開源大數據Meetup回顧 | 第四范式:現代存儲架構下的系統優化實踐
8月21日,白玉蘭開源聯合示說網主辦的“開源大數據技術線上meetup”特邀約大數據領域的前沿技術專家,就大數據存儲的關鍵技術、挑戰和當前應用展開交流討論,陣容強大、內容全面。第四范式體系架構科學家,高性能計算Team leader盧冕,一直專注于研發在異構架構下的系統優化實踐和探索,我們根據盧冕講師的現場分享《現代存儲架構下的系統優化實踐》,整理成以下內容。
一、前言
隨著存儲技術的發展,現代存儲架構呈現出了前所未有的分級復雜性和功能上的革命(比如內存數據持久化),因此也對上層軟件如何優化提出了新的挑戰。
本次分享基于我們的實踐經驗,從現代存儲架構的概念、特征工程數據庫在PMem上的優化、基于分級存儲架構的Kafka優化、MemArk技術社區這四個方面出發,演示如何在現代存儲架構下,通過創新性的技術,比如持久化內存數據結構、分級存儲、冷熱數據分離等技術進行系統優化,以利用現代存儲架構的特性。
一、現代存儲架構
首先著眼于關鍵存儲技術:硬件技術、軟件技術,在此可劃分成外存和內存。
1外存
例如SSD、硬盤,即數據可以在該設備上持久化。1956年已出現機械硬盤,NAND Flash在1989年開始首個專利申請。如今,Flash已經發展迅猛、應用廣泛,例如B+tree數據庫系統在1973年已繁榮發展。
2內存
直接將數據存儲并且讀寫較快,但是掉電會造成數據丟失。內存的典型技術,例如SRAM、DRAM,其中SRAM用于CPU的cache,DDR、GDDR普遍應用于計算機。由于追求高性能、高吞吐,特異化的內存技術應運而生,例如,HBM2、GDDR6,上述都是高帶寬、高吞吐的內存形態,在家用機器上運用較少,較多運用在數據中心和大密度計算。
在2015年,數據可持久化和高性能易失性內存出現在交匯融合,非易失性內存技術由此進入大眾視野。該技術是存儲架構的革命性變化。
3非易失性內存技術
2015年,英特爾和鎂光在工業界共同提出了3D XPoint,目的是為了把非易失性內存技術落實到工業界,而不是僅限于學術界的模擬研究和討論。
2018年,英特爾把非易失性內存技術實現了商業化,推出了傲騰持久內存,這意味著非易失性內存真正實現了落地,能圍繞商業化產品去做工業級應用,而不是止步于紙上談兵。
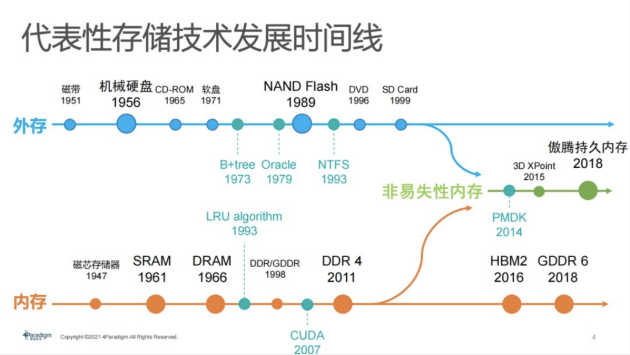
4現代存儲架構金字塔
Computer Science課本中也會碰到過存儲架構金字塔,其組織架構較簡單。在課本上,底層是硬盤,中間是DRAM或者叫內存,上面是cache。實際上,今天工業界存儲架構金字塔已經演化得非常復雜,它不再是課本上簡單的兩三級結構,已演化到六七級,此處還不包括異構算力所帶來的存儲架構。
如圖:金字塔下面藍色部分具有持久性,上面紅色部分是存儲介質。最特殊的是,中間部分非易失性內存或者持久內存商品,這一部分在金字塔用兩種不同顏色已標注。內存數據的持久化特性具有革命性,是現今存儲架構的顯著特點。
5非易失性內存
下圖就是英特爾推出的傲騰持久內存(PMem)第一代和第二代。該內存條和普通的內存條沒太大區別,可直接插在server上的內存插槽里,但只能匹配英特爾CPU。
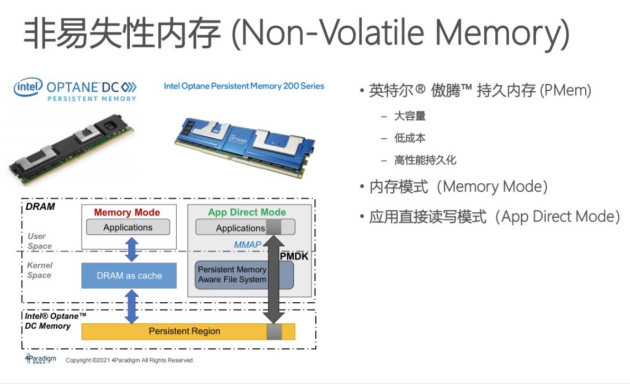
傲騰持久內存的顯著特點:
·大容量:單根容量可達到512 GB,在server上很容易把它配到T級別的容量,即1.5T或3T容量的PMem服務器配置。
·低成本:單位價格即每GB成本比普通DRAM低。如果從 server角度去思考問題,例如,如果用DRAM去跑3T的應用,可能至少要七八臺機器;如果用PMem機器去跑,它只需要一臺機器。從機器數量和運營成本節省角度而言,低成本特征顯著。
·高性能持久化:內存數據持久化。把傳統軟件中的內存數據做持久化,具有快速恢復的意義。此外,也可作為存儲,其性能相比較于HDD、SSD,性能優勢明顯。
持久內存的工作模式:Memory Mode,即內存模式,持久內存直接插到server上,對應用程序是黑盒化的。整個server容量會變成持久內存的容量,DRAM會變成持久內存的一層cache。內存容量就是整個PMem的容量,應用程序不需要修改代碼便可直接使用,直接享受大容量低成本的好處。但是這種模式可能會造成幾個問題,存儲架構的層級對程序員透明,程序員無法精確操控存儲架構層級,從而無法去做細粒度優化,例如cache層級優化。為了克服以上問題,推了APP Direct Mode。在APP Direct Mode,可以看到從PMem到DRAM內存整個存儲層級完全暴露在程序員視角下,程序員可以根據它的應用去做定制化優化,也能享受到持久化所帶來的好處。
綜上所述,現代存儲架構的特點:分級存儲架構復雜且豐富。現今存儲層級已達5-7層,這會讓大眾在容量、性能和成本之間權衡利弊,即在容量、性能、成本之間取舍。挑戰在此也迎面而來,即做優化。引入分級存儲、分級持久化等分級緩存算法來更好地做系統優化。
在此強調的是:內存數據持久化,這是革命性功能。如果把PMem當做內存使用,一旦機器掉電或者程序崩潰,只要做好了持久化工作,在下次重新上電時,數據還是會持久化在內存中。優勢就是內存數據的快速恢復。現實生活中,像線上服務,如果節點離線,數據要從外存或者從網絡中重新拉回來做內存數據的構建,這非常影響線上服務質量。因為線上服務不允許長時間離線,若用持久內存,它就會持久化。在掉線以后,該線上節點恢復。基于此,對現在傳統軟件最大挑戰是需要做持久化編程模型。
總而言之,分級存儲架構和內存數據持久化,需要做一些傳統軟件的系統優化。
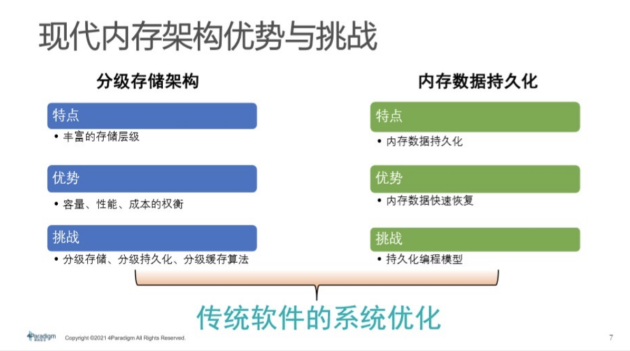
PMem在學術界非常火熱,今年在丹麥舉行的國際頂級數據庫學術會議VLDB就有兩個專門收錄PMem相關論文的research sessions,共有8篇paper,出現了井噴。這些paper有工業界的影子,例如第一篇論文是做SSD的廠商。從工業界的角度來看,加之英特爾的推介,包括像第四范式、阿里巴巴也在做積極探索。在工業界,在接下來的1-2年內,PMem會普遍進入數據中心采購名單,會迎來非常大規模應用熱潮。
6第四范式在現代存儲架構上一些技術實踐
對內:面向AI流程的優化。這里有兩種用法:Memory Mode(為了低成本擴容)和HyperPS(針對推理的參數服務器)。
對外:除了對內部產品優化,也開始對外開源,目的是把核心技術往外推,讓更多企業開發者能夠意識到異構多級存儲、現代存儲架構上帶來的優化工作,也可以推進持久內存的普及。
對內+對外:(已開源工作)。VLDB 2021:主要是針對特征工程數據庫,做基于PMem的優化,核心持久化跳表即將合入PMDK核心庫,這在國內是領先的。基于Pafka的Kafka優化:10x性能提升,且無需修改代碼。還有一些打算開源、正在開發中的工作,例如OpenEmbedding,就是針對訓練的參數服務器,它是和TensorFlow整合,方便快捷,包括向量、Elasticsearch、PMemStore、OpenMLDB,OpenMLDB就是已經開源的特征工程數據庫。這兩者整合起來,會在明年進行開源。另一方面,第四范式和英特爾也在打造代化存儲架構的技術社區MemArk。

7面向AI全流程的異構存儲優化
從第四范式的產品角度看,主要包含了離線訓練和在線推理。在離線訓練中,對內存消耗量會特別高,所以會做低成本擴容工作,使用PMem做內存擴容。在線推理中,因為它對性能要求高,有持久化需求,所以會用AD Mode在參數服務器、特征功能數據庫、消息隊列方面去做優化。
PMem具體如何使用?其實是取決于實際情況去做優化。
二、特征工程數據庫在PMem上的優化
下圖講了特征工程數據庫用在哪里。
從第四范式的角度,它大部分用于決策場景。例如,反欺詐、反洗錢以及推薦系統。
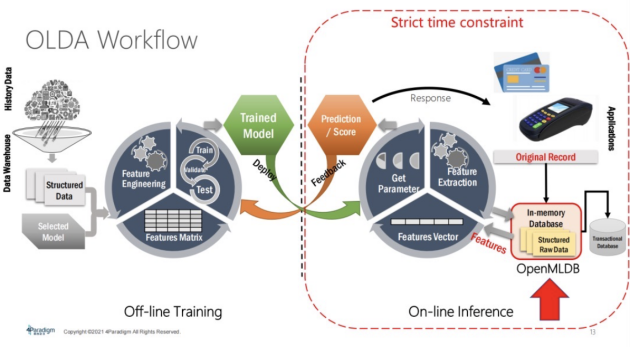
如下圖,左邊是Off-line Training,右邊是On-line Inference。那么Off-line Training的特征在哪里?其實就在這OpenMLDB, 當在線請求產生一條數據記錄時,它就會去做一個實時的特征抽取,產生額外的有用的特征,然后這個特征抽取會為 On-line Inference系統去做模型推理,所以它是在線場景下關鍵組件。因為它是在線系統,所以它有強的時間限制,延時不能太高。在此,我們更關注于OpenMLDB怎么去做性能優化以及做持久內存優化。
接下來著重介紹什么是特征(features)。特征在決策類場景中非常重要,一般從在線請求中產生的數據并不能直接去用來做推理,而是需要進一步做特征抽取。例如,我們需要拿到當前交易產生之前10秒、1分鐘、5分鐘內產生的交易做多的商店信息,這些都是通過實時的特征抽取拿到的而不能提前計算出來。所以這些基于時間窗口的實時特征抽取,就是在線特征工程。
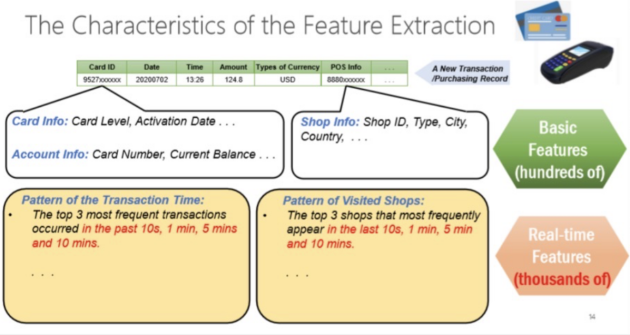
Future Extraction會有挑戰:
第一,它大部分的特征不能被提前算好,例如一個交易,要算當前這個點往前推的時間窗口里面的信息,可能一分鐘或者一小時或者幾天的時間信息。這跟當前發生的時間狀態是有關系的,所以不能去做提前處理。
第二,特征抽取會基于很多個時間窗口,計算量會比較高。
第三,此時會有很多特征產生,為了做在線推理,傳統商業數據庫并不能滿足需求,一個是隨著時間窗口的增長,Latency會增長得非常快,那么它性能很快就會超過幾十個milliseconds,這可能會影響到線上服務質量,這種情況下它就不符合線上服務需求。
綜上所述,我們需要去開發一個專門面向人工智能決策場景的特征工程數據庫。

在這個大背景下,對于第四范式而言,OpenMLDB的設計包含兩方面:第一,它提供FEQL引擎,FEQL引擎提供了FEQL語法,FEQL語法類似于SQL-like language。但是它可以更好地支持,比如基于時間窗口的特征抽取。第二,從存儲引擎角度來講,使用了雙層跳表結構,去支持專門為時間窗口查詢來做一些優化。
FEQL語法與SQL基本相似。除了有如Time_Window比較特殊的、專門給時間窗口查詢做的語法,也會針對此類語法做優化。
底層的存儲引擎結構是雙層的 Skiplist。
基于這些優化,OpenMLDB它本身相比較于其他的database,就具有非常大的性能優勢。同樣與前面的DB-X、DB-Y相比,性能優勢非常大,它性能上的 Latency,延遲能符合線上服務的需求。
基于OpenMLDB,我們DRAM版本的OpenMLDB也看到兩大痛點:
第一,是因為OpenMLDB是為了線上推理用的,線上推理為了達到高性能的一般數據和索引都會放在內存當中,為了能夠及時響應,這對內存需求會特別高。運用一個實際的銀行反欺詐業務場景,這里只有三個月的數據量,該數據可能需要占用10TB,如果用普通DRAM去搭建,成本很高。而且部分客戶反映,他們并不是為了性能而去擴展設備數量、機器資源,而只是為了能兜住內存容量,他們需要配備可能十幾臺機器,才能去兜住OpenMLDB。
第二,OpenMLDB都有把 data通過snapshot或者binlog這種方式,也就是Sync到磁盤、外部存儲,去做數據備份。那么當這個操作發生時,它就會對延遲性能帶來很大影響。因為大部分操作都會在內存中,但是當 Sync操作發生時,就會涉及到磁盤,由此產生長尾的延遲效應。
OpenMLDB是為了在線服務所設計的,需要保證線上服務質量,不允許線上的節點過長時間離線。在這種背景下,如果節點離線,則需要從網絡磁盤中去重新拉回來去構建內存數據,由此恢復的時間會比較長。
因此,在該種情況下需要用PMem優化OpenMLDB。
PMem的用法有多種:數據和 index放在DRAM,log Snapshot存在外存。其中最簡單的用法是把PMem當成memory mode,這種用法可以通過大容量解決成本問題,但無法享受內存數據持久化帶來的快速恢復優勢。
所以需要進一步通過AD mode做OpenMLDB優化,在這種優化情況下,整個系統數據庫架構將發生改變,DRAM版本的OpenMLDB,需要將log Snapshot持久化到外部存儲上。
在這種模式下,由于整個內存具有持久化功能,所以不需要將數據持久化到外存上。內部的Skiplist跳表數據結構具有持久化功能,數據會整體持久化在內存中。
顯然,這有諸多優勢,第一,沒有 Sync的過程。第二,掉電后數據會立即從內存中恢復,無需漫長的時間恢復。
然而,這會遇到一個問題:如何保證持久化、語義的正確性和高效性。
其中最主要問題就是做Compare-And-Swap操作,在很多系統中去做無鎖的并發情況,其實在 OpenMLDB里面也應用。在PMem環境下,CAS操作其實并不具有持久化語義。在多線程情況下,它會對Data inconsitency造成問題。
舉個例子,第一個Thread進行Compare-And-Swap操作,第二個Thread基于計算出來的 t值做特征工程計算,然后把計算出來的特征進行flush。t1的值本來也應該被flush到 PMem,但可能在這個點掉電或者程序崩潰。在這種情況下,f1計算出來的特征被刷到了持久內存當中,然而原來的數據t1反而沒有,這就造成了data inconsistency。
為了解決Compare-And-Swap問題,提出了Persistent-Compare-And-Swap。解決的思路是進行flush on read操作,每次做read時都去做持久化操作,能從根本上解決正確性問題。但是它會引入比較大的overhead,因為對每一個read都進行flush顯然不對,某些read根本無需這樣做。
在此情況下,本文引入smart pointer技術,即智能指針。在x86的架構上,內存地址要求八字節對齊,指針所指向的地址的最后三位一直是0。將三位的最后一位作為dirty的 flag,用于標記數據是否已被flush,如果已被flush,就無需再做 flush操作。基于該技術,可以做 persistent 操作,同時避免無效的、多余的、多次的flush持久化操作。
對于FEDB,本文使用真實的銀行反欺詐數據,數據共有10TB,這里是一些優化過的不同版本。(在Paper里面稱FEDB,開源以后叫open MLDB,所以表格里還是FEDB。)
首先,從性能角度來看,相較于這些傳統的這種數據庫,不管是DRAM版本的FEDB還是PMem版本的FEDB,都會達到相當好的性能。
基于 PMem版本優化有諸多優勢:
一是long tail latency方面。黃色柱子和藍色柱子分別代表了DRAM版本和典型的PMem版本,在 TP-99999標準下的long tail latency,大概有20%的性能改進。
二是 recovery time方面。基于DRAM需要6個小時才能完成一個完整的鏡像恢復,但如果基于內存做持久化OpenMLDB,只需一分鐘就能從內存重新恢復。其次,從CPU的角度來看,節省了一半左右的成本投入。
三、基于分級存儲架構的Kafka優化
Kafka廣泛用于大數據處理、人工智能,主要用于消息傳輸日志的搜集。Kafka架構具有高性能、高可擴展、高可用的特性。然而,由于它的logo文件需要做持久化,所以當壓力上來時,無論是latency還是super都會受限于存儲設備。
Pafka是Kafka的優化版本,Pafka版本在存儲方面進行了優化。首先,由于整體上基于Kafka架構,所以客戶業務代碼是零遷移成本,他們無需做任何改造,即可零成本遷移到Kafka平臺上,使用持久內存的Pafka可當做持久設備。它可打破性能瓶頸,在成本和性能上都有大幅度的提升。
從具體實現角度來講,本來是通過這個文件 channel去存儲到外部存儲HDD或者SSD上,現在是通過PMDK將Kafka的 broker和 SEGMENT的存儲,,將它賦能為可存儲在PMem上。
在此,引入 MixChannel的概念,它不僅可存儲在單一介質,還可以存儲在PMem或者存儲在第二級的外存上。例如,考慮到PMem的容量比較小,可以同時用 PMem和SSD或者HDD。
怎樣把容量都用起來,保證一定的性能優勢?在此引入分級存儲的概念,然后引入數據遷移策略,將冷熱數據分開存儲,希望大部分熱數據的讀寫能落到PMem上,冷數據落到速度比較慢的存儲設備上。這個特性會在0.2.0版本中引入,在這個月底或者下個月初發布。現在的0.1.1版本全部存在PMem上。
0.1.1版本使用PMem做整個Kafka的性能兜底,是性能優化的表現。相比于 HDD或者SSD,它具有非常大的性能優勢,例如SATA SSD,可以達到將近20倍的性能改善。
Pafka工作是下半年的重點工作,目前0.1.1版本已經開源,可以去試用,包括跟其他partner的合作,也已開始測試性能。0.1.1版本引入了PMem作為持久化介質,但并沒有真正引入分級存儲的概念。在0.2.0版本,會引入分級存儲和數據遷移機制,能夠在性能和容量上達到權衡,希望在數據量要求比較大的場景下,也能達到加速效果。
四、MenArk社區
該社區由第四范式主導創立,英特爾是贊助者之一。MenArk社區主要關注先進的存儲架構技術,基于現代化存儲架構為一些流行的開源軟件做系統性優化。例如,Kafka、數據庫系統、社區,將來都會去做優化工作。MenArk社區是一個開放性社區,歡迎合作伙伴的加入。同時,在此可以查看開源項目,主要包括:Kafka、OpenMLDB、PMems。