比可微架構搜索DARTS快10倍,第四范式提出優化NAS算法
神經架構搜索一直被認為是高算力的代表,盡管可微架構搜索的概念非常吸引人,但它目前的效率與效果仍然不盡人意。在最近的 AAAI 2020 中,第四范式提出了一種基于臨近迭代(Proximal Iterations)的 NAS 方法,其速度比 DARTS 快了 10 倍以上。
神經架構搜索(NAS)因其比手工構建的架構更能識別出更好的架構而備受關注。近年來,可微分的搜索方法因可以在數天內獲得高性能的 NAS 而成為研究熱點。然而,由于超級網的建設,其仍然面臨著巨大的計算成本和性能低下的問題。
在本文中,我們提出了一種基于近端迭代(NASP)的高效 NAS 方法。與以往的工作不同,NASP 將搜索過程重新定義為具有離散約束的優化問題和模型復雜度的正則化器。由于新的目標是難以解決的,我們進一步提出了一種高效的算法,由近端啟發法進行優化。
通過這種方式,NASP 不僅比現有的可微分的搜索方法速度快,而且還可以找到更好的體系結構并平衡模型復雜度。最終,通過不同任務的大量實驗表明,NASP 在測試精度和計算效率上均能獲得更好的性能,在發現更好的模型結構的同時,速度比 DARTS 等現有技術快 10 倍以上。此外,NASP 消除了操作之間的關聯性。
- 論文:https://arxiv.org/abs/1905.13577
- 代碼:https://github.com/xujinfan/NASP-codes
此外,在 WWW 2020 的論文」Efficient Neural Interaction Functions Search for Collaborative Filtering」中,我們將 NASP 算法應用到了推薦系統領域:
- 視頻:https://www.tuijianxitong.cn/cn/school/video/26
- PPT:https://www.tuijianxitong.cn/cn/school/openclass/27
- 論文:https://arxiv.org/pdf/1906.12091
- 代碼:https://github.com/quanmingyao/SIF
走向極速的神經架構搜索
深度網絡已經應用到許多應用中,其中,適當的體系結構對于確保良好的性能至關重要。近年來,NAS 因可以找到參數更少、性能更好的網絡成為了關注和研究的熱點,該方法可取代設計架構的人類專家。
NASNet 是這方面的先驅性工作,它將卷積神經網絡(CNN)的設計為一個多步驟決策問題,并用強化學習來解決。
然而,由于搜索空間離散且巨大,NASNet 需要數百個 GPU 耗費一個月的時間,才能獲得一個令人滿意的網絡結構。后來,通過觀察網絡從小到大的良好傳輸性,NASNetA)提議將網絡分割成塊,并在塊或單元內進行搜索。然后,識別出的單元被用作構建塊來組裝大型網絡。這種兩階段的搜索策略極大地減小了搜索空間的大小,從而使進化算法、貪心算法、強化學習等搜索算法顯著加速。
盡管減少了搜索空間,但搜索空間仍然是離散的,通常很難有效搜索。最近的研究集中在如何將搜索空間從離散的變為可微分。這種思想的優點在于可微空間可以計算梯度信息,從而加快優化算法的收斂速度。
該思想已經衍生出了各種技術,例如 DARTS 平滑了 Softmax 的設計選擇,并訓練了一組網絡;SNAS 通過平滑抽樣方案加強強化學習。NAO 使用自動編碼器將搜索空間映射到新的可微空間。

在所有這些工作中(Table 1),最為出色的是 DARTS [1],因為它結合了可微分以及小搜索空間兩者的優點,實現了單元內的快速梯度下降。然而,其搜索效率和識別體系結構的性能仍然不夠令人滿意。
由于它在搜索過程中保持超級網,從計算的角度來看,所有操作都需要在梯度下降過程中向前和向后傳播。從性能的角度來看,操作通常是相互關聯的。例如,7x7 的卷積濾波器可以作為特例覆蓋 3x3 的濾波器。當更新網絡權值時,由 DARTS 構造的 ensemble 可能會導致發現劣質的體系結構。
此外,DARTS 最終的結構需要在搜索后重新確定。這會導致搜索的體系結構和最終體系結構之間存在偏差,并可能導致最終體系結構的性能下降。
更快更強的臨近迭代
在此次工作中,第四范式提出了基于臨近迭代算子算法(Proximal gradient Algorithm [2])的 NAS 方法(NASP),以提高現有的可微搜索方法的效率和性能。我們給出了一個新的 NAS 問題的公式和優化算法,它允許在可微空間中搜索,同時保持離散的結構。這樣,NASP 就不再需要訓練一個超級網,從而加快搜索速度,從而產生更優的網絡結構。
該工作的貢獻在于:
- 除了以往 NAS 普遍討論的搜索空間、完備性和模型復雜度之外,該工作確定了一個全新且重要的一個因素,即 NAS 對體系結構的約束;
- 我們將 NAS 描述為一個約束優化問題,保持空間可微,但強制架構在搜索過程中是離散的,即在反向梯度傳播的時候盡量維持少量激活的操作。這有助于提高搜索效率并在訓練過程中分離不同的操作。正則化器也被引入到新目標中,從而控制網絡結構的大小;
- 由于這種離散約束難以優化,且無法應用簡單的 DARTS 自適應。因此,第四范式提出了一種由近端迭代衍生的新優化算法,并且消除了 DARTS 所需的昂貴二階近似,為保證算法的收斂性,我們更進一步進行了理論分析。
- 最后,在設計 CNN 和 RNN 架構時,使用各種基準數據集進行了實驗。與最先進的方法相比,提出的 NASP 不僅速度快(比 DARTS 快 10 倍以上),而且可以發現更好的模型結構。實驗結果表明,NASP 在測試精度和計算效率上均能獲得更好的性能。
具體算法如下:
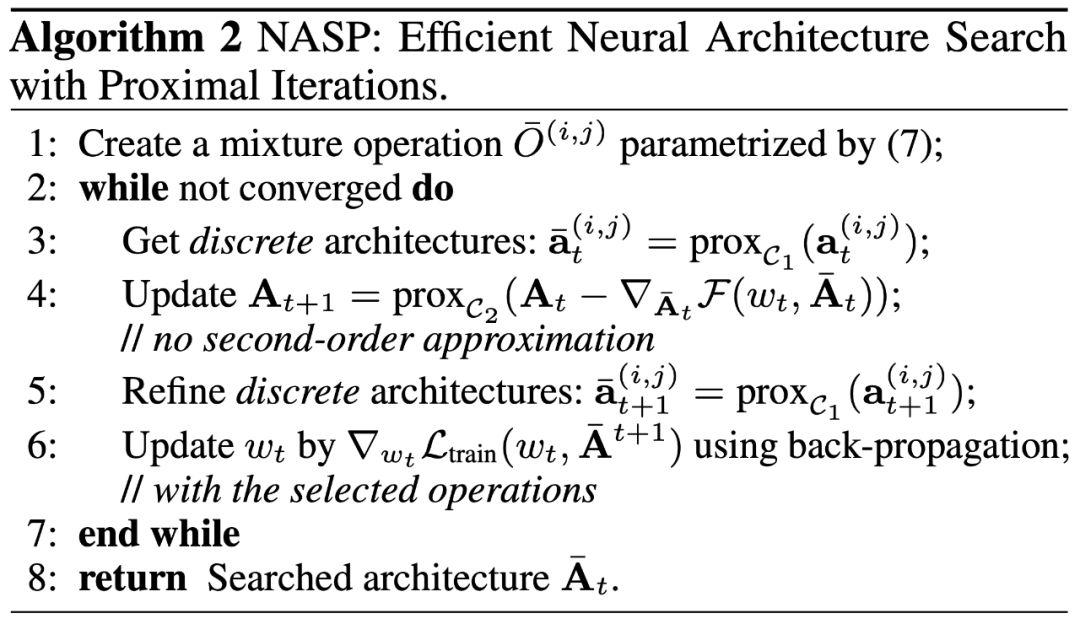
在第三步中,我們利用臨近迭代算子產生離散結構;再在第四步中更新連續的結構參數(單步梯度下降,無二階近似);最后,我們在離散的網絡結構下,更新網絡權重。
實驗結果
該工作利用搜索 CNN 和 RNN 結構來進行實驗。此次試驗使用 CIFAR-10、ImageNet、PTB、WT2 等四個數據集。
CNN 的架構搜索
1. 在 CIFAR-10 上搜索單元
在 CIFAR-10 上搜索架構相同,卷積單元由 N=7 個節點組成,通過對單元進行 8 次疊加獲得網絡;在搜索過程中,我們訓練了一個由 8 個單元疊加的 50 個周期的小網絡。這里考慮兩個不同的搜索空間。第一個與 DARTS 相同,包含 7 個操作。第二個更大,包含 12 個操作。
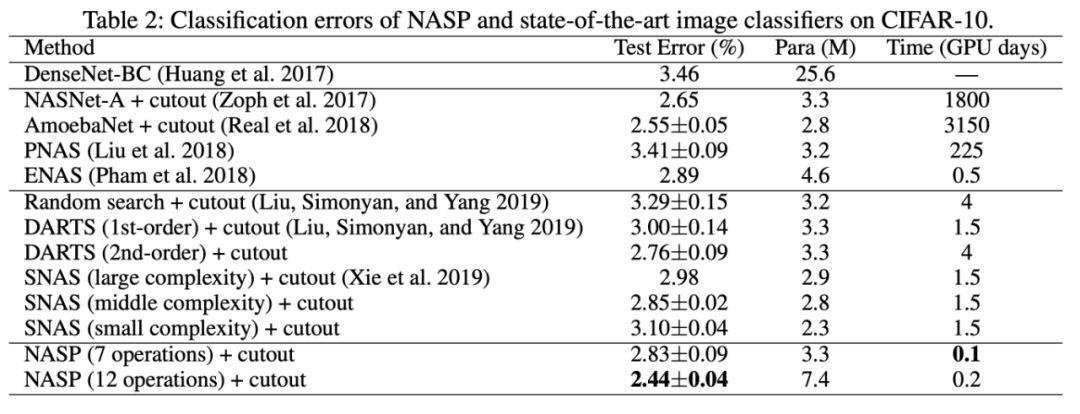
與最新的 NAS 方法相比,在相同的空間(7 次操作)中,NASP 的性能與 DARTS(二階)相當,比 DARTS(一階)好得多。在更大的空間(12 個操作)中,NASP 仍然比 DARTS 快很多,測試誤差比其他方法更低很多。
在以上實驗中,研究人員對模型復雜度進行了正則化,我們設置了的η=0。結果顯示,模型尺寸隨著η的增大而變小。
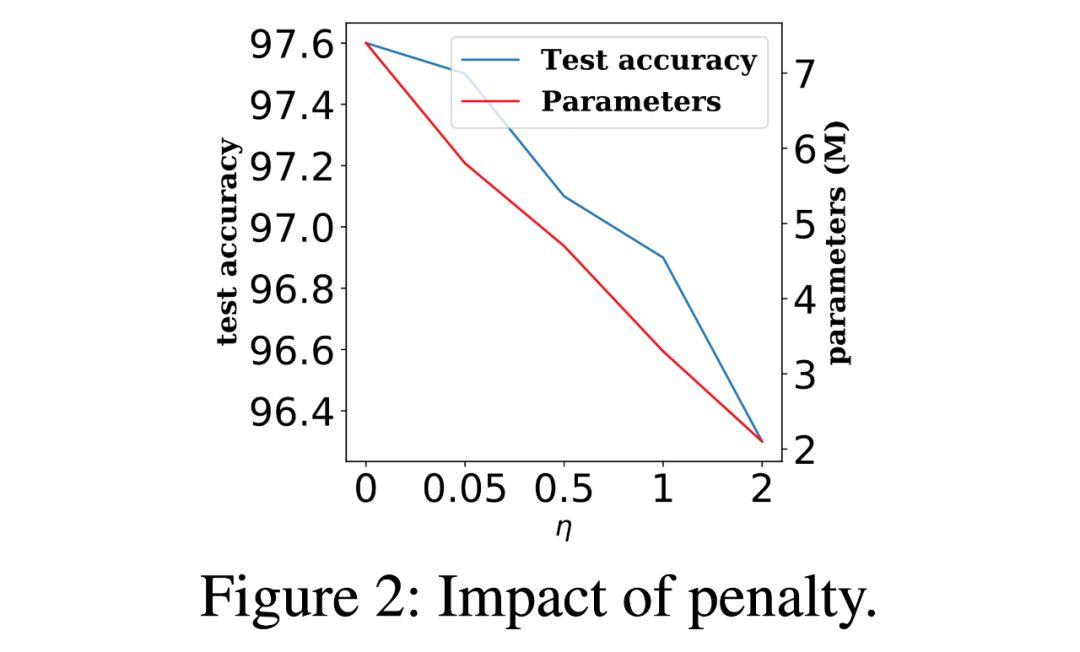
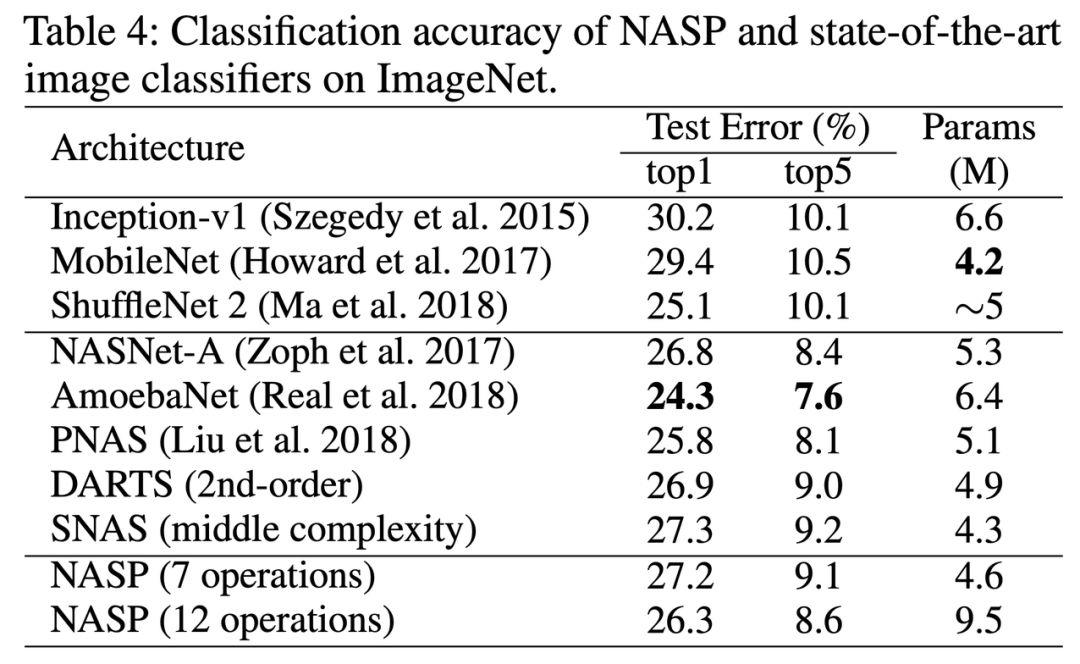
2.遷移到 ImageNet
為了探索實驗中搜索到的單元在 ImageNet 上的遷移能力,我們將搜索到的單元堆疊了 14 次。值得注意的是,NASP 可以用最先進的方法實現競爭性測試誤差。
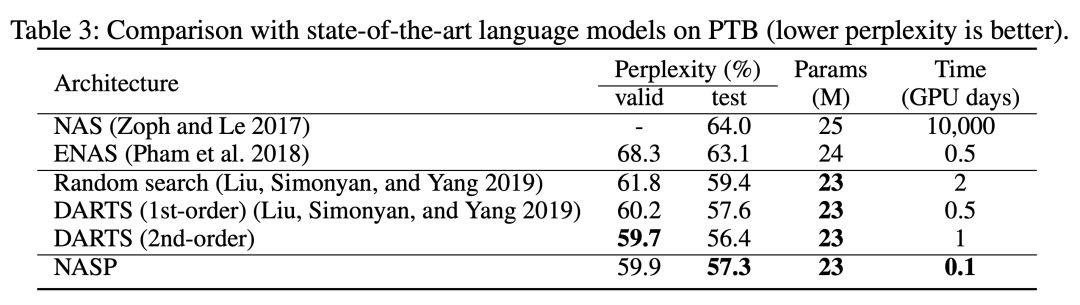
RNN 的架構搜索
1. 在 PTB 上搜索單元
根據 DARTS 的設置,遞歸單元由 N=12 個節點組成;第一個中間節點通過線性變換兩個輸入節點,將結果相加,然后通過 tanh 激活函數得到;第一個中間節點的結果應為由激活函數轉換而成。
在搜索過程中,我們訓練了一個序列長度為 35 的 50 個階段的小網絡。為了評估在 PTB 上搜索到單元的性能,使用所發現的單元對單層遞歸網絡進行最多 8000 個階段的訓練,直到與批處理大小 64 收斂。實驗結果顯示,DARTS 的二階比一階慢得多,NASP 不僅比 DARTS 快得多,而且可以達到與其他最先進的方法相當的測試性能。
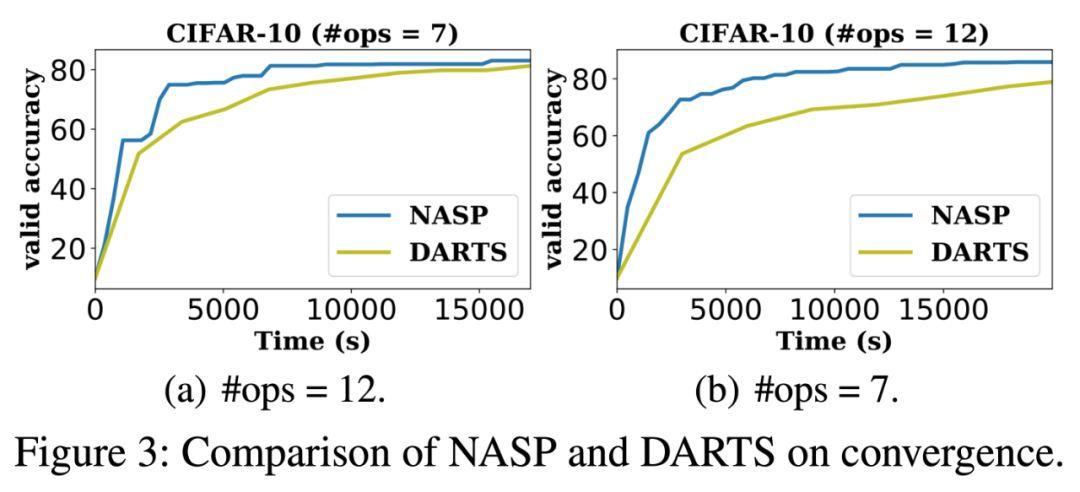
模型簡化測試
1. 對比 DARTS
實驗給出了更新網絡參數(即 w)和架構(即 A)的詳細比較。在相同的搜索時間內,NASP 可以獲得更高的精度,且 NASP 在相同的精度下花費更少的時間。這進一步驗證了 NASP 比 DARTS 效率更高。
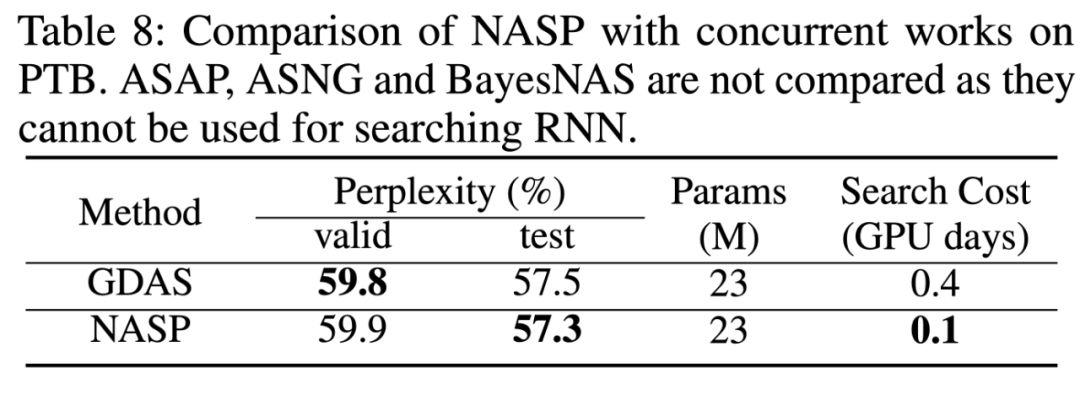
2. 與同期工作比較
實驗中也加入了與同期工作的比較。ASAP 與 BayesNAS 將 NAS 作為一個網絡修剪問題,該工作刪除了在搜索過程中無效的操作。ASNG 和 GDAS 都對搜索空間進行隨機松弛,區別在于 ASNG 使用自然梯度下降進行優化,而 GDAS 使用 Gumbel-Max 技巧進行梯度下降。此次實驗將 NASP 與這些工作進行比較,實驗表明,NASP 更有效,可在 CNN 任務上提供更好的性能。此外,NASP 還可以應用于 RNN。

[1]. Liu, H.; Simonyan, K.; and Yang, Y. DARTS: Differentiable architecture search. In ICLR 2019
[2]. Parikh, N., and Boyd, S. Proximal algorithms. Foundations and Trends in Optimization 2013