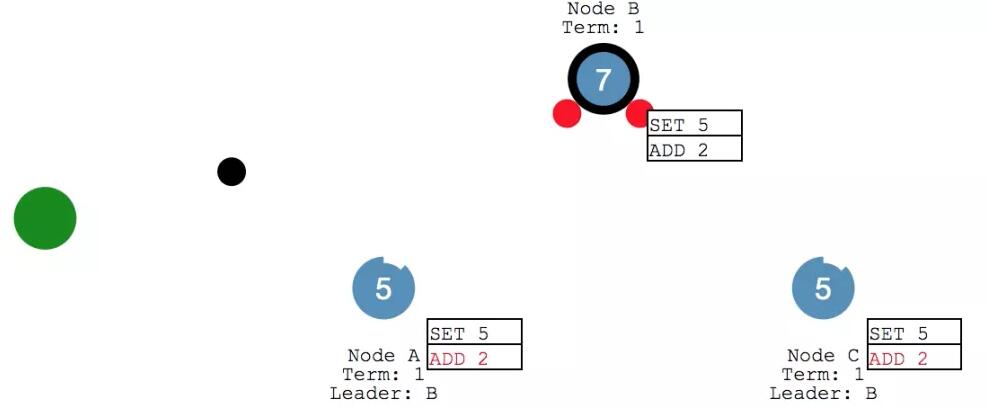
此時,咱們的系統里 X變成了7,各個節點的數據保持一致。
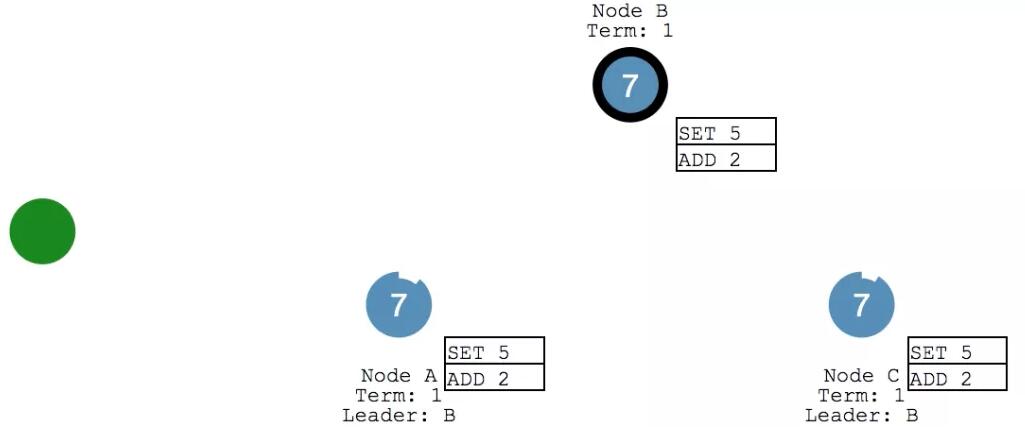
五、「大多數」是多少?
前面許多場景咱們都提到「大多數」。那大多數到底是多少呢?
比如我們在選舉的時候,在日志復制的時候,都需要大多數 follower 發送回響應消息。
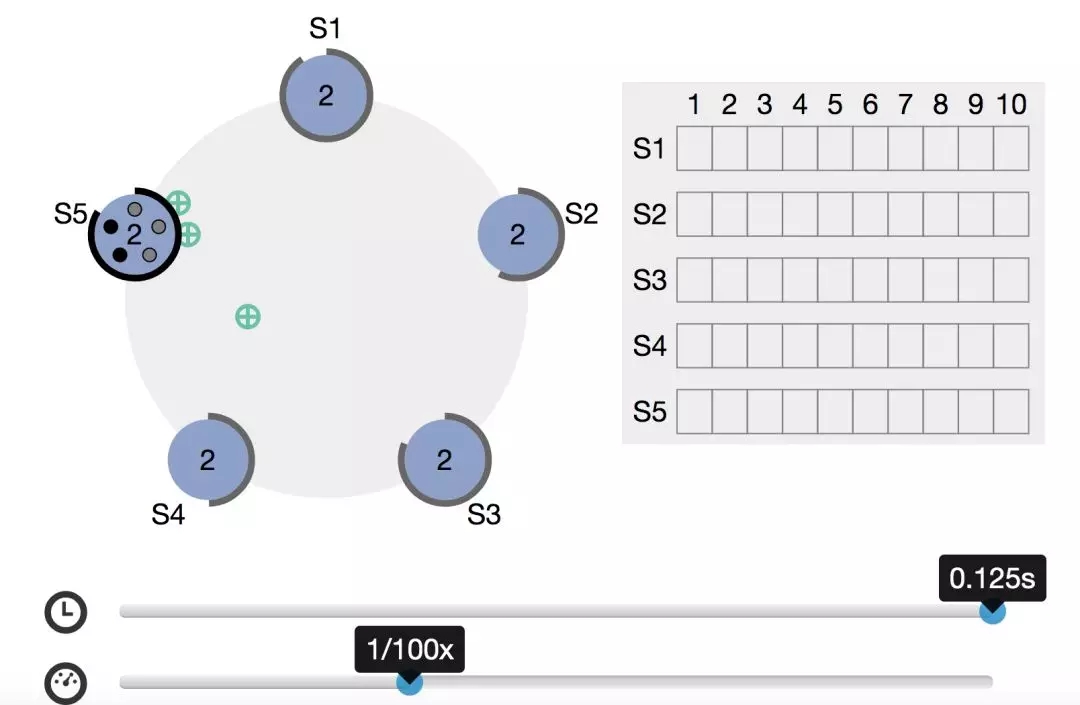
這里的大多數和咱們日常生活里的基本一致,即超過半數。比如一共有5個節點,此時有一個 candidate 起成為 leader,在投票過程中,至少要收到3個投票才行。
官網有個可以自定義時間進行交互的動圖,感興趣的朋友可以自行查看。
【本文為51CTO專欄作者“侯樹成”的原創稿件,轉載請通過作者微信公眾號『Tomcat那些事兒』獲取授權】