













多表關聯查詢過濾條件寫在On與Where后的區別
本文轉載自微信公眾號「數據和云」,作者于志軍 。轉載本文請聯系數據和云公眾號。
SQL優化過程中,發現開發人員在寫多表關聯查詢的時候,對于謂詞過濾條件的寫法很隨意,寫在on后面與where后面的情況均有,這可能會導致沒有理解清楚其真正的含義而無法得到期望的結果。
多表關聯連接方式有inner join、left join、right join、full join四種,下面通過實驗來說明不同連接方式謂詞放在on與where后的效果與影響。
初始化測試數據
- create table t1(id number(10),name varchar2(30),status varchar2(2));
- create table t2(id number(10),mobile varchar2(30));
- insert into t1 values(1,'a','1');
- insert into t1 values(2,'b','1');
- insert into t1 values(3,'c','1');
- insert into t1 values(4,'d','1');
- insert into t1 values(5,'e','1');
- insert into t1 values(6,'f','0');
- insert into t1 values(7,'g','0');
- insert into t1 values(8,'h','0');
- insert into t1 values(9,'i','0');
- insert into t1 values(10,'j','0');
- insert into t2 values(1,'12345');
- insert into t2 values(2,'23456');
- insert into t2 values(3,'34567');
- insert into t2 values(6,'67890');
- insert into t2 values(7,'78901');
1.Inner join
SQL>select * from t1 inner join t2 on t1.id=t2.id and t1.status=‘1’;
- ID NAME ST ID MOBILE
- 1 a 1 1 12345
- 2 b 1 2 23456
- 3 c 1 3 34567
SQL> select * from t1 inner join t2 on t1.id=t2.id where t1.status=‘1’;
- ID NAME ST ID MOBILE
- 1 a 1 1 12345
- 2 b 1 2 23456
- 3 c 1 3 34567
我們發現謂詞t1.status=’1’放在on后與where后結果一樣,它們的執行計劃相同,說明CBO對這兩種情況做了相同處理。
執行計劃如下圖所示:
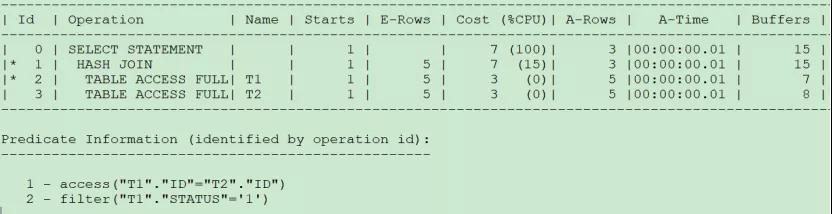
Inner join時謂詞不管放在哪個位置,CBO都先對t1表過濾,再與t2表關聯。
2.left join
(1)左右表謂詞過濾都放在on后面:
SQL> select * from t1 left join t2 on t1.id=t2.id and t1.status=‘1’ and t2.id<3;
- ID NAME ST ID MOBILE
- 1 a 1 1 12345
- 2 b 1 2 23456
- 3 c 1
- 8 h 0
- 5 e 1
- 9 i 0
- 10 j 0
- 7 g 0
- 6 f 0
- 4 d 1
執行計劃如下:
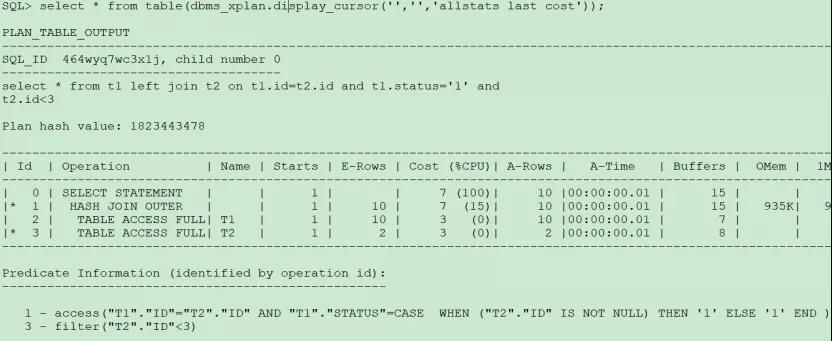
從執行計劃可以看出,t1.status=’1’放在on后面,t1表并沒有對謂詞status進行過濾,結果集顯示t1的全表數據。這是由left join的特性決定的,左表會顯示全部數據。t2.id<3是先對t2表進行過濾再進行連接,而t1.status=’1’是作為連接條件存在,對連接時產生的笛卡爾積數據做連接過濾。
(2)左右表謂詞過濾都放在where后面:
SQL>select * from t1 left join t2 on t1.id=t2.id where t1.status=‘1’ and t2.id<3;
- ID NAME ST ID MOBILE
- 1 a 1 1 12345
- 2 b 1 2 23456
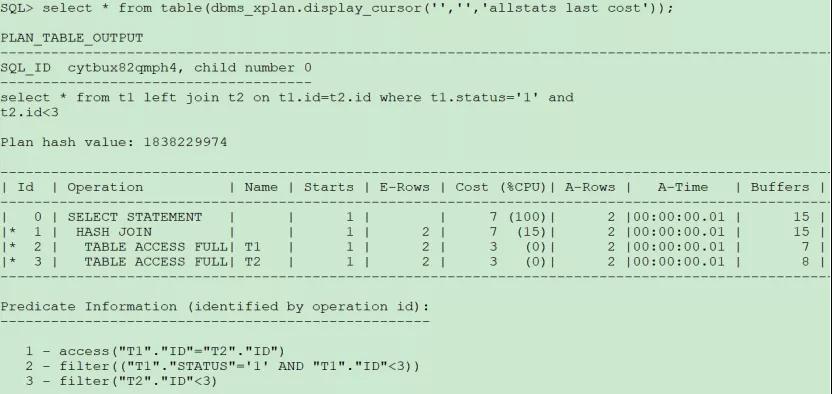
從執行計劃可以看出,謂詞放在where后面,是先對表進行過濾,然后再對過濾后的數據進行連接。而且我們發現t1表上自動加上了id<3的過濾條件,這是因為有t1.id=t2.id等值連接,如果t1表上id列有索引,性能就能看出差別來了。注意連接方式變成了hash join,這是因為右表的謂詞過濾條件寫在where后面,CBO會把左連接等價為內連接。
(3)右表的謂詞寫在on后面,左表的謂詞寫在where后面:
SQL>select * from t1 left join t2 on t1.id=t2.id and t2.id<3
where t1.status=‘1’; 2
- ID NAME ST ID MOBILE
- 1 a 1 1 12345
- 2 b 1 2 23456
- 5 e 1
- 4 d 1
- 3 c 1
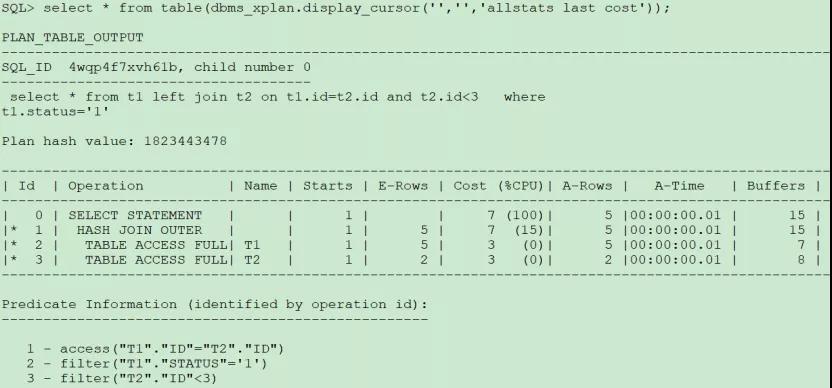
當把對右表的過濾寫在on后面,先對兩表進行過濾,再進行left join,顯示結果集與寫在where后面是不同的,連接方式還是左外連接,顯示t1過濾后的全部數據。
(4)右表的謂詞寫在where后面,左表的謂詞寫在on后面:
SQL> select * from t1 left join t2 on t1.id=t2.id and t1.status=‘1’ where t2.id<7;
- ID NAME ST ID MOBILE
- 1 a 1 1 12345
- 2 b 1 2 23456
- 3 c 1 3 34567
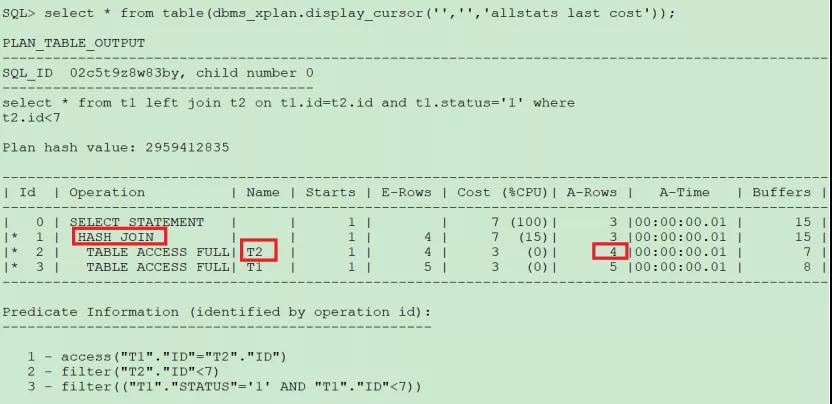
從執行計劃看這種情況左連接轉換為內連接,左表的謂詞條件寫在哪個位置都一樣。而且因為t2表過濾后數據比t1表少,CBO把t2表當成了驅動表。
接下來我們再看一個語句:
SQL> select * from t1 left join t2 on t1.id=t2.id and t1.status=‘1’
where t1.status=‘0’ ;
- ID NAME ST ID MOBILE
- 8 h 0
- 6 f 0
- 9 i 0
- 10 j 0
- 7 g 0
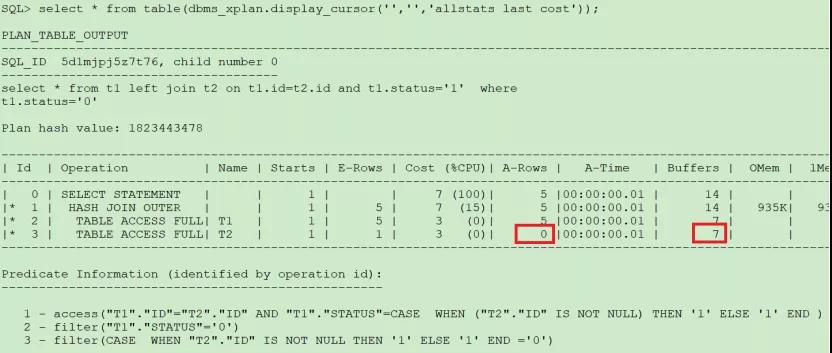
從執行計劃看出,雖然t2表返回0行,步驟3上的filter條件肯定不成立,但有邏輯讀消耗,所以推斷它依然進行了全表掃描,所以這種語句對t2表的掃描是對資源的一種浪費,沒有意義。或許你會覺得誰會這么無聊寫這種SQL,但是在開發過程中,SQL語句經常是各種過濾條件組合經過拼接而成,因為返回結果是對的,他們意識不到會出現這種問題,在此說明此種情況主要是想說明一件事:不要總想著用一個語句來解決所有的功能需求,適當的拆分對性能的提升是很有必要的。
3.right join
右連接與左連接是相似的,只不過是右表顯示全部數據,寫在on后面謂詞過濾對右表不起作用,在此不再舉例說明。
4.full join
全連接在應用中似乎很少碰到,但是存在即合理,只是自己沒有遇到而已。
(1)兩個表的謂詞都放在on的后面:
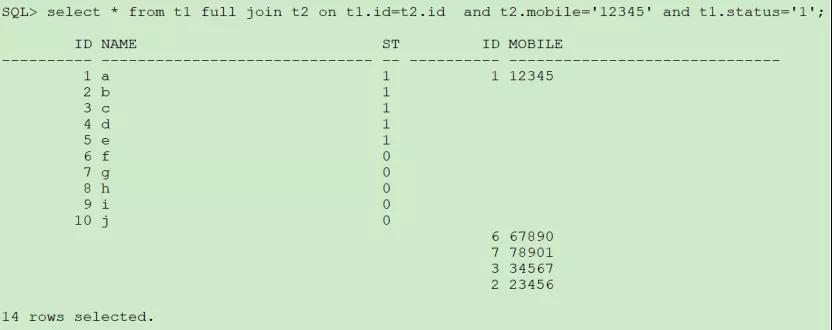
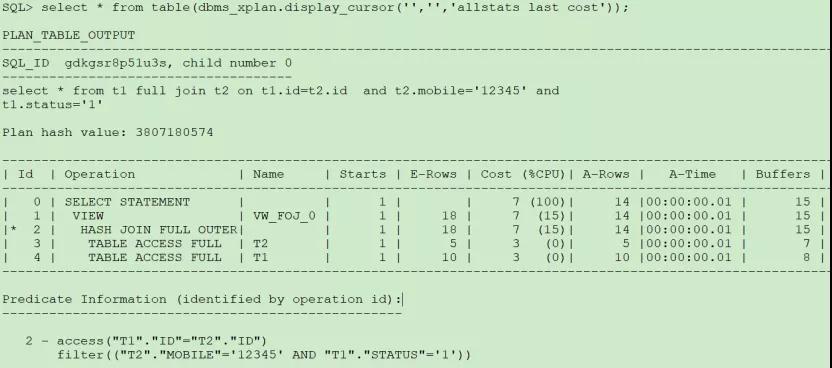
這種情況不會先對兩個表過濾,而是作為連接條件過濾,符合連接就匹配上,不符合的就把左右兩表的數據都顯示出來,另一表的字段以空顯示。
(2)兩個表的謂詞都放在where后面:
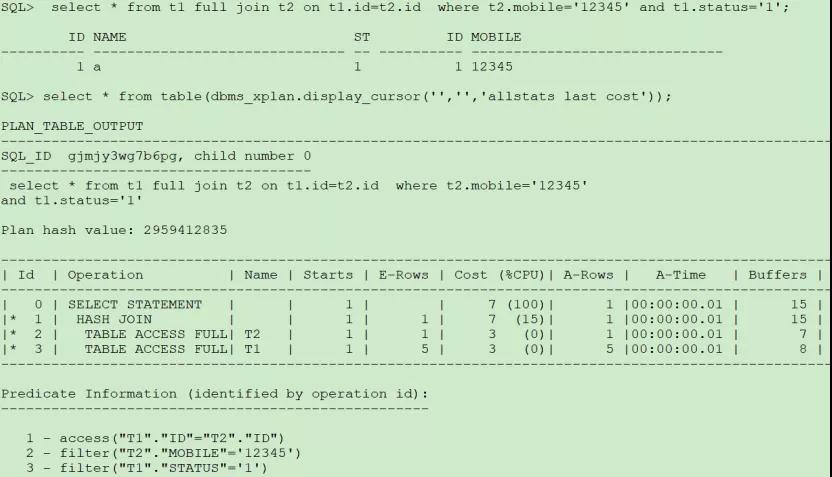
這種情況CBO將其轉換為內連接,先過濾再關聯。
(3)左表謂詞放在on后面,右表放在where后面:
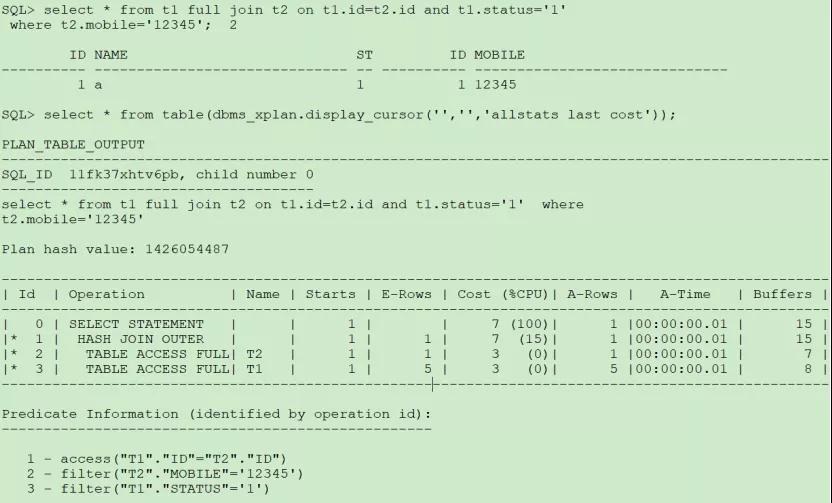
這種情況轉換為右外連接,但是也是先對兩表過濾后再關聯。
(4)左表謂詞放在where后面,右表放在on后面:
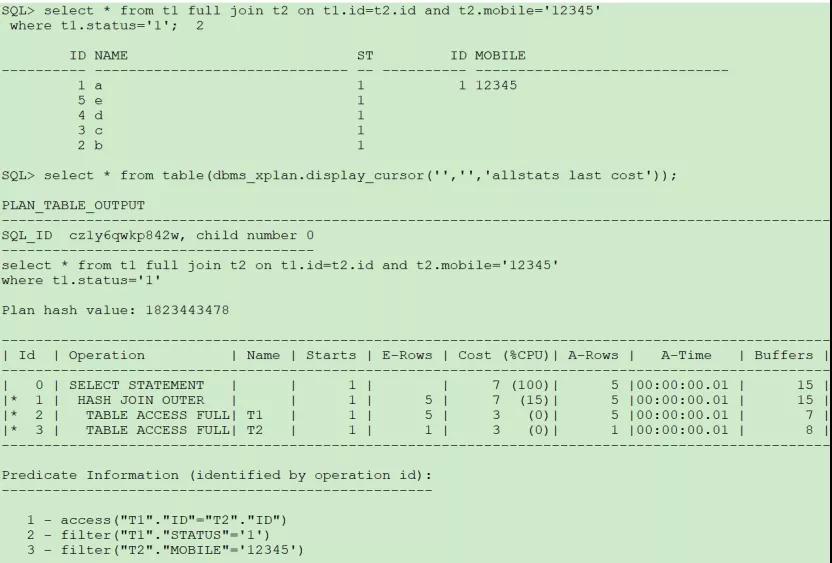
這種情況轉換為左外連接,也是先對兩表過濾后再關聯。
總結
1.對于內連接inner join,兩個表的謂詞條件放在on與where后面相同。
2.對于left join:
左表謂詞放在on后不會對左表數據進行過濾,依然顯示左表全部數據,放在where后面才會對左表進行過濾
右表謂詞不管放在on后還是where后都會對右表先過濾再連接,但是放在where后left join會轉換為inner join。
3.對于外連接,謂詞條件放的位置不同,結果集也不同,可以根據自己的需求斟酌使用。
關于作者
于志軍,云和恩墨技術顧問,Oracle 12c OCM。擁有OCM、OBCA證書,曾在某大型國企做過多年數據庫運維工作,現駐場于某銀行,專門從事SQL性能優化工作,熱衷于運維故障處理、備份恢復、升級遷移、性能優化的學習與分享。



















