













一文讀懂一條查詢語句的宿命
select * from XXX where id=1;
這應該是n年前入門mysql必用的查詢語句了吧,學如逆水行舟,不進則退,這么久過去了,你知道這條語句在Mysql內部的執行過程嗎?
我們先來看看司空見慣的Mysql基本架構示意圖
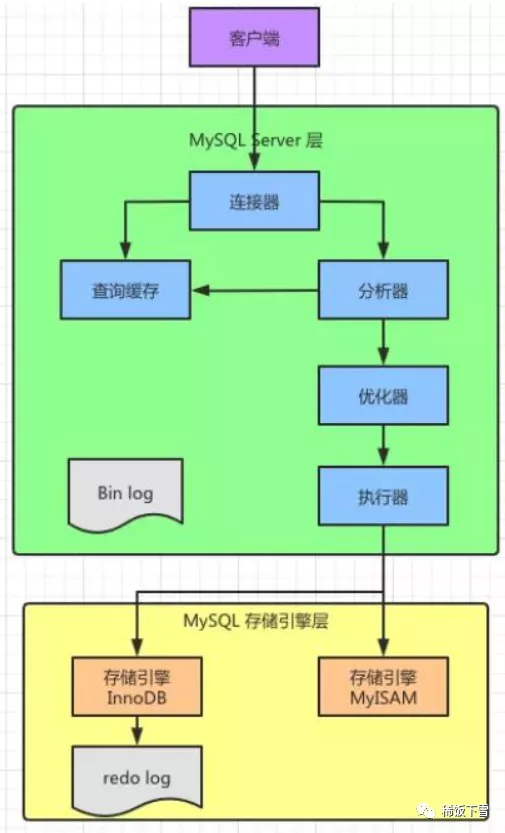
可以看到,Mysql可以分為
- Server層,包括連接器、查詢緩存、分析器、優化器、執行器等,除了直接落地到磁盤、和從磁盤提取數據外的所有能力。
- 存儲引擎層,負責了數據的讀取和存儲,支持InnoDB、MyISAM、Memory等多個存儲引擎,默認的是InnoBD。
結構大概講完了,有沒有感覺,Mysql就像一個大型的加工廠,你把原材料,也就是sql語句放進去,然后Mysql就轉動起來,從頭到尾給你加工,最后得出一款產品,也就是執行結果。
嗯,這個比喻好,確實他媽的像,那么這個加工廠具體做了啥呢?
連接器小妹妹
首先,我們都會使用連接命令連上mysql
mysql -hip-pport -u$user -p
這個時候,出來接待我們的就是連接器小妹妹了
連接器小妹妹負責跟我們進行了典型的TPC握手,然后開始問我們的身份,要拿芝麻開門什么的密碼來驗證我們是否有權限,如果賬戶或者密碼錯誤了,則會直接跟我們說
"Access denied for user“
驗證通過了,則我們和連接器的連接便成功簡歷了,可以使用
show processlist
查看連接的狀態

其中Sleep狀態表明是空閑連接
連接建立后,連接器小妹妹還會告訴我們一些規則,比如
如果連接太長時間沒動靜,則會自動將連接斷開,默認是8個小時
如果連接被斷開了,等我嗎再次發送請求的時候,連接器小妹妹則會告訴我們
Lost connection to MySQL server during query
那么能改嗎?
可以的,只需要我們告訴連接器小妹妹,將wait_timeout的參數修改一下就可以了
聽起來都是長連接,那么能進行短連接嗎?
可以的,連接器小妹妹說了:
如果你們和我建立長連接的話,連接成功后,你們后續有請求,都會一直使用同一個連接。但是如果是短連接,則每次執行完很少的幾次操作后我就要就斷開連接了,下次再來你們再建立一次連接吧
我們也可以看到,其實和連接器小妹妹建立連接的過程是挺麻煩的,所以平常我們盡量會減少這個行為,一般都會使用長連接。
但是啊,有時候用著用著,mysql這邊內存漲的特別快,這是為什么呢?我特地問了連接器小妹妹,她告訴我
mysql在執行過程中臨時使用的內存是管理在連接對象里邊的,而這些對象只有在連接斷開的時候才釋放,所以內存占用越來越大,最后有可能被系統強行干掉了,也就是OOM
丟,這么嚴重,那么我到底用長連接還是短連接呢?
肯定是長連接啦,別急,還是有解決辦法的,我們這邊給了兩個方案
- 定期斷開長連接,使用一段時間,或者程序里面判斷執行過一個占用內存的大查詢后,斷開 連接,之后要查詢再重連。
- 如果你用的是MySQL 5.7或更新版本,可以在每次執行一個比較大的操作后,通過執行mysql_reset_connection來重新初始化連接資源。這個過程不需要重連和重新做權限驗證, 但是會將連接恢復到剛剛創建完時的狀態。
到了這里,連接器小妹妹的活就干完了,后面出來接待我們的是緩存查詢小哥哥。
緩存查詢小哥哥
緩存查詢小哥哥也比較簡單,一來就將我們的sql語句拿去做對比,他那邊有個字典,用key-value的格式記錄著查詢過的key和結果,而他的做法也極其簡單,只要找到一樣的,則將結果給回我們了,只有當找不到記錄,才會繼續走后面的流程,然后繼續記錄到字典內。
這個時候,我就很疑惑了,如果實際上數據更新了,但是你的字典還是舊的怎么辦呢?
緩存查詢小哥哥說了,這個不用擔心,字典上會記錄著查詢記錄對應的表,如果對應的表有了更新,我這邊就會將記錄全部清空掉的。
哦,這樣子,那么如果是更新比較頻繁的情況,可能你的作用也不大哦哈哈哈
是的,你們可以通過
query_cache_type = DEMAND
將關閉掉的,而且在8.0開始,我已經被移除啦。
說完緩存查詢小哥哥流下了悲傷的淚水,是啊,畢竟跟不上時代的技術,被淘汰也是難免的。
緩存查詢小哥哥說完,便將另一位小哥叫了出來,這位小哥叫分析器。
分析器小哥哥
分析器小哥哥在拿到sql語句后,就開始自己搗鼓了起來,那么他具體做了啥呢?我們在旁邊看搗鼓了很久,其實他就做了兩步
第一步,詞法分析,就是從SQL 語句中提取關鍵字,比如:查詢的表,字段名,查詢條件等等。
第二步,語法規則,就是判斷SQL語句是否合乎MySQL的語法。
通過分析器小哥哥做的事情,我也明白了,其實詞法分析就是將整個SQL語句拆分成一個個單詞,而語法規則則根據MySQL定義的語法規則生成對應的數據結構,并存儲在對象結構當中。
舉個例子,假設有這樣一個SQL語句“select id from XXX”。
先通過詞法分析,從左到右逐個字符進行解析

然后再通過語法規則解析,判斷輸入的SQL 語句是否滿足MySQL語法,并且生成語法樹,語法樹大概是這樣的
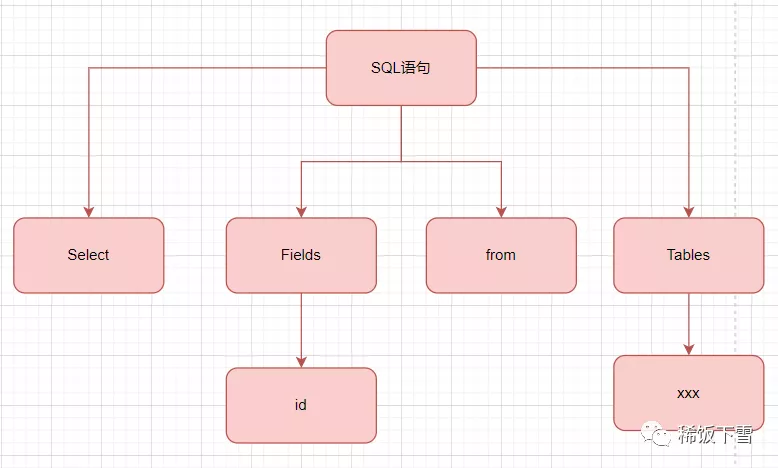
優化器小姐姐
到了這里,優化器小姐姐已經知道我們要干嘛了 畢竟分析器小哥哥已經幫他分析好了,只是可能我們的語句不夠優美,所以才需要知心的優化器小姐姐來做優化。
知心小姐姐怎么做的呢?我們看到小姐姐先將SQL語法樹拿了出來,然后就開始工作了起來,不得不說,小姐姐工作的樣子是真的好看,那么她具體做了啥呢?
在全程圍觀的我們,看到了她大概做了兩件事
- 邏輯變化
- 代價優化
邏輯變化是啥呢?邏輯變換就是在關系代數基礎上進行變換,其目的是為了化簡,同時保證SQL變化前后的結果一致,也就是邏輯變化并不會帶來結果集的變化。
其主要包括以下幾個方面:
- 否定消除:針對表達式“和取”或“析取”前面出現“否定”的情況,應將關系條件進行拆分,從而將外層的“NOT”消除。
- 等值常量傳遞:利用了等值關系的傳遞特性,為了能夠盡早執行“下推”運算。“下推”的基本策略是,始終將過濾表達式盡可能移至靠近數據源的位置。
- 常量表達式計算:對于能立刻計算出結果的表達式,直接計算結果,同時將結果與其他條件盡量提前進行化簡。
總結下來就是替換和預處理啦。
代價優化呢?代價優化是用來確定每個表,根據條件是否應用索引,應用哪個索引和確定多表連接的順序等問題,為了完成代價優化,需要找到一個代價最小的方案。
可以這說,我們要執行的查詢都是通過代價優化來計算出來的,最終得出了最小代價計劃去執行。
優化好后,接下來就是我們的執行器大哥出馬了。
執行器大哥
到了這一步,就要準備執行了,開始執行的時候,執行器大哥會一臉嚴肅的翻看他的權限寶典
查看我們是否有執行查詢的權限,如果沒有,則會直接告訴我們
SELECT command denied to user 'root'@'localhost' for table 'XXX'
如果驗證沒問題,他則會根據表的引擎信息,判斷要調用哪種引擎接口
例如SQL:select * from XXX where id=1;
假設 “id“ 字段沒有設置索引,就會調用存儲引擎從第一條開始查,如果碰到了id是1, 就將結果集返回,沒有查找到就查看下一行,重復上一步的操作,直到讀完整個表或者找到對應的記錄。
執行器還畫了個草圖解釋了他一貫的執行順序
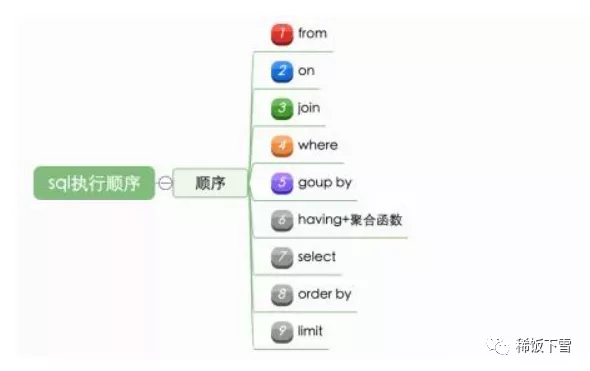
最后
一條查詢命令到了這里就算結束了,大致介紹了查詢請求的執行流程,引入了連接器、查詢緩存、分析器、優化器、執行器幾兄弟的分工合作,最后,我們為即將消失的查詢緩存器弟弟默哀三分鐘......
本文轉載自微信公眾號「稀飯下雪」

























