EMR on ACK 全新發布,助力企業高效構建大數據平臺
阿里云 EMR on ACK 為用戶提供了全新的構建大數據平臺的方式,用戶可以將開源大數據服務部署在阿里云容器服務(ACK)上。利用 ACK 在服務部署和對高性能可伸縮的容器應用管理的能力優勢,用戶只需要專注在大數據作業本身。用戶可以便捷地將 Spark、Presto、Flink 作業執行在 ACK 集群上,100%兼容開源,性能優于開源。
一、背景介紹
技術趨勢
存儲與計算分離,向云原生演進
在線業務、AI、大數據統一接入 ACK 集群,錯峰調度,離線在線混部,提升機器利用率
統一運維入口,統一運維工具鏈,統一監控體系
以集群為中心->以作業為中心
多版本支持,例如可以同時跑 Spark2.x、Spark3.x
云原生面臨挑戰
計算與存儲分離:如何構建以對象存儲 OSS 為底座的 HCFS 文件系統
需要完全兼容現有的 HDFS
性能對標 HDFS,成本降低
計算引擎 shuffle 數據存算分離:如何解決 ACK 混合異構機型
異構機型沒有本地盤
社區[ Spark-25299]討論,支持 Spark 動態資源,成為業界共識
ACK 調度能力:如何解決調度性能瓶頸
性能對標 Yarn
多級隊列管理
錯峰調度
借助 K8s 操作系統能力,編排組織各種業務的波峰波谷
EMR on ACK 優勢
Remote Shuffle Service 提供中間 shuffle 數據的存儲計算分離方案
可以使計算節點無需本地盤和云盤
支持打開 Spark 動態資源功能,Spark-25299 終極方案
JindoFS 針對 OSS 存儲提供湖加速解決方案
Block 模式1TB TPCDS 場景下有15%以上的性能提升
調度層面支持 Scheduler Framework V2
調度性能比社區提升3x以上
提供多級隊列管理
引擎能力增強
10TB TPCDS Benchmark 場景下,EMR Spark 比社區有3x性能提升
Hudi、DeltaLake 比社區功能性能增強
完整的錯峰調度方案
二、EMR 容器化架構
EMR on ACK 架構
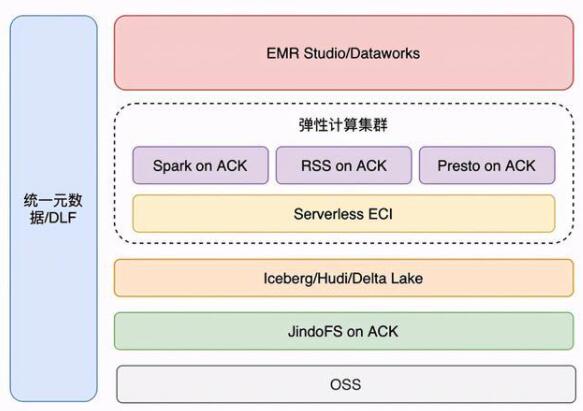
輕量化管控,對接已有數據平臺
通過數據開發集群/調度平臺提交到不同的執行平臺
錯峰調度,根據業務高峰低峰策略調整
云原生數據湖架構,ACK 彈性擴縮容能力強
ACK 管理異構機型集群,靈活性好
三、產品介紹
產品首頁
參考鏈接:https://www.aliyun.com/product/emapreduce

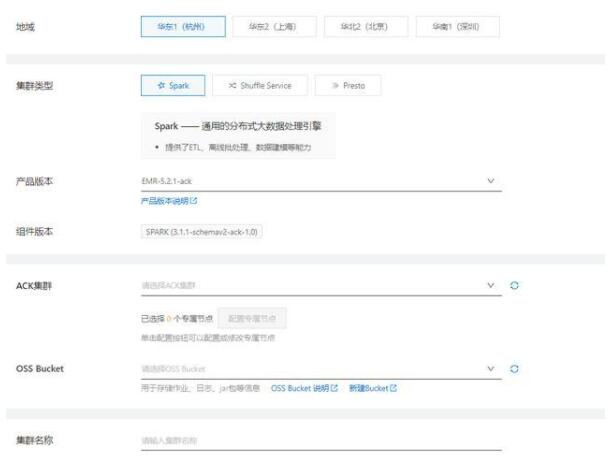
新建集群
地域:目前開放杭州、上海、北京、深圳等地域(持續開放中)
集群類型:Spark 、Shuffle Service、Presto
Spark — 通用的分布式大數據處理引擎
提供了 ETL、離線批處理、數據建模等能力
Shuffle Service — 針對 EMR 計算引擎提供優化的 Shuffle 服務
解決 Kubernetes 下對本地盤的依賴問題
解決大規模計算集群的網絡和磁盤的 IO 瓶頸
支持計算與存儲分離的架構,可服務多個 EMR 集群
Presto — 基于內存的分布式 SQL 交互式查詢引擎
支持多種數據源
適合 PB 級海量數據的復雜分析,以及跨數據源的查詢
組件版本:Spark (3.1.1)
專屬節點:
現有 ACK 集群,share 部分節點給到 EMR
新建 ACK 集群,可選擇整個集群為專屬節點
OSS Bucket:用于存儲作業、日志、jar 包等信息
集群管理
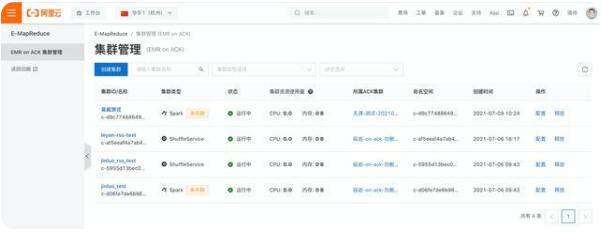
集群 ID/名稱:點擊進入作業管理
集群狀態:檢測集群是否可用
所屬 ACK 集群:可關聯到現有 ACK 集群
配置:Spark 作業配置
釋放:釋放空間